虚拟化容器
让软件分发部署过程从传统的发布安装包、靠人工部署转变为直接发布已经部署好的、包含整套运行环境的虚拟化镜像。
-
ISA兼容:目标机器指令集兼容性,ARM,X86架构
-
ABI兼容:目标系统或者依赖库的二进制兼容性,Windows,Linux
-
环境兼容:目标环境的兼容性,譬如没有正确设置的配置文件、环境变量、注册中心、数据库地址、文件系统的权限等
使用仿真(Emulation)以及虚拟化(Virtualization)技术来解决以上三项兼容性问题的方法都统称为虚拟化技术。
-
指令集虚拟化(ISA Level Virtualization):通过软件来模拟不同 ISA 架构的处理器工作过程,将虚拟机发出的指令转换为符合本机 ISA 的指令。
-
硬件抽象层虚拟化(Hardware Abstraction Level Virtualization):以软件或者直接通过硬件来模拟处理器、芯片组、内存、磁盘控制器、显卡等设备的工作过程。
-
操作系统层虚拟化(OS Level Virtualization):采用隔离手段,使得不同进程拥有独立的系统资源和资源配额,看起来仿佛是独享了整个操作系统一般,其实系统的内核仍然是被不同进程所共享的。
容器化牺牲了一定的隔离性与兼容性,换来的是比前两种虚拟化更高的启动速度、运行性能和更低的执行负担。
-
运行库虚拟化(Library Level Virtualization):使用软件翻译的方法来模拟系统,以一个独立进程来代替操作系统内核来提供目标软件运行所需的全部能力。
-
语言层虚拟化(Programming Language Level Virtualization)。将高级语言生成的中间代码转换为目标机器可以直接执行的指令。
容器的崛起
隔离文件:chroot
“Change Root”,当某个进程经过chroot操作之后,它的根目录就会被锁定在命令参数所指定的位置,以后它或者它的子进程将不能再访问和操作该目录之外的其他文件。
隔离文件:pivot_root
直接切换了
UNIX,一切资源都可视为文件。
理论上,只要隔离了文件系统,一切资源都应该被自动隔离。现实上,从硬件层面暴露的低层次资源,如磁盘、网络、内存、处理器,到经操作系统层面封装的高层次资源,如 UNIX 分时(UNIX Time-Sharing,UTS)、进程 ID(Process ID,PID)、用户 ID(User ID,UID)、进程间通信(Inter-Process Communication,IPC)都存在大量以非文件形式暴露的操作入口,因此,以chroot为代表的文件隔离,仅仅是容器崛起之路的起点而已。
隔离访问:namespaces
Linux名称空间:由内核直接提供的全局资源封装,是内核针对进程设计的访问隔离机制。
进程在一个独立的 Linux 名称空间中朝系统看去,会觉得自己仿佛就是这方天地的主人,拥有这台 Linux 主机上的一切资源
Linux 名称空间支持以下八种资源的隔离
