
SpringCloudStream(RabbitMQ&Kafka)&Spring-Kafka配置使用
是什么
屏蔽底层消息中间件的差异,降低切换成本,统一消息的编程模型(可理解为JDBC)
解决问题
每种消息中间件实现方式不同,对接也不同,如一开始对接了RabbitMQ,后期想改Kafka,那对接方面的代码会受到影响,所以,使用Stream可避免类似问题
使用方式
注:下面默认已经安装好RabbitMq环境
创建生产者项目
pom
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-bus-amqp</artifactId>
<version>2.2.3.RELEASE</version>
</dependency>
yml
server:
port: 8000
spring:
application:
name: producer
cloud:
stream:
binders: # 配置使用mq的信息;
myRabbit: #给Binder定义的名称,用于下方bindings -> binder
type: rabbit # 消息组件类型
environment: # mq环境配置
spring:
rabbitmq:
host: 192.168.1.2 #rabbitmq使用非localhost|127.0.0.1以外的帐号登录,需在管理页面创建新的帐号密码
port: 5672
username: admin
password: 123456
bindings: # 服务的整合处理
output: # 这个名字是一个通道的名称
destination: myExchange # Exchange名称(消息队列主题名称),生产者消费者需一致
content-type: application/json # 设置消息类型,本次为json,文本则设置“text/plain”
binder: myRabbit # 设置要绑定的消息服务的具体设置
生产消息方法
接口
public interface MessageProducer {
boolean send();
}
实现
package com.project.stream_producer.demo1.service.impl;
import com.project.stream_producer.demo1.service.MessageProducer;
import org.springframework.cloud.stream.annotation.EnableBinding;
import org.springframework.cloud.stream.messaging.Source;
import org.springframework.messaging.MessageChannel;
import org.springframework.messaging.support.MessageBuilder;
import javax.annotation.Resource;
import java.util.UUID;
@EnableBinding(Source.class)
public class MessageProducerImpl implements MessageProducer {
@Resource
private MessageChannel output;//消息发送管道
@Override
public boolean send() {
String uuid = UUID.randomUUID().toString();
boolean send = output.send(MessageBuilder.withPayload(uuid).build());
System.out.println(uuid);
return send;
}
}
以上代码见 code 上述代码在demo1包下
创建消费者项目
pom
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-rabbit</artifactId>
<version>3.0.10.RELEASE</version>
</dependency>
yml
server:
port: 8000
spring:
application:
name: consumer
cloud:
stream:
binders: # 配置使用mq的信息;
myRabbit:
type: rabbit # 消息组件类型
environment: # mq环境配置
spring:
rabbitmq:
host: 192.168.1.2
port: 5672
username: admin
password: 123456
bindings: # 服务的整合处理
input: # 这个名字是一个通道的名称
destination: myExchange # Exchange名称(消息队列主题名称),生产者消费者需一致
content-type: application/json # 设置消息类型,本次为json,文本则设置“text/plain”
binder: myRabbit
接收消息方法
package com.project.stream_consumer.demo1.controller;
import org.springframework.cloud.stream.annotation.EnableBinding;
import org.springframework.cloud.stream.annotation.StreamListener;
import org.springframework.cloud.stream.messaging.Sink;
import org.springframework.messaging.Message;
import org.springframework.stereotype.Component;
@Component
@EnableBinding(Sink.class)
public class ConsunmerController {
@StreamListener(Sink.INPUT)
public void input(Message<String> message){
System.out.println("消费消息:"+message.getPayload());
}
}
以上代码见 code 上述代码在demo1包下
重复消费
上述配置,默认实现发布订阅,有消息产生则所有消费端都可收到,有些场景不想这样,所以需新增如下配置
消费者yml
新增group: group_a
bindings: # 服务的整合处理
input: # 这个名字是一个通道的名称
destination: myExchange # 表示要使用的Exchange名称定义
content-type: application/json # 设置消息类型,本次为json,文本则设置“text/plain”
binder: defaultRabbit # 设置要绑定的消息服务的具体设置
group: group_a #分组名称自定义
此时,当消费者再次发送消息,mq只会选择组内一台消费者进行消费
持久化
当消费端加入group配置后,就有了消息持久化的效果,在消费端服务关闭时,生产端产出了消息,消费端启动后会自动拉取
以上代码见 code 上述代码在demo2 YML文件下
消费者负载个性配置(预拉取)
或者理解为,不管你消费速度多慢,只要得到了消费机会,那至少要给我消费指定条数
在众多消费者中,服务器配置参差不齐,消费能力有高有低,为了能让低配的降低负载,高配提高负载,可进行prefetch配置,具体见下方注释
server:
port: 7001
spring:
application:
name: concumer
cloud:
stream:
binders: # 配置使用mq的信息;
myRabbit: #给Binder定义的名称,⽤于后⾯的关联
type: rabbit # 消息组件类型
environment: # mq环境配置
spring:
rabbitmq:
host: localhost
port: 5672
username: consumer
password: 123456
bindings: # 服务的整合处理
input: # 这个名字是一个通道的名称
destination: myExchange # 表示要使用的Exchange名称定义
content-type: application/json # 设置消息类型,本次为json,文本则设置“text/plain”
binder: myRabbit # 关联MQ服务
group: consunmerA
rabbit:
bindings:
input:
consumer:
prefetch: 3 #当有消息产生时,配置这个的消费端会一次性从MQ中读取三条信息,然后依次消费,消费完成后会再次去MQ中拉取消息,如不配置则有消息就会接受
以上代码见 code 上述代码在demo3 YML文件下
测试流程:
- 创建两个消费端,
- A消费端配置prefetch:3,消费速度为2秒一条消息 (控制速度我使用TimeUnit.SECONDS.sleep(2);)
