


ElasticSearch集成IK分词器
一、IK分词器是什么
把一段中文或者别的划分成一个个的关键字,我们在搜索时候会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一个匹配操作,
默认的中文分词是将每个字看成一个词,比如"中国的花"会被分为"中","国","的","花",这显然是不符合要求的,所以我们需要安装中文分词器ik来解决这个问题。
二、下载IK分词器
链接https://github.com/medcl/elasticsearch-analysis-ik/releases
三、安装IK
-
下载解压后放到ES安装目录plugins下,我创建了一个ik的文件夹,将解压的内容全部放进去
/usr/local/rb2010/elk/elasticsearch/elasticsearch-7.7.0/plugins/ik


- 重新启动ES,会看到加载了IK插件
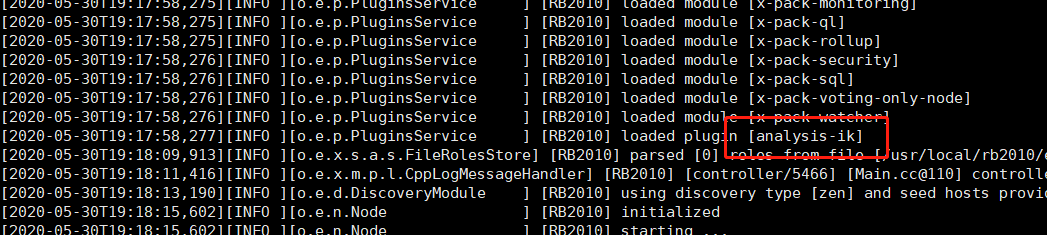
四、测试
-
打开kibana (没有kibana、ES的请参考如下链接)
-
两种分词模式
ik_smart:只是将文本进行拆分
