大模型技术方向Task1笔记
赛题概要
一、赛事背景
在当今数字化时代,企业积累了丰富的对话数据,这些数据不仅是客户与企业之间交流的记录,更是隐藏着宝贵信息的宝库。在这个背景下,群聊对话分角色要素提取成为了企业营销和服务的一项重要策略。
群聊对话分角色要素提取的理念是基于企业对话数据的深度分析和挖掘。通过对群聊对话数据进行分析,企业可以更好地理解客户的需求、兴趣和行为模式,从而精准地把握客户的需求和心理,提供更加个性化和优质的服务。这不仅有助于企业更好地满足客户的需求,提升客户满意度,还可以为企业带来更多的商业价值和竞争优势。
群聊对话分角色要素提取的研究,将企业对话数据转化为可用的信息和智能的洞察,为企业营销和服务提供了新的思路和方法。通过挖掘对话数据中隐藏的客户行为特征和趋势,企业可以更加精准地进行客户定位、推广营销和产品服务,实现营销效果的最大化和客户价值的最大化。这将为企业带来更广阔的发展空间和更持续的竞争优势。
二、赛事任务
从给定的<客服>与<客户>的群聊对话中, 提取出指定的字段信息,待提取的全部字段见下数据说明。
三、评审规则
1.平台说明
参赛选手需基于讯飞星火大模型V3.5完成任务。允许使用大模型微调的方式进行信息抽取, 但微调的基座模型仅限星火大模型。
关于星火V3.5资源,组委会将为报名参赛选手统一发放API资源福利,选手用个人参赛账号登录讯飞开放平台:https://www.xfyun.cn/ ,前往控制台中查看使用。关于微调训练资源,选手用参赛账户登陆大模型训练平台( https://training.xfyun.cn/overview ),可领取本次比赛的训练资源福利。
2.数据说明
赛题方提供了184条真实场景的群聊对话数据以及人工标注后的字段提取结果,其中训练数据129条,测试数据 55条。按照各类字段提取的难易程度,共设置了1、2、3三种难度分数。待提取的字段以及提取正确时的得分规则如下:
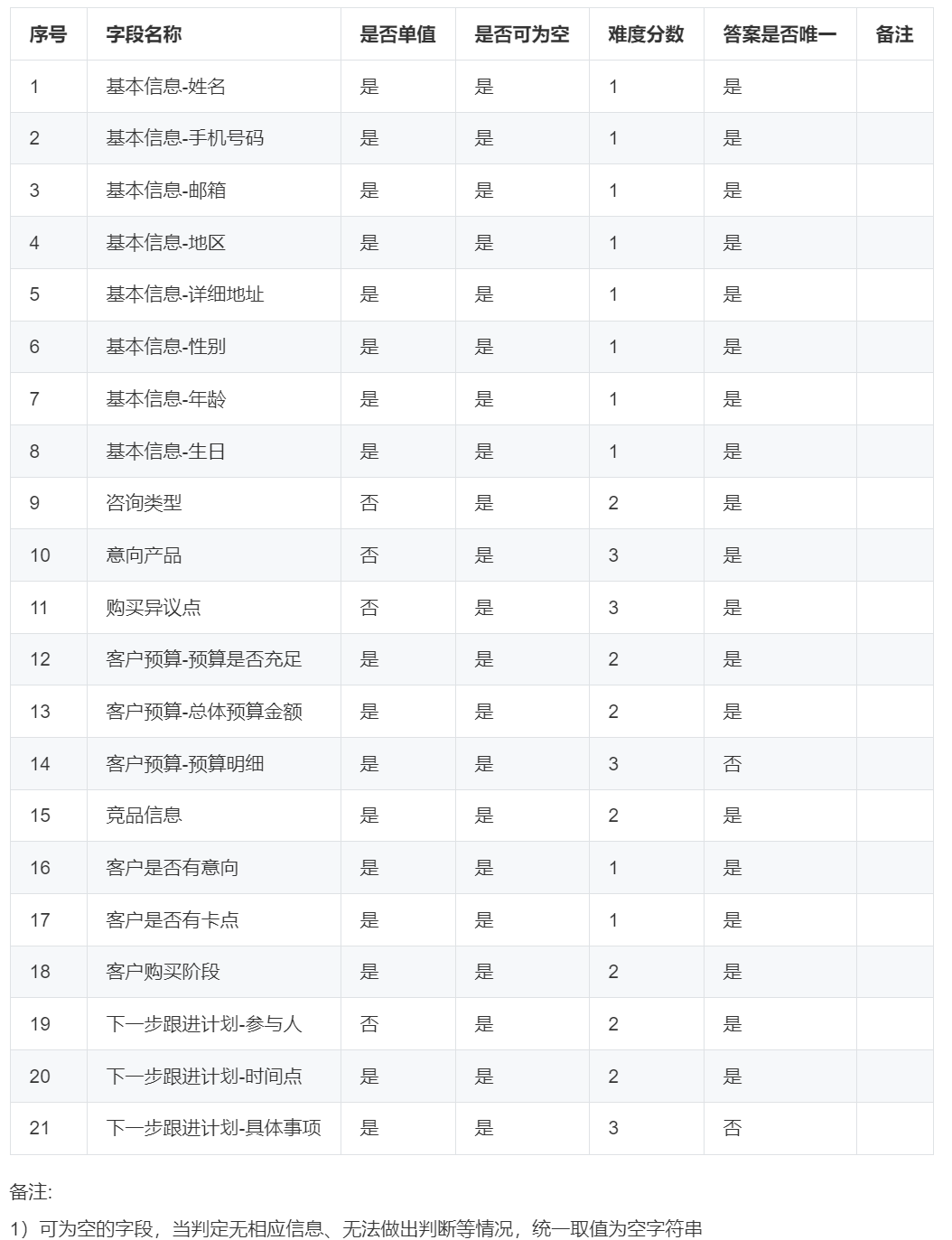
备注:
1)可为空的字段,当判定无相应信息、无法做出判断等情况,统一取值为空字符串
2)对于非单值字段,请使用list来表示
3.评估指标
测试集的每条数据同样包含共21个字段, 按照各字段难易程度划分总计满分36分。每个提取正确性的判定标准如下:
1)对于答案唯一字段,将使用完全匹配的方式计算提取是否正确,提取正确得到相应分数,否则为0分
2)对于答案不唯一字段,将综合考虑提取完整性、语义相似度等维度判定提取的匹配分数,最终该字段得分为 “匹配分数 * 该字段难度分数”
每条测试数据的最终得分为各字段累计得分。最终测试集上的分数为所有测试数据的平均得分。
4.评测及排行
1)本赛题均提供下载数据,选手在本地进行算法调试,在比赛页面提交结果。
2)排行按照得分从高到低排序,排行榜将选择团队的历史最优成绩进行排名。
赛题速通飞书
https://datawhaler.feishu.cn/wiki/VIy8ws47ii2N79kOt9zcXnbXnuS
跑通baseline
成绩是18.06061,跑的还是比较艰难,报错好几次
构思idea,改进baseline
由于还是初学者,不太了解,在网上找了一点
- 可以考虑使用并发处理来加速对大数据集的处理。使用concurrent.futures模块或multiprocessing模块来并行化任务。
- 增加单元测试和集成测试,确保代码的可靠性和稳定性。
具体还是根据后面的学习精进

 浙公网安备 33010602011771号
浙公网安备 33010602011771号