
(参考)爬虫3-Requests库的主要方法
Requests库的7个主要方法:
| 方法 | 说明 |
| requests.request() | 构造一个请求,支撑以下各方法的基础方法 |
| requests.get() | 获取HTML网页的主要方法,对应于HTTP的GET |
| requests.head() | 获取HTML网页头信息的方法,对应HTTP的HEAD |
| requests.post() | 向HTML网页提交POST请求的方法,对应于HTTP的POST |
| requests.put() | 向HTTP网页提交PUT请求的方法,对应于HTTP的PUT |
| requests.patch() | 向HTTP网页提交局部修改请求,对应于HTTP的PATCH |
| requests.delete() | 向HTTP页面提交删除请求,对应于HTTP的DELETE |
HTTP协议:超文本传输协议
URL是通过HTTP协议存取资源的Internet路径,一个url对应一个数据资源
HTTP对资源的操作有6个方法,与上表对应。

PATCH和PUT的区别:

HTTP协议方法与Requests库方法具有功能的一致性
head方法 用很少的流量获取网络的概要信息
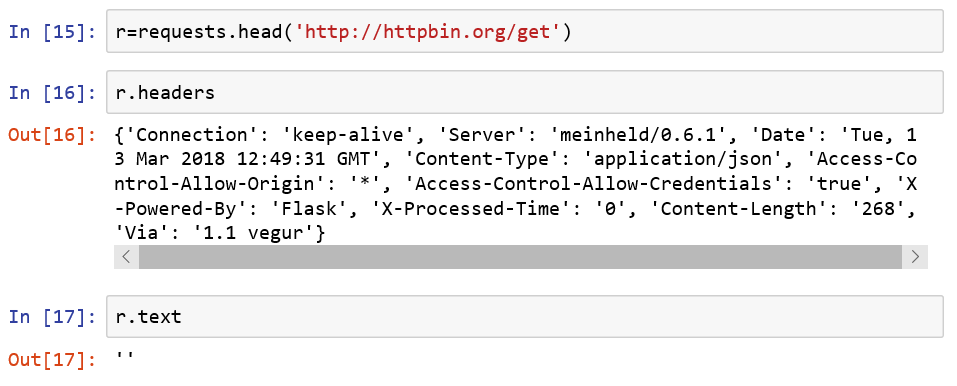
Requests库主要方法解析:
1、requests.request(method,url,**kwargs)
method:表示get head 等方法
url 表示路径
**kwargs 表示其他13个参数 控制访问的参数,均为可选项
比如params 对url进行修改的字段
data:字典、字节序列或文件,Request的内容
json:JSON格式的数据,作为Request的内容
kv={'key1':'value1'}
r=requests.request('POST','http://python123.io/ws',json=kv)
headers:字典,HTTP定制头
hd={'user-agent':'Chrome/10'}#表示将user-agent改为Chrome/10
r=requests.request('POST','http://python123.io/ws',headers=hd)
还有其他的一些字段,在这里不详述。
掌握get和head方法即可。
一定要用try except保证正常访问以及异常处理。
invictus maneo!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号