ik_max_word:最大化的将文本进行拆分,将所有拆分可能都列出来
应用场景:搜索的条件尽可能的使用ik_max_word拆分,创建索引的时候使用ik_smart拆分
-
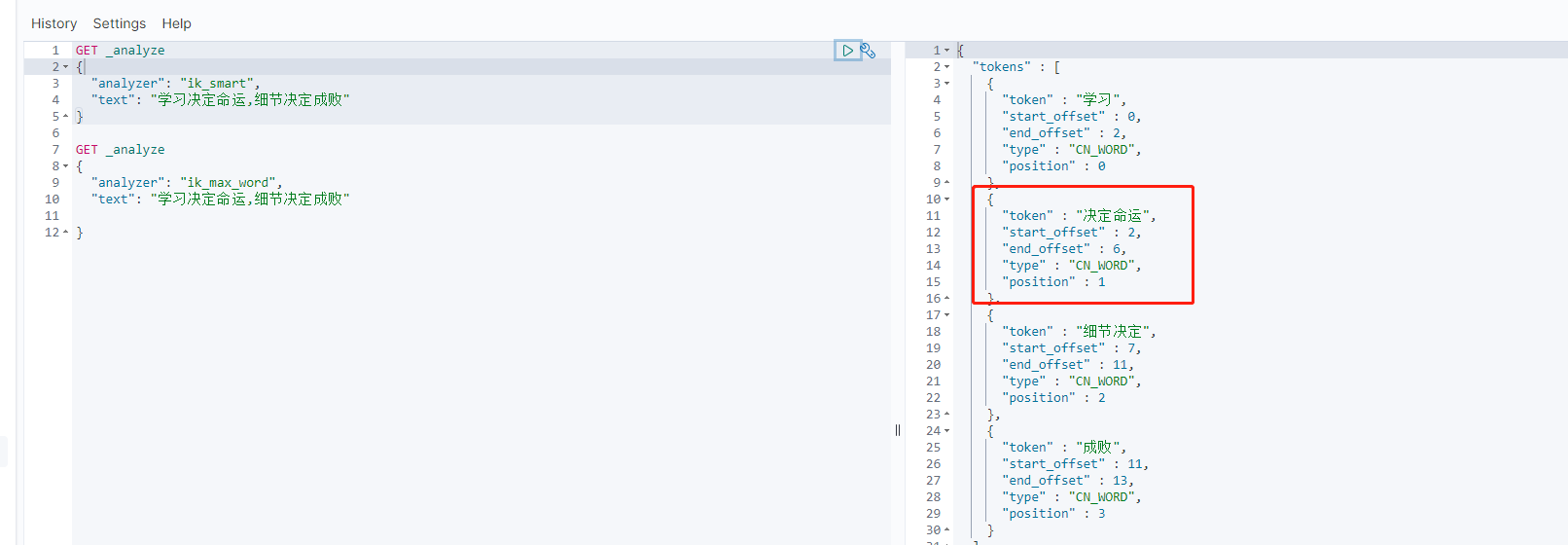
查询方式,对比下就知道怎么回事了
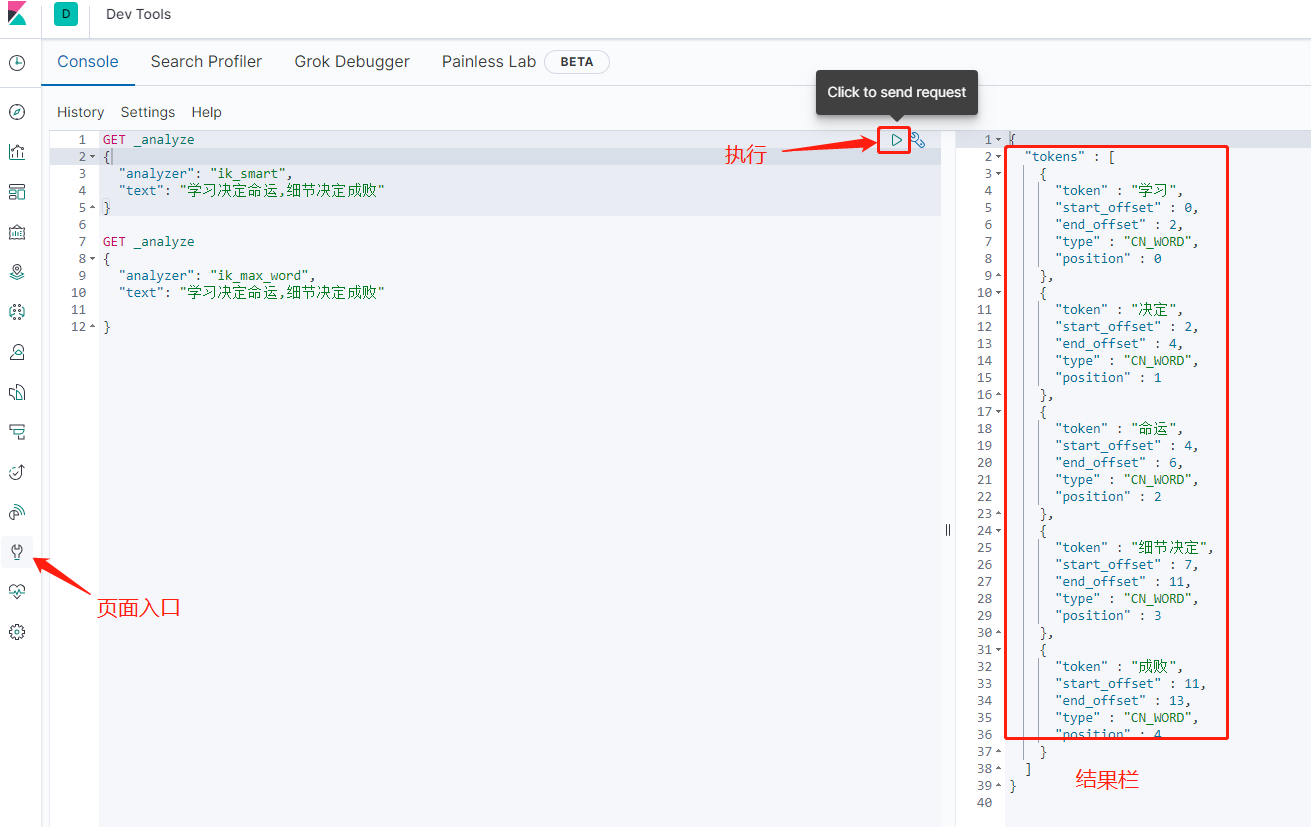
五、自定义词典
例如上面的例子中,我想让“决定命运”变成一个词,不被拆分,这时我就需要定义自己的词典
- 进入IK分词器的目录(就是刚刚解压放到ES中的目录)
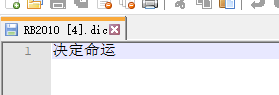
- 打开config,新建一个.dic的文本,里面输入“决定命运”
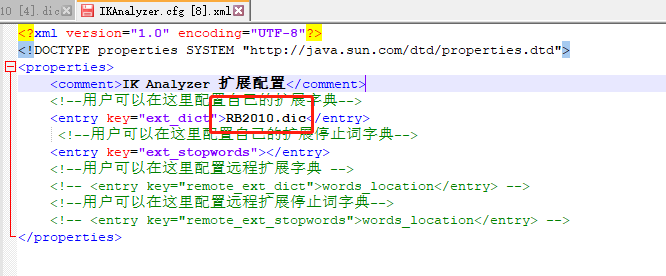
- 修改 IKAnalyzer.cfg.xml 文件,在里面加入自己的词典
4.重启ES后再次使用kabana搜索,刚刚设置的“决定命运”就没有被分割了


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)