大数据Map Reduce 和 MPP数据库 的区别
总结来说MR是一个编程模型,你可以用MR这个编程模型自己实现MPP所做的事。
MPP则是一种SQL的计算引擎。
“MR分而治之的策略” 和 “Massively Parallel Processor类型的数据库” (即大规模并行处理数据库,典型代表 AWS Redshift 和 Teradata 以及微软的 Azure SQL Data Warehouse) 有什么区别呢?
MPP在数据存储的时候就根据指定的分布方式交给不同节点储存, 查询的时候各块的节点有独立的计算资源分别处理, 然后汇总到一个leader node(又叫control node), 具体的优化和传统的关系型数据库很相似, 涉及到了索引, 统计信息等概念. MPP有shared everything /Disk / Nothing之别.
举例来说说区别:
比如一张销售表, 其中有一列产品类别, 现在要知道各个产品类别的总销量.
| 类别a | 1 |
| 类别a | 2 |
| 类别b | 3 |
| 类别b | 1 |
| 类别c | 4 |
MR处理方法: 在map阶段, 将不同的类别的数据map到不同的slaver处理,在统计各个类别总销量, 然后shuffle到 reduce节点阶段生成结果。
MPP处理方法: 每个节点统计各自存储的数据中各个类别总销量, 汇总结果到leader node, leader做个合并,在这个案例里就是做几次加法
可以看到在这个场景中MPP的效率绝对比MR高的多, MPP的每个节点直接处理存储在自身上的数据,而MR则有一个网络分发的过程。
在实际应用中的确MPP有更高的效率, 所以对于结构化的大数据, MPP至今仍是首选.
正如开头所说,MR的意义在于它是编程模型,相比MPP,它们能处理更加复杂的问题。
MR能自己开发Map、Reduce的代码,不受SQL语法限制。相比于SQL屈指可数的几个聚合函数(sum, avg, max, rank...),MR能随心所欲地开发出各种处理数据的逻辑,把数据分布到不通的节点上去计算。
以下为转载:
Shared Everything:一般是针对单个主机,完全透明共享CPU/MEMORY/IO,并行处理能力是最差的,典型的代表SQLServer
Shared Disk:各个处理单元使用自己的私有 CPU和Memory,共享磁盘系统。典型的代表Oracle Rac, 它是数据共享,可通过增加节点来提高并行处理的能力,扩展能力较好。其类似于SMP(对称多处理)模式,但是当存储器接口达到饱和的时候,增加节点并不能获得更高的性能 。
Shared Nothing:各个处理单元都有自己私有的CPU/内存/硬盘等,不存在共享资源,类似于MPP(大规模并行处理)模式,各处理单元之间通过协议通信,并行处理和扩展能力更好。典型代表DB2 DPF和hadoop ,各节点相互独立,各自处理自己的数据,处理后的结果可能向上层汇总或在节点间流转。
我们常说的 Sharding 其实就是Share Nothing架构,它是把某个表从物理存储上被水平分割,并分配给多台服务器(或多个实例),每台服务器可以独立工作,具备共同的schema,比如MySQL Proxy和Google的各种架构,只需增加服务器数就可以增加处理能力和容量。
- 首先MPP 必须消除手工切分数据的工作量。 这是MySQL 在互联网应用中的主要局限性。
-
另外MPP 的切分必须在任何时候都是平均的 , 不然某些节点处理的时间就明显多于另外一些节点。
对于工作负载是不是要平均分布有同种和异种之分,同种就是所有节点在数据装载的时候都同时转载,异种就是可以指定部分节点专门用来装载数据(逻辑上的不 是物理上) , 而其他所有节点用来负责查询。 Aster Data 和Greenplum 都属于这种。 两者之间并没有明显的优势科研,同种的工作负载情况下,需要软件提供商保证所有节点的负载是平衡的。 而异种的工作负载可以在你觉得数据装载很慢的情况下手工指定更多节点装载数据 。 区别其实就是自动化和手工控制,看个人喜好而已。
-
另外一个问题是查询如何被初始化的。 比如要查询销售最好的10件商品,每个节点都要先计算出自己的最好的10件商品,然后向上汇总,汇总的过程,肯定有些节点做的工作比其他节点要多。
上面只是一个简单的单表查询,如果是两个表的连接查询,可能还会涉及到节点之间计算的中间过程如何传递的问题。 是将大表和小表都平均分布,然后节点计算的时候将得到的结果汇总(可能要两次汇总),还是将大表平均分布,小表的数据传输给每个节点,这样汇总就只需要一 次。 (其中一个特例可以参考后面给出的Oracle Partition Wise Join) 。 两种执行计划很难说谁好谁坏,数据量的大小可能会产生不同的影响。 有些特定的厂商专门对这种执行计划做过了优化的,比如EMC Greenplum 和 HP Vertica 。 这其中涉及到很多取舍问题,比如数据分布模式,数据重新分布的成本,中间交换数据的网卡速度,储存介质读写的速度和数据量大小(计算过程一般都会用临时表 储存中间过程)。
转载部分的原文链接:
Shared Everything和share-nothing区别_seteor的专栏-CSDN博客
数据仓库技术中的MPP_fengyuruhui123的博客-CSDN博客_mpp数据仓库
下面这段描述了MPP(Azure Data Warehouse)中怎么把一张大表分布到各个节点上(Dedicated SQL pool (formerly SQL DW) architecture - Azure Synapse Analytics | Microsoft Docs):