- B消费端配置prefetch:7,消费速度不限制(B消费端可不配置)
- 生产端生产10条消息 (生产者改动见 code demo2包下)
- 这时A消费端因速度慢(手动sleep),只会消费3条,B消费端会消费7条
消费者数量配置
消费顺序:当启动多个消费端服务器或多个消费线程后,消息消费顺序将被打乱
注:每个消费端开几个消费线程来消费消息
配置见下方 concurrency
server:
port: 7001
spring:
application:
name: concumer
cloud:
stream:
binders: # 配置使用mq的信息;
myRabbit: #给Binder定义的名称,⽤于后⾯的关联
type: rabbit # 消息组件类型
environment: # mq环境配置
spring:
rabbitmq:
host: localhost
port: 5672
username: consumer
password: 123456
bindings: # 服务的整合处理
input: # 这个名字是一个通道的名称
destination: myExchange # 表示要使用的Exchange名称定义
content-type: application/json # 设置消息类型,本次为json,文本则设置“text/plain”
binder: myRabbit # 关联MQ服务
group: consunmerA
consumer:
concurrency: 2 # 初始/最少/空闲时 消费者数量。默认1
rabbit:
bindings:
input:
consumer:
prefetch: 3
测试流程:
- 配置concurrency: 2
- 消费端消费时输出线程名字,便于观察
- 当生产者发送10个请求后,会看到有2个线程在消费
消费者数量弹性配置
注:类似线程池,核心线程数和动态扩容上限
配置见下方 maxConcurrency
server:
port: 7001
spring:
application:
name: concumer
cloud:
stream:
binders: # 配置使用mq的信息;
myRabbit: #给Binder定义的名称,⽤于后⾯的关联
type: rabbit # 消息组件类型
environment: # mq环境配置
spring:
rabbitmq:
host: localhost
port: 5672
username: consumer
password: 123456
bindings: # 服务的整合处理
input: # 这个名字是一个通道的名称
destination: myExchange # 表示要使用的Exchange名称定义
content-type: application/json # 设置消息类型,本次为json,文本则设置“text/plain”
binder: myRabbit # 关联MQ服务
group: consunmerA
consumer:
concurrency: 1 # 初始/最少/空闲时 消费者数量。默认1
rabbit:
bindings:
input:
consumer:
maxConcurrency: 5 #最多有五个,当消息积压过多,MQ会自动开放消费者线程数量,使用后会慢慢销毁 至 concurrency数量
prefetch: 3
以上代码见 code 上述代码在demo4 YML文件及demo4包下代码
手动确认消息
消费者yml
#新增配置,开启手动确认
acknowledge-mode: manual
关键代码
channel.basicAck(deliveryTag, false);
package com.project.stream_consumer.controller;
import com.rabbitmq.client.Channel;
import org.springframework.amqp.support.AmqpHeaders;
import org.springframework.cloud.stream.annotation.EnableBinding;
import org.springframework.cloud.stream.annotation.StreamListener;
import org.springframework.cloud.stream.messaging.Sink;
import org.springframework.messaging.Message;
import org.springframework.messaging.handler.annotation.Header;
import org.springframework.stereotype.Component;
import java.io.IOException;
import java.util.concurrent.TimeUnit;
@Component
@EnableBinding(Sink.class)
public class ConsunmerController {
@StreamListener(Sink.INPUT)
public void input(Message<String> message,@Header(AmqpHeaders.CHANNEL) Channel channel,@Header(AmqpHeaders.DELIVERY_TAG) Long deliveryTag){
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("消费者A:"+message.getPayload());
try {
System.out.println("消费者A消费了:" + payload);
channel.basicAck(deliveryTag, true);//消息手动确认,如配置了预读取prefetch=3,在消费完这三条后未确认,将不再去MQ中拉取;
//如果第二个参数配置为true ,生产者一次发送1~10,但2这条消息不去basicAck确认消费,在消费后一条时,会默认消费掉2这条消息;
//配置为false时,basicAck只会确认传入的消息,之前未确认的消息不会消费
} catch (IOException e) {
e.printStackTrace();
}
}
}
以上代码见 code 上述代码在demo5 YML文件及demo5包下代码
MQ优化目标
上述消费者数量配置、预读取配置可提高消费的效率,那设置多少合适?可参考下面的方式
- 访问http://127.0.0.1:15672,进入RabbitMQ管理页面,
- 进入Queues Tab页,找到对应的消息,进入
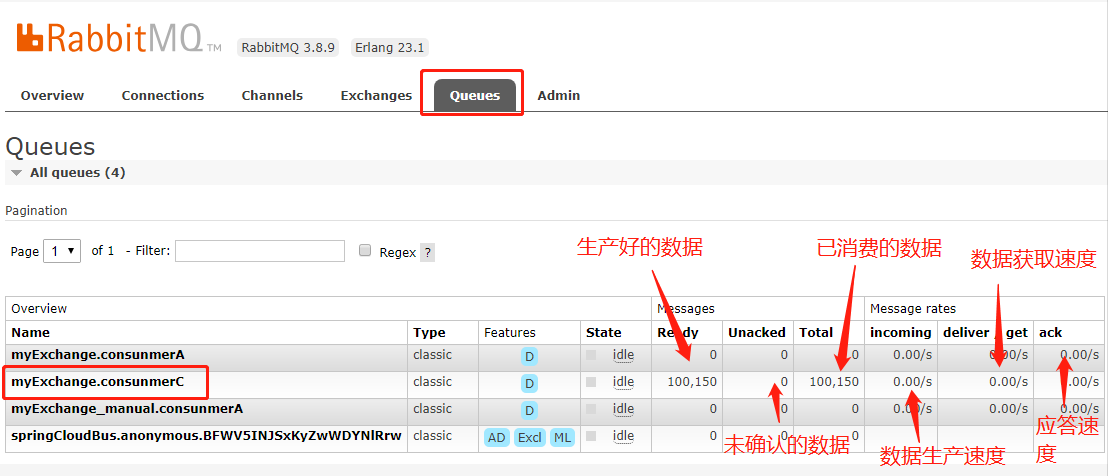
-
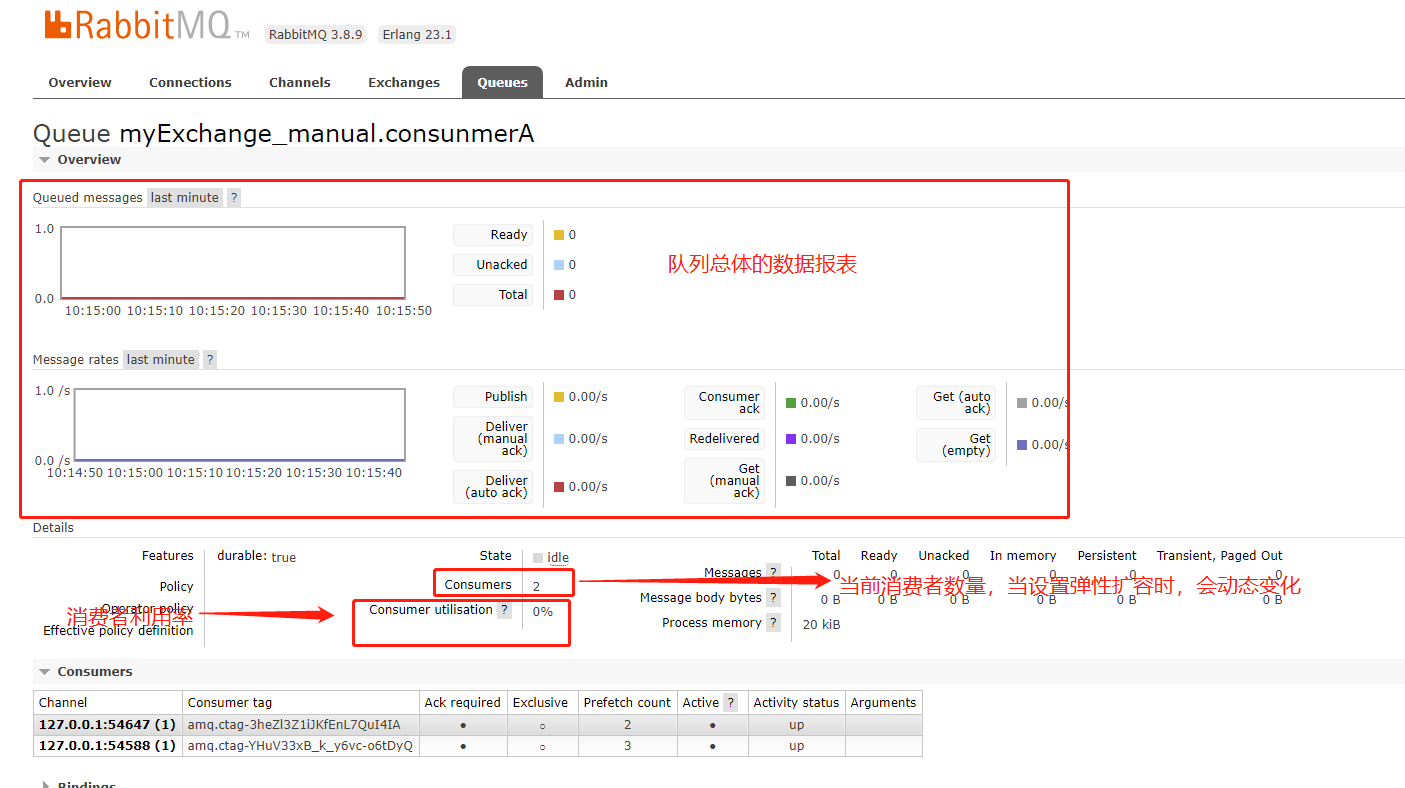
进入对应消息后,会看到下图页面
![image-20201201101843239]()
-
最终看的就是上图中“消费者利用率”,值为0~100%,数值越高,证明消费者资源利用度越高,或者说数值越高越好,如果这个数值已经很高,但还有很多消息积压,就需要增加消费者了
多Exchange配置
每个项目会用到多个主题,下面是多主题配置方式
生产者项目
- 参考Source.class,新增配置
import org.springframework.cloud.stream.annotation.Output;
import org.springframework.messaging.MessageChannel;
public interface MyOutPut {
String MYOUTPUT2 = "myoutput2";
@Output(MyOutPut.MYOUTPUT2)
MessageChannel myoutput2();
String MYOUTPUT1 = "myoutput1";
@Output(MyOutPut.MYOUTPUT1)
MessageChannel myoutput1();
}
-
修改YML文件
bindings下绑定了多组,改动点见bindings下
server: port: 8000 spring: application: name: producer cloud: stream: binders: # 配置使用mq的信息; myRabbit: # 自定义的名称,用于下方bindings -> binder type: rabbit # 消息组件类型 environment: # mq环境配置 spring: rabbitmq: host: 192.168.1.2 port: 5672 username: admin password: 123456 bindings: # 服务的整合处理 myoutput2: # 这个是上面新建配置类MyOutPut中的名字 destination: myoutput2_change # 表示要使用的Exchange名称定义 content-type: application/json # 设置消息类型,本次为json,文本则设置“text/plain” binder: myRabbit # 设置要绑定的消息服务的具体设置 myoutput1: # 这个是上面新建配置类的名字 destination: myoutput1_change # 表示要使用的Exchange名称定义 content-type: application/json # 设置消息类型,本次为json,文本则设置“text/plain” binder: myRabbit # 设置要绑定的消息服务的具体设置 -