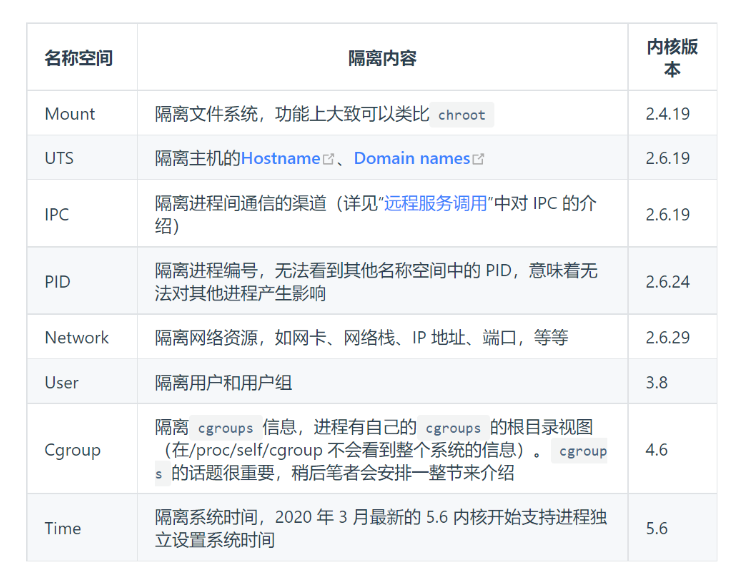
隔离资源:cgroups
控制群组(Control Groups,cgroups),直接由内核提供的功能,用于隔离或者说分配并限制某个进程组能够使用的资源配额,资源配额包括处理器时间、内存大小、磁盘 I/O 速度等
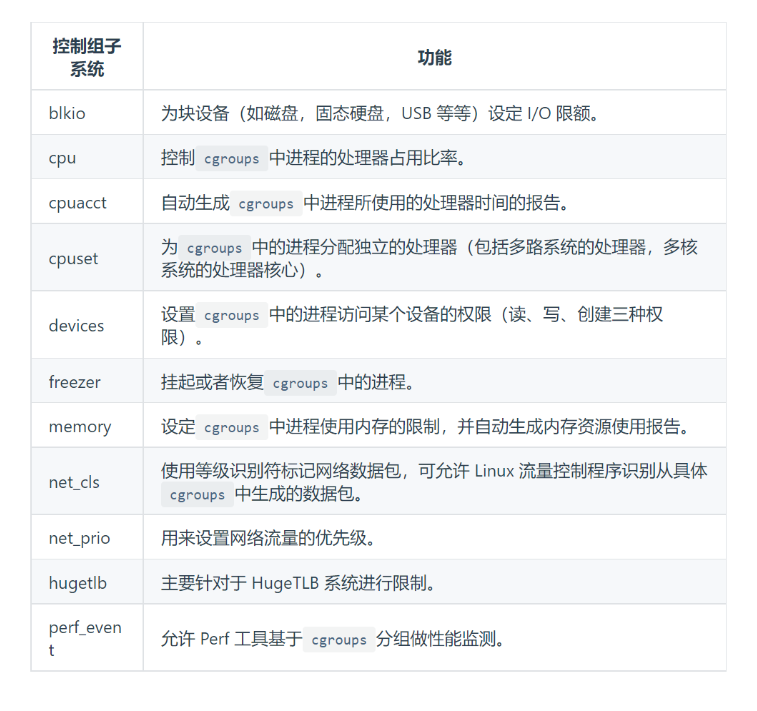
封装系统: LXC
Linux容器,封装系统的轻量级虚拟机。
Docker 眼中的容器的定义则是一种封装应用的技术手段。
封装应用:Docker
-
跨机器的绿色部署:Docker 定义了一种将应用及其所有的环境依赖都打包到一起的格式,仿佛它原本就是
-
以应用为中心的封装:Docker 封装应用而非封装机器的理念贯穿了它的设计、API、界面、文档等多个方面。
-
自动构建:Docker 提供了开发人员从在容器中构建产品的全部支持,开发人员无需关注目标机器的具体配置,即可使用任意的构建工具链,在容器中自动构建出最终产品。
-
多版本支持:Docker 支持像 Git 一样管理容器的连续版本,进行检查版本间差异、提交或者回滚等操作。
-
组件重用:Docker 允许将任何现有容器作为基础镜像来使用,以此构建出更加专业的镜像。
-
共享:Docker 拥有公共的镜像仓库
libcontainer :越过 LXC 直接操作namespaces和cgroups的核心模块,能直接与系统内核打交道,不必依赖 LXC 来提供容器化隔离能力。
runC:将 libcontainer 独立出来,封装重构成
containerd:负责管理容器执行、分发、监控、网络、构建、日志等功能的核心模块,内部会为每个容器运行时创建一个 containerd-shim 适配进程,默认与 runC 搭配工作
封装集群:Kubernetes
把大型软件系统运行所依赖的集群环境也进行了虚拟化,令集群得以实现跨数据中心的绿色部署,并能够根据实际情况自动扩缩。
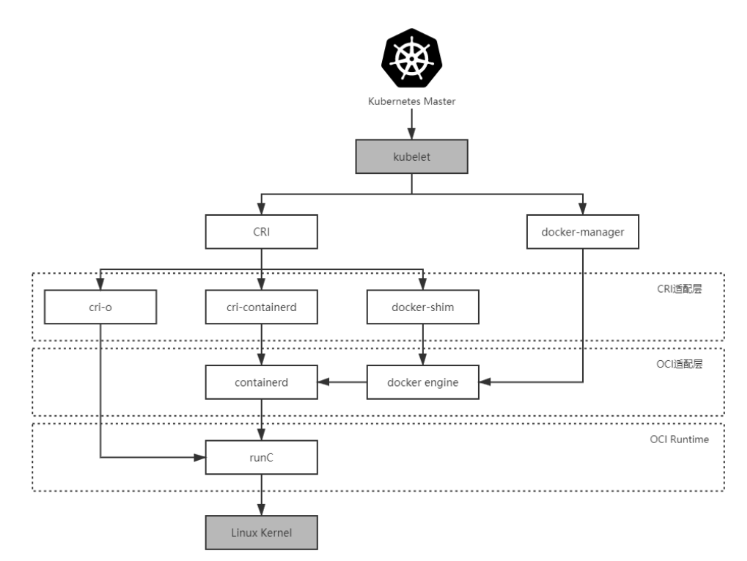
Kubernetes 1.5 之前,Kubernetes 管理容器的方式都是通过内部的 DockerManager 向 Docker Engine 以 HTTP 方式发送指令,通过 Docker 来操作镜像的增删改查的。
kubelet 是集群节点中的代理程序,负责与管理集群的 Master 通信。
Kubernetes Master → kubelet → DockerManager → Docker Engine → containerd → runC
OCI(Open Container Initiative)开放容器交互标准
容器格式和运行时的规范文件,包含运行时标准(
运行时标准:如何运行一个容器、如何管理容器的状态和生命周期、如何使用操作系统的底层特性。
容器镜像标准:容器镜像的格式、配置、元数据的格式
镜像分发标准:规定了镜像推送和拉取的网络交互过程
CRI(Container Runtime Interface) 容器运行时接口
