服务组件——服务发现、网关路由、客户端负载均衡
服务发现
使用全限定名(Fully Qualified Domain Name,
全限定名:网络中某台主机的精确位置
端口:主机上某一个提供了 TCP/UDP 网络服务的程序
服务标识:该程序所提供的某个具体的方法入口(REST 的远程服务,标识是 URL 地址;RMI 的远程服务,标识是 Stub 类中的方法)
Eureka、Nacos
支持通过 DNS 或者 HTTP 请求进行符号与实际地址的转换,还支持各种各样的服务健康检查方式,支持集中配置、K/V 存储、跨数据中心的数据交换等多种功能
可用和可靠
-
服务的注册
当服务启动时,应该通过某些形式(如调用 API、产生事件消息、在 ZooKeeper/Etcd 的指定位置记录、存入数据库等等)将自己的坐标信息通知到服务注册中心,自注册模式,如使用@EnableEurekaClient注解、@EnableDiscoveryClient注解
-
服务的维护
服务发现框架需要保证所维护的服务列表的正确性,以避免告知消费者服务的坐标后,得到的服务却不能使用的尴尬情况。
支持多种协议(HTTP、TCP 等)、多种方式(长连接、心跳、探针、进程状态等)去监控服务是否健康存活,将不健康的服务自动从服务注册表中剔除。
-
服务的发现
消费者从服务发现框架中,把一个符号(譬如 Eureka 中的 ServiceID、Nacos 中的服务名、或者通用的 FQDN)转换为服务实际坐标的过程。
通过 HTTP API 请求或者通过 DNS Lookup 操作
服务发现扩展功能:负载均衡、流量管控、键值存储、元数据管理、业务分组
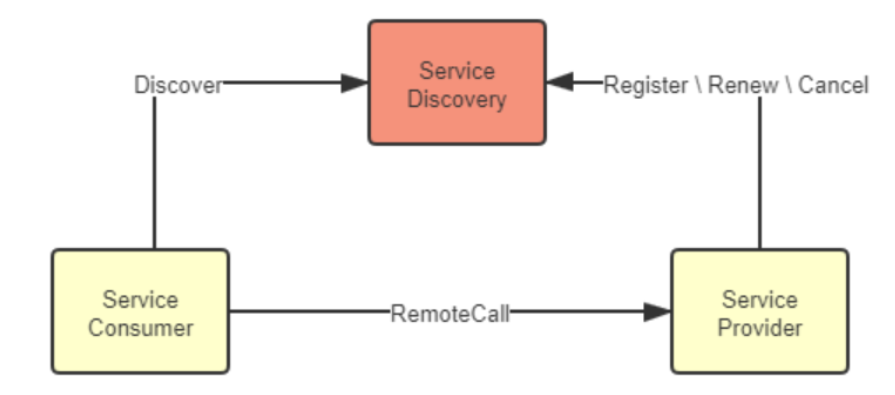
服务提供者在服务注册中心中注册、续约和下线自己的真实坐标,服务消费者根据某种符号从服务注册中心中获取到真实坐标。
