数据分析随笔(python及pandas及matplotlib查看数据)
笔记:
import pandas as pd
对于csv数据文件,利用pd.read_csv()打开,如train_data=pd.read_csv('')
利用train_data.head()可以查看部分data

train_describe()可以得到统计数目,得到平均数、方差等特征(当然是针对数字类型的数据)

对于非数字类型的数据(字符型 数据),可以使用train_data['这里填带统计的标签'].value_counts()统计分类数目
如下显示的结果对应的是:某一个标签为property_area,标签下有semiurban urban rural等三个类别,统计对应数目

import matplot.pyplot as plt
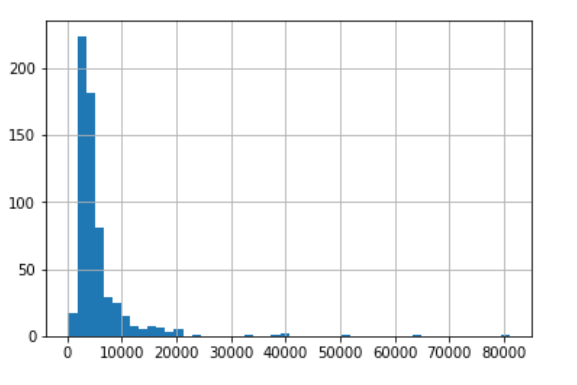
train_data['标签'].hist(bins=50)
plt.show()
可以显示该标签下的数据分布,50表示y轴的间隔,以直方图显示,横轴表示数值范围,y轴表示数量
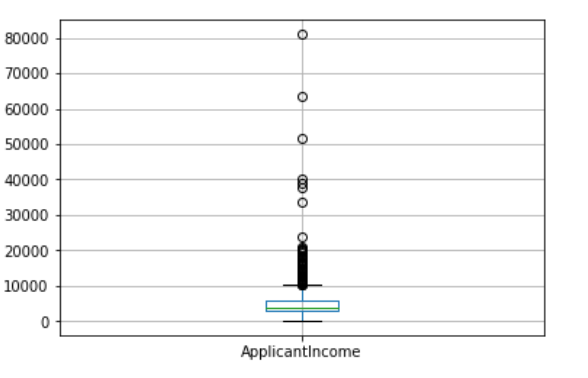
train_data.boxplot(column='标签')
plt.show()
可以显示该标签下的数值分布,观察分布是否均衡
比如下图表示,数据分布并不均匀,有极值出现
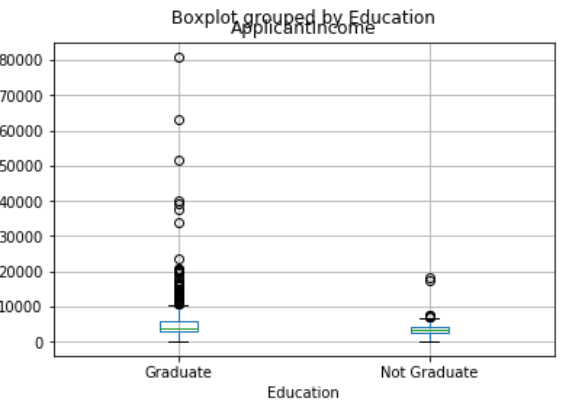
df.boxplot(column='标签1', by = '标签2')
plt.show()
可以将标签1下的数据再按照标签2进行数值分布绘制
如以下表示,已经按照受教育程度分类,受教育水平高的工资极值高,还能得到其他结论
注:在想要画图时,单独输入画图指令还不能显示图形,这时需要在另一行上输入plt.show()才可以,条件:import matplotlib.pyplot as plt
invictus maneo!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号