实现类修改
@EnableBinding(MyOutPut.class) //修改为自定义的配置 public class MessageProducerImpl implements MessageProducer { @Autowired private MyOutPut myOutPut;//引入自定义的 @Override public boolean send(int num,int tag) { boolean send=true; if(tag==2) send=myOutPut.myoutput2().send(MessageBuilder.withPayload("output_send>>"+num).build());//根据业务不同调用不同output if(tag==1) send=myOutPut.myoutput1().send(MessageBuilder.withPayload("myoutput_send>>"+num).build()); return send; } }
以上代码见 code 上述代码在demo3 YML文件及demo3包下代码
消费者项目
-
参考Sink.class,新增配置
import org.springframework.cloud.stream.annotation.Input; import org.springframework.messaging.SubscribableChannel; public interface MyInPut { String MYINPUT1 = "myinput1"; @Input(MyInPut.MYINPUT1) SubscribableChannel myinput1(); String MYINPUT2 = "myinput2"; @Input(MyInPut.MYINPUT2) SubscribableChannel myinput2(); } -
修改YML文件
bindings下配置了多组
server: port: 7000 spring: application: name: concumer cloud: stream: binders: # 配置使用mq的信息; myRabbit: #给Binder定义的名称,⽤于后⾯的关联 type: rabbit # 消息组件类型 environment: # mq环境配置 spring: rabbitmq: host: localhost port: 5672 username: consumer password: 123456 bindings: # 服务的整合处理 myinput1: # 这个是上面新建配置类MyInPut中的名字 destination: myoutput1_change # 表示要使用的Exchange名称定义 content-type: application/json # 设置消息类型,本次为json,文本则设置“text/plain” binder: myRabbit # 关联MQ服务 group: consunmerA myinput2: # 这个名字是一个通道的名称 destination: myoutput2_change # 表示要使用的Exchange名称定义 content-type: application/json # 设置消息类型,本次为json,文本则设置“text/plain” binder: myRabbit # 关联MQ服务 rabbit: bindings: myinput1: consumer: acknowledge-mode: manual -
修改消费端接收信息实现类
import com.project.stream_consumer.mq_config.MyInPut; import com.rabbitmq.client.Channel; import org.springframework.amqp.support.AmqpHeaders; import org.springframework.cloud.stream.annotation.EnableBinding; import org.springframework.cloud.stream.annotation.StreamListener; import org.springframework.messaging.Message; import org.springframework.messaging.handler.annotation.Header; import org.springframework.stereotype.Component; import java.io.IOException; @Component @EnableBinding(MyInPut.class) //引入上面新增的 public class ConsunmerController { @StreamListener(MyInPut.MYINPUT1) //指定监听类中的哪个通道 public void input1(Message<String> message,@Header(AmqpHeaders.CHANNEL) Channel channel,@Header(AmqpHeaders.DELIVERY_TAG) Long deliveryTag){ System.out.println("input1:"+message.getPayload()); try { channel.basicAck(deliveryTag, false); } catch (IOException e) { e.printStackTrace(); } } @StreamListener(MyInPut.MYINPUT2) public void input2(Message<String> message){ System.out.println("input2:"+message.getPayload()); } } -
测试
生产端调用不同通道发送消息后,对应消费端对应通道的监听就会收到消息
以上代码见 code 上述代码在demo6 YML文件及demo6包下代码
集成Kafka
注:下面默认已经安装好KafKa环境
修改生产者项目
pom
新增
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-kafka</artifactId>
<version>3.0.10.RELEASE</version>
</dependency>
修改yml
标***的为新增配置
server:
port: 8000
spring:
application:
name: producer
cloud:
stream:
default-binder: mykafka #***设置项目启动默认绑定哪个MQ,在同时配置多种MQ必须配置,否则报错
binders: # 配置使用mq的信息;
#***kafka环境配置start
mykafka:
type: kafka
environment:
spring:
cloud:
stream:
kafka:
binder:
brokers: http://192.168.1.5:9092 #kafka地址,多个可用,隔开
auto-add-partitions: true
auto-create-topics: true
min-partition-count: 1
#***kafka环境配置end
myRabbit: # 自定义的名称,用于下方bindings -> binder
type: rabbit # 消息组件类型
environment: # mq环境配置
spring:
rabbitmq:
host: 192.168.1.2
port: 5672
username: admin
password: 123456
bindings: # 服务的整合处理
myoutput2: # 这个名字是一个通道的名称
destination: myoutput2_change # 表示要使用的Exchange名称定义
content-type: application/json # 设置消息类型,本次为json,文本则设置“text/plain”
binder: myRabbit # 设置要绑定的消息服务的具体设置
myoutput1: # 这个名字是一个通道的名称
destination: myoutput1_change # 表示要使用的Exchange名称定义
content-type: application/json # 设置消息类型,本次为json,文本则设置“text/plain”
binder: myRabbit # 设置要绑定的消息服务的具体设置