定义容器运行时应该如何接入到 kubelet 的规范标准
以容器构建系统
容器编排:以虚拟化方法实现多个进程共同协作,通过集群的形式对外提供服务
容器编排框架:调度容器、分配资源、扩缩规模、最大限度地接管系统中的非功能特性,让业务系统尽可能免受分布式复杂性的困扰
Dockerfile 只允许有一个 ENTRYPOINT,因为 Docker 只能通过监视 PID 为 1 的进程(即由 ENTRYPOINT 启动的进程)的运行状态来判断容器的工作状态是否正常,
Docker Compose核心能力:自动地为多个容器设置好共享名称空间
容器的本质是对 cgroups 和 namespaces 所提供的隔离能力的一种封装,在 Docker 提倡的单进程封装的理念影响下,容器蕴含的隔离性也多了仅针对于单个进程的额外局限,然而 Linux 的 cgroups 和 namespaces 原本都是针对进程组而不仅仅是单个进程来设计的,同一个进程组中的多个进程天然就可以共享着相同的访问权限与资源配额。如果现在我们把容器与进程在概念上对应起来,那容器编排的第一个扩展点,就是要找到容器领域中与“进程组”相对应的概念,这是实现容器从隔离到协作的第一步,在 Kubernetes 的设计里,这个对应物叫作
将多个容器放到同一个 Pod 中,Pod扮演了容器组的角色,以及满足容器共享名称空间的需求。
一个 Pod 内的多个容器,相互之间以超亲密的方式协作。
超亲密的协作是特指多个容器位于同一个 Pod 这种特殊关系,它们将默认共享:
-
UTS 名称空间:所有容器都有相同的主机名和域名。
-
网络名称空间:所有容器都共享一样的网卡、网络栈、IP 地址,等等。因此,同一个 Pod 中不同容器占用的端口不能冲突。
-
IPC 名称空间:所有容器都可以通过信号量或者 POSIX 共享内存等方式通信。
-
时间名称空间:所有容器都共享相同的系统时间。
同一个 Pod 的容器,只有 PID 名称空间和文件名称空间默认是隔离的。
普通非亲密的容器,它们一般以网络交互方式(其他譬如共享分布式存储来交换信息也算跨网络)协作;
亲密协作的容器,是指它们被调度到同一个集群节点上,可以通过共享本地磁盘等方式协作;
Pod是隔离与调度的基本单位。 逻辑上存在、没有物理对应
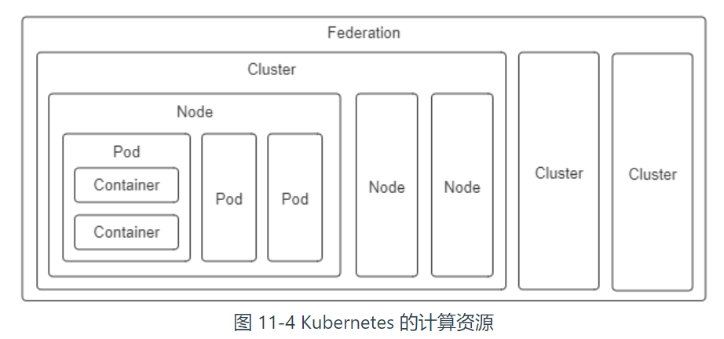
Kubernetes 将一切皆视为资源,不同资源之间依靠层级关系相互组合协作。
-
容器(Container):延续了自 Docker 以来一个容器封装一个应用进程的理念,是镜像管理的最小单位。
-
生产任务(Pod):补充了容器化后缺失的与进程组对应的“容器组”的概念,Pod 中容器共享 UTS、IPC、网络等名称空间,是资源调度的最小单位。
-
节点(Node):对应于集群中的单台机器,这里的机器即可以是生产环境中的物理机,也可以是云计算环境中的虚拟节点,节点是处理器和内存等资源的资源池,是硬件单元的最小单位。