注册中心与配置中心被所有其他服务共同依赖,是系统中最基础的服务。意味着服务注册中心一旦崩溃,整个系统都不再可用。
实际用于生产的分布式系统,服务注册中心都是以集群的方式进行部署的,通常使用三个或者五个节点保证高可用。
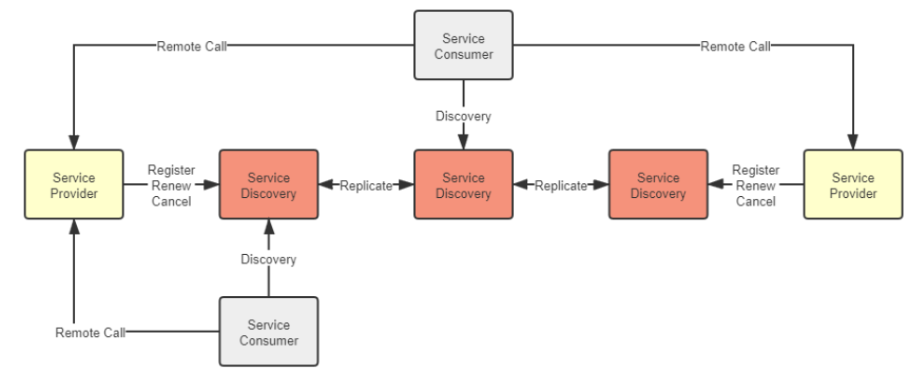
Eureka优先高可用,相对牺牲系统中服务状态的一致性。Eureka 的各个节点间采用异步复制来交换服务注册信息,当有新服务注册进来时,并不需要等待信息在其他节点复制完成,而是马上在该服务发现节点宣告服务可见,只是不保证在其他节点上多长时间后才会可见。
Eureka 能够选择这种模型的底气在于万一客户端拿到了已经发生变动的错误地址,也能够通过 Ribbon 和 Hystrix 模块配合来兜底,实现故障转移(Failover)或者快速失败(Failfast)。
Consul 的选择是优先保证高可靠性,相对牺牲系统服务发现的可用性。要求多数派节点写入成功后服务的注册或变动才算完成,严格地保证了在集群外部读取到的服务发现结果必定是一致的。
注册中心实现
-
在分布式 K/V 存储框架上自己开发的服务发现
分布式环境下读写操作的共识算法,CP,只有基本的 CRUD 和 Watch 等少量 API,所以要在上面完成功能齐全的服务发现,很多基础的能力,譬如服务如何注册、如何做健康检查,等等都必须自己去实现。
-
以基础设施(主要是指 DNS 服务器)来实现服务发现
从 API Server 中监听集群服务的变化,然后根据服务生成 NS、SRV 等 DNS 记录存放到 Etcd 中,kubelet 会为每个 Pod 设置 DNS 服务的地址为 SkyDNS 的地址,需要调用服务时,只需查询 DNS 把域名转换成 IP 列表便可实现分布式的服务发现。
-
专门用于服务发现的框架和工具,
CP 的 Consul、AP 的 Eureka,还有同时支持 CP 和 AP 的 Nacos(Nacos 采用类 Raft 协议做的 CP,采用自研的 Distro 协议做的 AP)