#***kafka配置start
mykafkaoutput: # 这个名字是一个通道的名称
destination: my_kafka_topic # 表示要使用的topic名称定义
content-type: application/json # 设置消息类型,本次为json,文本则设置“text/plain”
binder: mykafka # 设置要绑定的消息服务的具体设置
#***kafka配置end
修改代码
-
MyOutPut.java
package com.project.stream_producer.mq_config; import org.springframework.cloud.stream.annotation.Output; import org.springframework.messaging.MessageChannel; public interface MyOutPut { String MYOUTPUT2 = "myoutput2"; @Output(MyOutPut.MYOUTPUT2) MessageChannel myoutput2(); String MYOUTPUT1 = "myoutput1"; @Output(MyOutPut.MYOUTPUT1) MessageChannel myoutput1(); //新增下面三行 String MYKAFKAOUTPUT = "mykafkaoutput"; @Output(MyOutPut.MYKAFKAOUTPUT) MessageChannel mykafkaoutput(); } -
MessageProducerByMyOutPutImpl.java
import com.project.stream_producer.mq_config.MyOutPut; import com.project.stream_producer.service.MessageProducer; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.cloud.stream.annotation.EnableBinding; import org.springframework.messaging.support.MessageBuilder; import javax.annotation.Resource; @EnableBinding(MyOutPut.class) public class MessageProducerByMyOutPutImpl implements MessageProducer { @Autowired private MyOutPut myOutPut;//消息发送管道 @Override public boolean send(int num,int tag) { boolean send=true; if(tag==2) send=myOutPut.myoutput2().send(MessageBuilder.withPayload("output_send>>"+num).build()); if(tag==1) send=myOutPut.myoutput1().send(MessageBuilder.withPayload("myoutput_send>>"+num).build()); if(tag==3) //新增kafka发送方法 send=myOutPut.mykafkaoutput().send(MessageBuilder.withPayload("mykafka_send>>"+num).build()); return send; } }
以上代码见 code 上述代码在demo4 YML文件及demo4包下代码
修改消费者项目
pom
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-kafka</artifactId>
<version>3.0.10.RELEASE</version>
</dependency>
yml
标***的为新增配置
server:
port: 7000
spring:
application:
name: concumer
cloud:
stream:
default-binder: mykafka
binders: # 配置使用mq的信息;
#***kafka环境配置start
mykafka:
type: kafka
environment:
spring:
cloud:
stream:
kafka:
binder:
brokers: http://192.168.1.5:9092 #kafka地址,多个可用,隔开
#***kafka环境配置end
myRabbit: #给Binder定义的名称,⽤于后⾯的关联
type: rabbit # 消息组件类型
environment: # mq环境配置
spring:
rabbitmq:
host: localhost
port: 5672
username: consumer
password: 123456
bindings: # 服务的整合处理
myinput1: # 这个名字是一个通道的名称
destination: myoutput1_change # 表示要使用的Exchange名称定义
content-type: application/json # 设置消息类型,本次为json,文本则设置“text/plain”
binder: myRabbit # 关联MQ服务
group: consunmerA
consumer:
concurrency: 1 # 初始/最少/空闲时 消费者数量。默认1
myinput2: # 这个名字是一个通道的名称
destination: myoutput2_change # 表示要使用的Exchange名称定义
content-type: application/json # 设置消息类型,本次为json,文本则设置“text/plain”
binder: myRabbit # 关联MQ服务
group: consunmerA
consumer:
concurrency: 1
#***kafka配置start
mykafkainput: # 这个名字是一个通道的名称
destination: my_kafka_topic # 表示要使用的topic名称定义
content-type: application/json # 设置消息类型,本次为json,文本则设置“text/plain”
binder: mykafka # 关联MQ服务
#***kafka配置end
rabbit:
bindings:
myinput1:
consumer:
maxConcurrency: 1
prefetch: 3
acknowledge-mode: manual
修改代码
-
MyInPut.java
import org.springframework.cloud.stream.annotation.Input; import org.springframework.messaging.SubscribableChannel; public interface MyInPut { String MYINPUT1 = "myinput1"; @Input(MyInPut.MYINPUT1) SubscribableChannel myinput1(); String MYINPUT2 = "myinput2"; @Input(MyInPut.MYINPUT2) SubscribableChannel myinput2(); //新增如下三行 String MYKAFKAINPUT = "mykafkainput"; @Input(MyInPut.MYKAFKAINPUT) SubscribableChannel mykafkainput(); } -
ConsunmerController.java