Hash-distributed tables(转者注: 在可能经常要filter或join的列上用hash来分布)
A hash distributed table can deliver the highest query performance for joins and aggregations on large tables.
To shard data into a hash-distributed table, SQL Data Warehouse uses a hash function to deterministically assign each row to one distribution. In the table definition, one of the columns is designated as the distribution column. The hash function uses the values in the distribution column to assign each row to a distribution.
The following diagram illustrates how a full (non-distributed table) gets stored as a hash-distributed table.

- Each row belongs to one distribution.
- A deterministic hash algorithm assigns each row to one distribution.
- The number of table rows per distribution varies as shown by the different sizes of tables.
There are performance considerations for the selection of a distribution column, such as distinctness, data skew, and the types of queries that run on the system.
Round-robin distributed tables (转者注: 纯随机分布)
A round-robin table is the simplest table to create and delivers fast performance when used as a staging table for loads.
A round-robin distributed table distributes data evenly across the table but without any further optimization. A distribution is first chosen at random and then buffers of rows are assigned to distributions sequentially. It is quick to load data into a round-robin table, but query performance can often be better with hash distributed tables. Joins on round-robin tables require reshuffling data and this takes additional time.
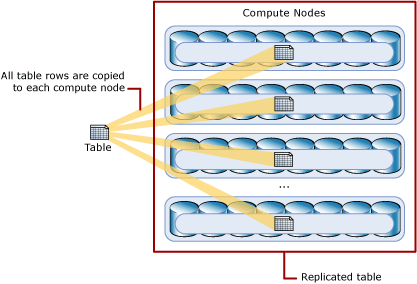
Replicated Tables (转者注: 这就类似hadoop中的分布式缓存)
A replicated table provides the fastest query performance for small tables.
A table that is replicated caches a full copy of the table on each compute node. Consequently, replicating a table removes the need to transfer data among compute nodes before a join or aggregation. Replicated tables are best utilized with small tables. Extra storage is required and there are additional overheads that are incurred when writing data which make large tables impractical.
The following diagram shows a replicated table. For SQL Data Warehouse, the replicated table is cached on the first distribution on each compute node.
下面在这篇文章里对MR的解释很好, 从原理的角度出发, map reduce其实就是二分查找的一个逆过程, 不过因为计算节点有限, 所以map和reduce前都预先有一个分区的步骤. 二分查找要求数据是排序好的, 所以Map Reduce之间会有一个shuffle的过程对Map的结果排序. Reduce的输入是排好序的.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号