网关路由
又叫”服务网关“、”API网关“,位于内部区域边缘,与外界进行交互的某个物理或逻辑设备
在微服务环境中,作为一个统一对外交互的代理人角色。
微服务中网关的首要职责就是作为统一的出口对外提供服务,将外部访问网关地址的流量,根据适当的规则路由到内部集群中正确的服务节点之上。
网关还可以根据需要作为流量过滤器来使用,提供某些额外的可选的功能,譬如安全、认证、授权、限流、监控、缓存等等
网关 = 路由器(基础职能) + 过滤器(可选职能)
负载均衡器与服务网关区别:负载均衡器是为了根据均衡算法对流量进行平均地路由,服务网关是为了根据流量中的某种特征进行正确地路由。
性能与可用性
网关是所有服务对外的总出口,是流量必经之地,所以网关的路由性能将导致全局的、系统性的影响。由于REST 和 JSON-RPC 等基于 HTTP 协议的服务接口在对外部提供的服务中占绝对主流的地位,所以我们所讨论的服务网关默认都必须支持七层路由。
因此,网关的性能主要取决于它们如何代理网络请求,也即它们的网络 I/O 模型。
网络I/O模型
在套接字接口抽象下,网络 I/O 的出入口就是 Socket 的读和写,Socket 在操作系统接口中被抽象为数据流,网络 I/O 可以理解为对流的操作。
每一次网络访问,从远程主机返回的数据会先存放到
所以当发生一次网络请求发生后,将会按顺序经历“等待数据从远程主机到达缓冲区”和“将数据从缓冲区拷贝到应用程序地址空间”两个阶段
-
-
阻塞I/O
线程休眠,节省 CPU 资源,但缺点就是线程休眠所带来的上下文切换,这是一种需要切换到内核态的重负载操作,不应当频繁进行。
-
非阻塞I/O
避免线程休眠,非阻塞 I/O 可以节省切换上下文切换的消耗,但是对于较长时间才能返回的请求,非阻塞 I/O 浪费了 CPU 资源
-
多路复用 I/O
在同一条阻塞线程上处理多个不同端口的监听,select、poll、epoll