-
集群(Cluster):对应于整个集群,Kubernetes 提倡理念是面向集群来管理应用。当你要部署应用的时候,只需要通过声明式 API 将你的意图写成一份元数据(Manifests),将它提交给集群即可,而无需关心它具体分配到哪个节点(尽管通过标签选择器完全可以控制它分配到哪个节点,但一般不需要这样做)、如何实现 Pod 间通信、如何保证韧性与弹性,等等,所以集群是处理元数据的最小单位。
-
集群联邦(Federation):对应于多个集群,通过联邦可以统一管理多个 Kubernetes 集群,联邦的一种常见应用是支持跨可用区域多活、跨地域容灾的需求。
韧性与弹性
控制回路: 例子—房间中空调自动调节温度
当你设置好了温度,就是告诉空调你对温度的“
根据当前状态与期望状态的差距,控制器对空调制冷的开关进行调节控制,就能让其当前状态逐渐接近期望状态。
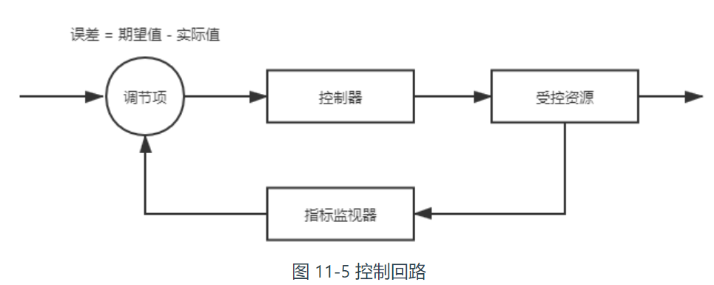
声明式 API通过描述清楚资源的期望状态,由 Kubernetes 中对应监视这些资源的控制器来驱动资源的实际状态逐渐向期望状态靠拢,以此来达成目的。
ReplicaSet 也是一种资源,是属于工作负荷一类的资源,它代表一个或多个 Pod 副本的集合,你可以在 ReplicaSet 资源的元数据中描述你期望 Pod 副本的数量(即spec.replicas的值)。
当 ReplicaSet 成功创建之后,副本集控制器就会持续跟踪该资源,如果一旦有 Pod 发生崩溃退出,或者状态异常(默认是靠进程返回值,你还可以在 Pod 中设置探针,以自定义的方式告诉 Kubernetes 出现何种情况 Pod 才算状态异常),ReplicaSet 都会自动创建新的 Pod 来替代异常的 Pod;如果异常多出现了额外数量的 Pod,也会被 ReplicaSet 自动回收掉,总之就是确保任何时候集群中这个 Pod 副本的数量都向期望状态靠拢。
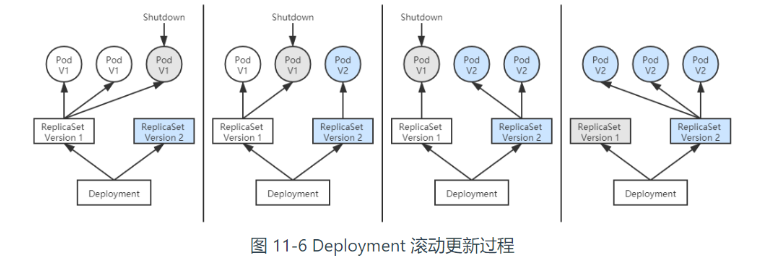
在升级程序版本时,ReplicaSet 不得不主动中断旧 Pod 的运行,重新创建新版的 Pod,这会造成服务中断。
先创建新版本的 ReplicaSet,然后一边让新 ReplicaSet 逐步创建新版 Pod 的副本,一边让旧的 ReplicaSet 逐渐减少旧版 Pod 的副本。
自动扩容缩容
Autoscaling 资源和自动扩缩控制器,能够自动根据度量指标,如处理器、内存占用率、用户自定义的度量值等,来设置 Deployment(或者 ReplicaSet)的期望状态,实现当度量指标出现变化时,系统自动按照“Autoscaling→Deployment→ReplicaSet→Pod”这样的顺序层层变更,最终实现根据度量指标自动扩容缩容。
服务的弹性(Elasticity)与韧性(Resilience):

 浙公网安备 33010602011771号
浙公网安备 33010602011771号