package com.project.stream_consumer.controller; import com.project.stream_consumer.mq_config.MyInPut; import com.rabbitmq.client.Channel; import org.springframework.amqp.support.AmqpHeaders; import org.springframework.beans.factory.annotation.Value; import org.springframework.cloud.stream.annotation.EnableBinding; import org.springframework.cloud.stream.annotation.StreamListener; import org.springframework.messaging.Message; import org.springframework.messaging.handler.annotation.Header; import org.springframework.stereotype.Component; import java.io.IOException; @Component @EnableBinding(MyInPut.class) public class ConsunmerController { @Value("${spring.application.name}") String name; @StreamListener(MyInPut.MYINPUT1) public void input1(Message<String> message,@Header(AmqpHeaders.CHANNEL) Channel channel,@Header(AmqpHeaders.DELIVERY_TAG) Long deliveryTag){ System.out.println("input1:"+message.getPayload()); try { channel.basicAck(deliveryTag, false); } catch (IOException e) { e.printStackTrace(); } } @StreamListener(MyInPut.MYINPUT2) public void input2(Message<String> message){ System.out.println("input2:"+message.getPayload()); } //新增下面方法 @StreamListener(MyInPut.MYKAFKAINPUT) public void input3(Message<String> message){ System.out.println(name+">kafka:"+message.getPayload()); } }
以上代码见 code 上述代码在demo7 YML文件及demo7包下代码
测试
生产者执行send请求,消费者即可接收消息
重复消费
同上方rabbitMq 分组配置,设置效果同上
手动确认消息
-
修改消费者yml
标***的为新增配置
server: port: 7000 spring: application: name: concumer1 cloud: stream: default-binder: mykafka binders: # 配置使用mq的信息; mykafka: type: kafka environment: spring: cloud: stream: kafka: binder: brokers: http://192.168.1.5:9092 #kafka地址,多个可用,隔开 auto-add-partitions: true auto-create-topics: true min-partition-count: 1 myRabbit: #给Binder定义的名称,⽤于后⾯的关联 type: rabbit # 消息组件类型 environment: # mq环境配置 spring: rabbitmq: host: 192.168.1.2 port: 5672 username: consumer password: 123456 bindings: # 服务的整合处理 myinput1: # 这个名字是一个通道的名称 destination: myoutput1_change # 表示要使用的Exchange名称定义 content-type: application/json # 设置消息类型,本次为json,文本则设置“text/plain” binder: myRabbit # 关联MQ服务 group: consunmerA consumer: concurrency: 1 # 初始/最少/空闲时 消费者数量。默认1 myinput2: # 这个名字是一个通道的名称 destination: myoutput2_change # 表示要使用的Exchange名称定义 content-type: application/json # 设置消息类型,本次为json,文本则设置“text/plain” binder: myRabbit # 关联MQ服务 group: consunmerA consumer: concurrency: 1 # 初始/最少/空闲时 消费者数量。默认1 mykafkainput: # 这个名字是一个通道的名称 destination: my_kafka_topic # 表示要使用的Exchange名称定义 content-type: application/json # 设置消息类型,本次为json,文本则设置“text/plain” binder: mykafka # 关联MQ服务 group: consunmerA rabbit: bindings: myinput1: consumer: maxConcurrency: 1 prefetch: 3 acknowledge-mode: manual # ***手动确认消息start kafka: bindings: mykafkainput: consumer: auto-commit-offset: false # ***手动确认消息end -
修改消费者监听方法
@StreamListener(MyInPut.MYKAFKAINPUT) public void input3(Message<String> message) throws InterruptedException { Acknowledgment acknowledgment = message.getHeaders().get(KafkaHeaders.ACKNOWLEDGMENT, Acknowledgment.class); if (acknowledgment != null) { System.out.println(name+">kafka:"+message.getPayload());//接收到的消息 acknowledgment.acknowledge();//确认收到消息 } }以上代码见 code 上述代码在demo8 YML文件及demo8包下代码
-
测试
-
关闭消费者,生产者发送消息
-
通过命令查看topic消费情况
./kafka-consumer-groups.sh --bootstrap-server 192.168.1.5:9092 --describe --group consunmerA # kafka地址 显示详细信息 消费组名![image-20201210150113583]()
CURRENT-OFFSET:最终消费offset,只有自动消费或手动确认消费后才会更新
LOG-END-OFFSET:总共消息offset,每插入一条消息,就会更新
-
当消费者启动后会收到未消费的消息
-
手动确认消息模式下:
未调用acknowledge()方法,当消费者服务重启时,会再次重新消费;
-
-
注:当生产者依次发送1、2、3、4消息,1、2、3未确认。4确认了,那么1、2、3也会被确认
-

死信队列
上面手动确认消息模式测试中发现会出现1、2、3丢失(消费报错)情况,下面可通过DLQ队列将失败的队列保存起来,或通过代码自行处理
-
消费者修改yml
标***的为新增配置
server: port: 7000 spring: application: name: concumer1 cloud: stream: default-binder: mykafka binders: # 配置使用mq的信息; mykafka: type: kafka environment: spring: cloud: stream: kafka: binder: brokers: http://192.168.1.5:9092 #kafka地址,多个可用,隔开 auto-add-partitions: true auto-create-topics: true min-partition-count: 1 myRabbit: #给Binder定义的名称,⽤于后⾯的关联 type: rabbit # 消息组件类型 environment: # mq环境配置 spring: rabbitmq: host: 192.168.1.2 port: 5672 username: consumer password: 123456 bindings: # 服务的整合处理 myinput1: # 这个名字是一个通道的名称 destination: myoutput1_change # 表示要使用的Exchange名称定义 content-type: application/json # 设置消息类型,本次为json,文本则设置“text/plain” binder: myRabbit # 关联MQ服务 group: consunmerA consumer: concurrency: 1 # 初始/最少/空闲时 消费者数量。默认1 myinput2: # 这个名字是一个通道的名称 destination: myoutput2_change # 表示要使用的Exchange名称定义 content-type: application/json # 设置消息类型,本次为json,文本则设置“text/plain” binder: myRabbit # 关联MQ服务 group: consunmerA consumer: concurrency: 1 # 初始/最少/空闲时 消费者数量。