-
信号驱动 I/O
信号驱动 I/O 与异步 I/O 的区别是“从缓冲区获取数据”这个步骤的处理,前者收到的通知是可以开始进行复制操作了,在复制完成之前线程处于阻塞状态,仍属于同步 I/O 操作,而后者收到的通知是复制操作已经完成。
-
-
数据到达缓冲区后,不需要由调用进程主动进行从缓冲区复制数据的操作,而是复制完成后由操作系统向线程发送信号
由于网关的地址具有唯一性,对网关的可用性方面:
-
网关应尽可能轻量,尽管网关作为服务集群统一的出入口,可以很方便地做安全、认证、授权、限流、监控,等等的功能,但给网关附加这些能力时还是要仔细权衡,取得功能性与可用性之间的平衡,过度增加网关的职责是危险的。
-
网关选型时,应该尽可能选择较成熟的产品实现
-
在需要高可用的生产环境中,应当考虑在网关之前部署负载均衡器或者
BFF网关
Backends for Frontends,网关不必为所有的前端提供无差别的服务,而是应该针对不同的前端,聚合不同的服务,提供不同的接口和网络访问协议支持。
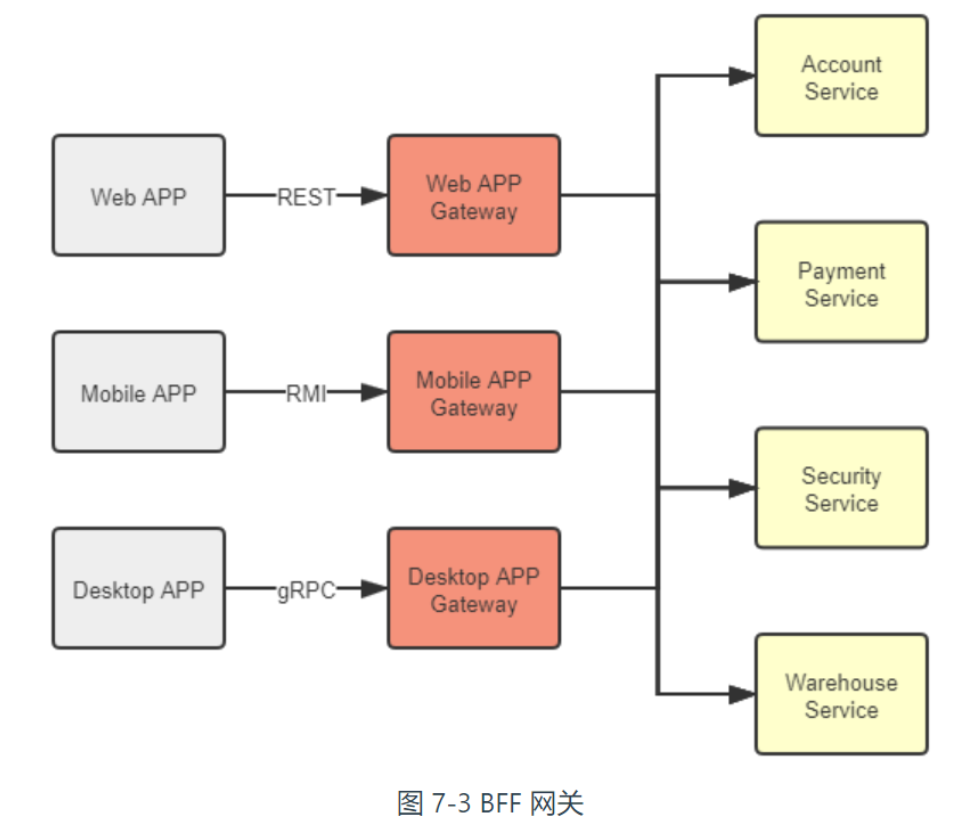
客户端负载均衡
随着微服务日渐流行,服务集群的收到的请求来源不再局限于外部,越来越多的访问请求是由集群内部的某个服务发起,由集群内部的另一个服务进行响应的,对于这类内部流量的特点,直接在服务集群内部消化掉更好。
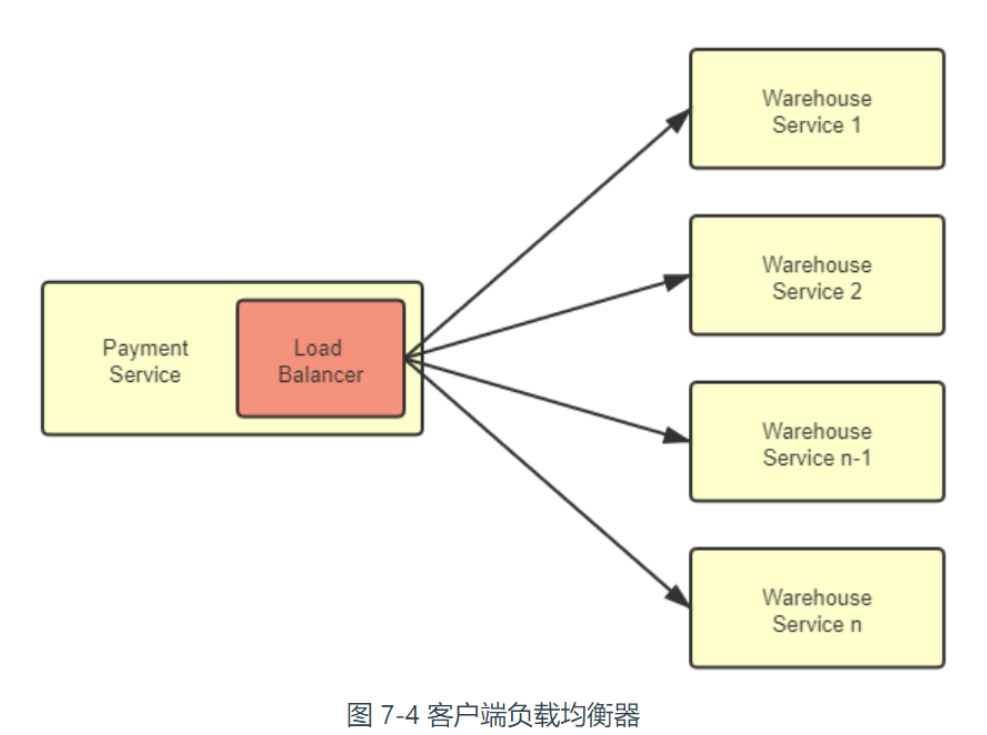
此前的集中式负载均衡器叫做”服务端负载均衡器“,客户端均衡器是和服务实例一一对应的,而且与服务实例并存于同一个进程之内。
优点:
-
均衡器与服务之间信息交换是进程内的方法调用,不存在任何额外的网络开销。
-
不依赖集群边缘的设施,所有内部流量都仅在服务集群的内部循环,避免了出现前文那样,集群内部流量要“绕场一周”的尴尬局面。
-
分散式的均衡器意味着天然避免了集中式的单点问题,它的带宽资源将不会像集中式均衡器那样敏感,这在以七层均衡器为主流、不能通过 IP 隧道和三角传输这样方式节省带宽的微服务环境中显得更具优势。
-
客户端均衡器要更加灵活,能够针对每一个服务实例单独设置均衡策略等参数,访问某个服务,是不是需要具备亲和性,选择服务的策略是随机、轮询、加权还是最小连接等等,都可以单独设置而不影响其它服务。
缺点:
-
它与服务运行于同一个进程之内,意味着它的选型受到服务所使用的编程语言的限制
-
从个体服务来看,由于是共用一个进程,均衡器的稳定性会直接影响整个服务进程的稳定性,消耗的 CPU、内存等资源也同样影响到服务的可用资源。从集群整体来看,在服务数量达成千乃至上万规模时,客户端均衡器消耗的资源总量是相当可观的。
-
服务集群的拓扑关系是动态的,每一个客户端均衡器必须持续跟踪其他服务的健康状况,以实现上线新服务、下线旧服务、自动剔除失败的服务、自动重连恢复的服务等均衡器必须具备的功能。导致数量庞大的客户端均衡器一直持续轮询服务注册中心
代理负载均衡器
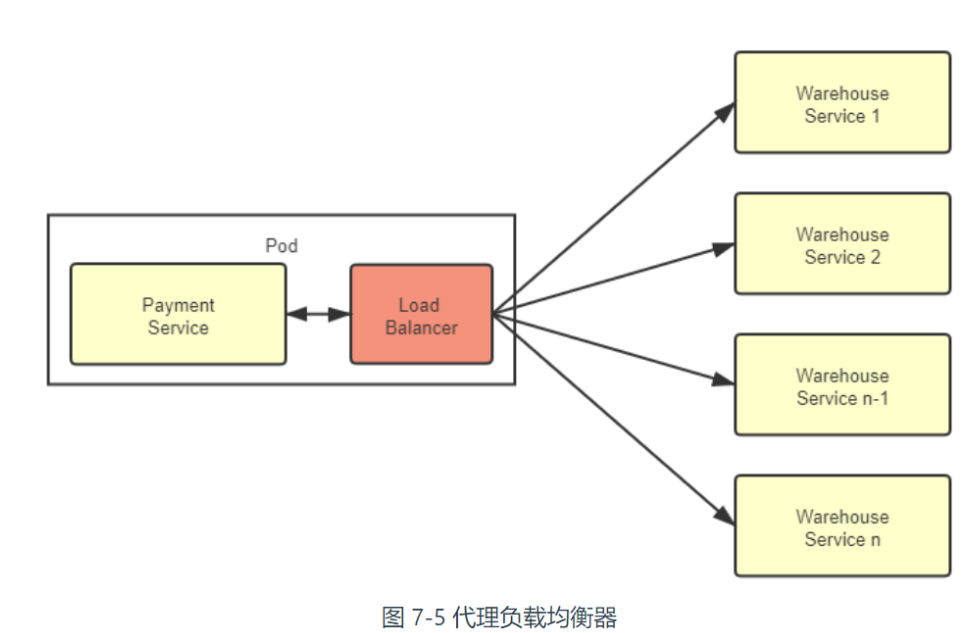
边车代理
地域和区域
地域,华北、华南...,大型系统就是通过不同地域的机房来缩短用户与服务器之间的物理距离,提升响应速度,对于小型系统,地域一般就只在异地容灾时才会涉及到。
集群内部流量是不会跨地域的,服务发现、负载均衡器默认也是不会支持跨地域的服务发现和负载均衡。
区域,指在地理上位于同一地域内,但电力和网络是互相独立的物理区域。例如华南的广州、深圳的不同机房就是同一个地域的几个可用区域。
同一个地域的可用区域之间具有内网连接,流量不占用公网带宽,区域是微服务集群内流量能够触及的最大范围。
应用是只部署在同一区域内,还是部署到几个不同可用区域中,要取决于是否有做异地双活的需求,以及对网络延时的容忍程度。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号