默认1 mykafkainput: # 这个名字是一个通道的名称 destination: my_kafka_topic # 表示要使用的Exchange名称定义 content-type: application/json # 设置消息类型,本次为json,文本则设置“text/plain” binder: mykafka # 关联MQ服务 group: consunmerA #***定义DLQ队列配置start mydlqinput: # 这个名字是一个通道的名称 destination: mydlq # 表示要使用的Exchange名称定义 content-type: application/json # 设置消息类型,本次为json,文本则设置“text/plain” binder: mykafka # 关联MQ服务 group: mydlq #***定义DLQ队列配置end rabbit: bindings: myinput1: consumer: maxConcurrency: 1 prefetch: 3 acknowledge-mode: manual kafka: bindings: mykafkainput: consumer: #***dlq开启start enableDlq: true #开启DLQ队列 dlqName: mydlq #自定义dlq名称 #***dlq开启end auto-commit-offset: false #***定义DLQ队列配置start mydlqinput: # 这个名字是一个通道的名称 destination: mydlq # 表示要使用的Exchange名称定义 content-type: application/json # 设置消息类型,本次为json,文本则设置“text/plain” binder: mykafka # 关联MQ服务 group: mydlq #***定义DLQ队列配置end -
MyInPut.java
package com.project.stream_consumer.demo9.conf; import org.springframework.cloud.stream.annotation.Input; import org.springframework.messaging.SubscribableChannel; public interface MyInPut { String MYINPUT1 = "myinput1"; @Input(MyInPut.MYINPUT1) SubscribableChannel myinput1(); String MYINPUT2 = "myinput2"; @Input(MyInPut.MYINPUT2) SubscribableChannel myinput2(); String MYKAFKAINPUT = "mykafkainput"; @Input(MyInPut.MYKAFKAINPUT) SubscribableChannel mykafkainput(); //新增如下三行 String MYDLQINPUT = "mydlqinput"; @Input(MyInPut.MYDLQINPUT) SubscribableChannel mydlqinput(); } -
修改消费者监听方法
@StreamListener(MyInPut.MYKAFKAINPUT) public void input3(Message<String> message) throws Exception { Acknowledgment acknowledgment = message.getHeaders().get(KafkaHeaders.ACKNOWLEDGMENT, Acknowledgment.class); if (acknowledgment != null) { String payload = message.getPayload(); System.out.println(name+">kafka:"+payload); if("mykafka_send>>5".equals(payload)) //当消息满足条件时,故意抛出异常,kafka会重试三次,三次后会推送到DLQ队列 throw new Exception("errorabcd"); acknowledgment.acknowledge(); } } @StreamListener(MyInPut.MYDLQINPUT) public void input4(Message<String> message) throws Exception {//DLQ队列监听 String payload = message.getPayload(); System.out.println(name+">MYDLQINPUT:"+payload); }
以上代码见 code 上述代码在demo9 YML文件及demo9包下代码
并发
每个消费者开几个线程来消费,开多线程消费会导致消费顺序与发送顺序不一致
消费者修改yml
标***的为新增配置
server:
port: 7000
spring:
application:
name: concumer1
cloud:
stream:
default-binder: mykafka
binders: # 配置使用mq的信息;
mykafka:
type: kafka
environment:
spring:
cloud:
stream:
kafka:
binder:
brokers: http://192.168.1.5:9092 #kafka地址,多个可用,隔开
auto-add-partitions: true
auto-create-topics: true
min-partition-count: 1
myRabbit: #给Binder定义的名称,⽤于后⾯的关联
type: rabbit # 消息组件类型
environment: # mq环境配置
spring:
rabbitmq:
host: 192.168.1.2
port: 5672
username: consumer
password: 123456
bindings: # 服务的整合处理
myinput1: # 这个名字是一个通道的名称
destination: myoutput1_change # 表示要使用的Exchange名称定义
content-type: application/json # 设置消息类型,本次为json,文本则设置“text/plain”
binder: myRabbit # 关联MQ服务
group: consunmerA
consumer:
concurrency: 1 # 初始/最少/空闲时 消费者数量。默认1
myinput2: # 这个名字是一个通道的名称
destination: myoutput2_change # 表示要使用的Exchange名称定义
content-type: application/json # 设置消息类型,本次为json,文本则设置“text/plain”
binder: myRabbit # 关联MQ服务
group: consunmerA
consumer:
concurrency: 1 # 初始/最少/空闲时 消费者数量。默认1
mykafkainput: # 这个名字是一个通道的名称
destination: my_kafka_topic # 表示要使用的Exchange名称定义
content-type: application/json # 设置消息类型,本次为json,文本则设置“text/plain”
binder: mykafka # 关联MQ服务
group: consunmerA
#***并发配置start
consumer:
concurrency: 1
#***并发配置end
mydlqinput: # 这个名字是一个通道的名称
destination: mydlq # 表示要使用的Exchange名称定义
content-type: application/json # 设置消息类型,本次为json,文本则设置“text/plain”
binder: mykafka # 关联MQ服务
group: mydlq
rabbit:
bindings:
myinput1:
consumer:
maxConcurrency: 1
prefetch: 3
acknowledge-mode: manual
kafka:
bindings:
mykafkainput:
consumer:
enableDlq: true
dlqName: mydlq
auto-commit-offset: false
以上代码见 code 上述代码在demo10 YML文件及demo10包下代码
预拉取
不知道为什么,死活就是找不到用SpringCloudStream kafka如何实现想RabbitMq一样预拉取消费,没办法,只能找了kafka另外的一种方式来实现。
修改生产者项目
新增如下配置
package com.project.stream_producer.demo5.conf;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.stereotype.Component;
import java.util.concurrent.ExecutionException;
@Component
public class StringProducer {
@Autowired
@Qualifier("stringKafkaTemplate")
private KafkaTemplate<String, String> kafkaTemplate;
public void send(String message) throws ExecutionException, InterruptedException {
kafkaTemplate.send("mykafkainput", message).get();
}
}
package com.project.stream_producer.demo5.conf;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.serialization.StringSerializer;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.core.DefaultKafkaProducerFactory;
import org.springframework.kafka.core.KafkaTemplate;
import java.util.HashMap;
import java.util.Map;
@Configuration
public class StringProducerConfig {
/**
* 配置可以写到配置文件中,此处省略
* @return
*/
@Bean
public KafkaTemplate<String, String> stringKafkaTemplate() {
Map<String, Object> configProps = new HashMap<>();
configProps.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "http://10.66.202.189:9092");
configProps.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
configProps.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
// -----------------------------额外配置,可选--------------------------
//重试,0为不启用重试机制
configProps.put(ProducerConfig.RETRIES_CONFIG, 1);
//控制批处理大小,单位为字节
configProps.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384);
//批量发送,延迟为1毫秒,启用该功能能有效减少生产者发送消息次数,从而提高并发量
configProps.put(ProducerConfig.LINGER_MS_CONFIG, 1);
//生产者可以使用的总内存字节来缓冲等待发送到服务器的记录
configProps.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 1024000);
return new KafkaTemplate<>(new DefaultKafkaProducerFactory<>(configProps));
}
/**
* ----可选参数----
*
* configProps.put(ProducerConfig.ACKS_CONFIG, "1");
* 确认模式, 默认1
*
* acks=0那么生产者将根本不会等待来自服务器的任何确认。
* 记录将立即被添加到套接字缓冲区,并被认为已发送。在这种情况下,不能保证服务器已经收到了记录,
* 并且<code>重试</code>配置不会生效(因为客户端通常不会知道任何故障)。每个记录返回的偏移量总是设置为-1。
*
* acks=1这将意味着领导者将记录写入其本地日志,但不会等待所有追随者的全部确认。
* 在这种情况下,如果领导者在确认记录后立即失败,但在追随者复制之前,记录将会丢失。
*
* acks=all这些意味着leader将等待所有同步的副本确认记录。这保证了只要至少有一个同步副本仍然存在,
* 记录就不会丢失。这是最有力的保证。这相当于acks=-1的设置。
*
*
*
* configProps.put(ProducerConfig.RETRIES_CONFIG, "3");
* 设置一个大于零的值将导致客户端重新发送任何发送失败的记录,并可能出现暂时错误。
* 请注意,此重试与客户机在收到错误后重新发送记录没有什么不同。
* 如果不将max.in.flight.requests.per.connection 设置为1,则允许重试可能会更改记录的顺序,
* 因为如果将两个批发送到单个分区,而第一个批失败并重试,但第二个批成功,则第二批中的记录可能会首先出现。
* 注意:另外,如果delivery.timeout.ms 配置的超时在成功确认之前先过期,则在重试次数用完之前,生成请求将失败。
*
*
* 其他参数:参考:http://www.shixinke.com/java/kafka-configuration
* https://blog.csdn.net/xiaozhu_you/article/details/91493258
*/
}
package com.project.stream_producer.demo5.controller;
import com.project.stream_producer.demo5.conf.StringProducer;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.concurrent.ExecutionException;
@RestController
public class ProducerController {
@Autowired
private StringProducer producer;
@GetMapping("/string")
public String string() throws ExecutionException, InterruptedException {
for (int i = 0; i < 10; i++) {
producer.send("test"+i);
System.out.println(i);
}
return "success";
}
}
以上代码见 code 上述代码在demo5包下代码
修改消费者项目
新增如下代码
package com.project.stream_consumer.demo11.controller;
import com.project.stream_consumer.demo7.conf.MyInPut;
import com.rabbitmq.client.Channel;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.amqp.support.AmqpHeaders;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.cloud.stream.annotation.EnableBinding;
import org.springframework.cloud.stream.annotation.StreamListener;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.support.Acknowledgment;
import org.springframework.kafka.support.KafkaHeaders;
import org.springframework.messaging.Message;
import org.springframework.messaging.handler.annotation.Header;
import org.springframework.stereotype.Component;
import java.io.IOException;
import java.util.List;
import java.util.Optional;
import java.util.concurrent.TimeUnit;
@Component
@EnableBinding(MyInPut.class)
public class ConsunmerController {
@KafkaListener(topics = MyInPut.MYKAFKAINPUT, containerFactory="batchFactory")
public void consumerBatch(List<ConsumerRecord<?, ?>> records, Acknowledgment ack) throws InterruptedException {
System.out.println("接收到消息数量,通过BatchConsumerConfig-》configProps.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, 3)配置:"+records.size());
// TimeUnit.SECONDS.sleep(5);
for(ConsumerRecord record: records) {
Optional<?> kafkaMessage = Optional.ofNullable(record.value());
//System.out.println("Received: " + record);
if (kafkaMessage.isPresent()) {
Object message = record.value();
String topic = record.topic();
System.out.println("接收到消息:" + message);
}
}
ack.acknowledge();//确认消费
}
}
package com.project.stream_consumer.demo11.conf;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.annotation.EnableKafka;
import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory;
import org.springframework.kafka.config.KafkaListenerContainerFactory;
import org.springframework.kafka.core.ConsumerFactory;
import org.springframework.kafka.core.DefaultKafkaConsumerFactory;
import org.springframework.kafka.listener.ContainerProperties;
import java.util.HashMap;
import java.util.Map;
@Configuration
@EnableKafka
public class BatchConsumerConfig {
/**
* 多线程-批量消费
* @return
*/
@Bean
public KafkaListenerContainerFactory<?> batchFactory(){
ConcurrentKafkaListenerContainerFactory<String, String> factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
// 控制多线程消费
// 并发数(如果topic有3各分区。设置成3,并发数就是3个线程,加快消费)
// 不设置setConcurrency就会变成单线程配置, MAX_POLL_RECORDS_CONFIG也会失效,
// 接收的消息列表也不会是ConsumerRecord
//factory.setConcurrency(10);
// poll超时时间
factory.getContainerProperties().setPollTimeout(1500);
factory.getContainerProperties().setAckMode(ContainerProperties.AckMode.MANUAL_IMMEDIATE);
// 控制批量消费
// 设置为批量消费,每个批次数量在Kafka配置参数中设置(max.poll.records)
factory.setBatchListener(true);
return factory;
}
public ConsumerFactory<String, String> consumerFactory() {
return new DefaultKafkaConsumerFactory<>(consumerConfigs());
}
/**
* 消费者配置
* @return
*/
public Map<String, Object> consumerConfigs() {
Map<String, Object> configProps = new HashMap<>();
// 不用指定全部的broker,它将自动发现集群中的其余的borker, 最好指定多个,万一有服务器故障
configProps.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "http://10.66.202.189:9092");
// key序列化方式
configProps.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
// value序列化方式
configProps.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
// GroupID
configProps.put(ConsumerConfig.GROUP_ID_CONFIG, "consunmerA");
// 批量消费消息数量
configProps.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, 3);
// -----------------------------额外配置,可选--------------------------
// 自动提交偏移量
// 如果设置成true,偏移量由auto.commit.interval.ms控制自动提交的频率
// 如果设置成false,不需要定时的提交offset,可以自己控制offset,当消息认为已消费过了,这个时候再去提交它们的偏移量。
// 这个很有用的,当消费的消息结合了一些处理逻辑,这个消息就不应该认为是已经消费的,直到它完成了整个处理。
//configProps.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true");
// 自动提交的频率
configProps.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");
// Session超时设置
configProps.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, "15000");
// 该属性指定了消费者在读取一个没有偏移量的分区或者偏移量无效的情况下该作何处理:
// latest(默认值)在偏移量无效的情况下,消费者将从最新的记录开始读取数据(在消费者启动之后生成的记录)
// earliest :在偏移量无效的情况下,消费者将从起始位置读取分区的记录
configProps.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest");
return configProps;
}
}
以上代码见 code 上述代码在demo11包下代码
说明
当消费者获取消息时,如果未消费消息条数≥配置的预拉取的条数,则拉取指定数量,否则就是剩余未消费记录条数。
一次性拉取消费数量配置
configProps.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, 3);//一次性最多拉取三条
factory.setBatchListener(true);//开启
其他
手动消费配置
factory.getContainerProperties().setAckMode(ContainerProperties.AckMode.MANUAL_IMMEDIATE);
ack.acknowledge();
//具体含义见ContainerProperties.AckMode源码
按上述配置如果不在yml中配置,SpringCloudStreamKafka会默认去连接127.0.0.1,项目中确定不用SpringCloudStreamKafka,可引入spring的pom,删除SpringCloudStreamKafka pom,然后对上述代码进行引用包、代码进行微调
# 引入下面pom
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>2.5.5.RELEASE</version>
</dependency>
#删除下面pom
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-kafka</artifactId>
<version>3.0.10.RELEASE</version>
</dependency>

 浙公网安备 33010602011771号
浙公网安备 33010602011771号