
PHP09 字符串和正则表达式
学习要点
- 字符串处理简介
- 常用的字符串输出函数
- 常用的字符串格式化函数
- 字符串比较函数
- 正则表达式简介
- 正则表达式语法规则
- 与perl兼容的正则表达式函数
字符串处理介绍
Web开发中字符串处理的工作量大概占到30%左右。原因是web系统客户端和服务器之间传输的数据格式基本上都是字符串。
字符串的处理方式
- PHP中的字符串是一种基本数据类型
- 默认只支持256个字符。不支持本地Unicode
- 一个GB2312编码汉字占用2个字节,而UTF-8编码汉字占3个字节。
- PHP提供了字符串处理函数和正则表达式。优先使用字符串处理函数。
字符串类型的特点
- 标量类型一般可以自动转换成字符串类型,直接应用于字符串处理函数。
echo substr("1234567", 2,4);//输出3456 子字符串
echo '<br>====<br>';
echo substr(1234567, 2,4);//输出3456
echo '<br>====<br>';
echo hello;//输出hello
echo '<br>====<br>';
echo true;//输出1
echo '<br>====<br>';
echo false;//输出null
- PHP把字符串当成“数组”处理,当作字符集合。操作数组的函数不适用于操作字符串。
$str="hello lamp";
echo $str;
//php4之前版本输出字符
echo $str[0];//输出h
echo $str[4];//输出o
//php4之后版本输出字符
echo $str{0};//输出h
echo $str{4};//输出o
- 字符转字符编码函数:ord()和chr()
双引号中变量解析总结
1、输出数组元素,下标或者索引不要添加单引号。
2、如果数组元素索引添加了单引号,则数组元素采用{}标识。
3、属性和变量在字符串中的解析规则一致,建议使用{}标识。
4、特例:
echo "{\$";//输出{$
常用字符串输出函数
常用字符串输出函数
|
printf()函数中常用的字符串转换格式
|
Sprintf格式 |
功能描述 |
|
%% |
返回百分比 |
|
%b |
二进制 |
|
%c |
依照ASCII值的字符 |
|
%d |
带符号十进制数 |
|
%e |
科学计数法(比如1.5e+3) |
|
%u |
无符号十进制数 |
|
%f |
浮点数(local setting aware) |
|
%F |
浮点数(not local setting aware) |
|
%o |
八进制数 |
|
%s |
字符串 |
|
%x |
十六进制数(小写字母) |
|
%X |
十六进制数(大写字母) |
语法格式:
printf(format,arg1,arg2,…argn) format:带有格式化参数的字符串。 argn:插入%符号处的参数
例如:
$str = "LAMP"; // 声明一个字符串数据 $number = 789; // 声明一个整型数据
// 将字符串$str在第一个参数中的%处输出,按%s的字符串输出,整型$number按%u输出
printf ( "%s book. page number %u <br>", $str, $number );
printf ( "%0.3f <br>", $number ); // 将整型$number按浮点数输出,并在小数点后保留3位
$format = "The %2\$s book contains %1\$d pages.
That's a nice %2\$s full of %1\$d pages. <br>"; // 定义一个格式并在其中使用占位符,占位符: \$
printf ( $format, $number, $str ); //按格式的占位符号输出多次变量,%2$s位置处是第三个参数
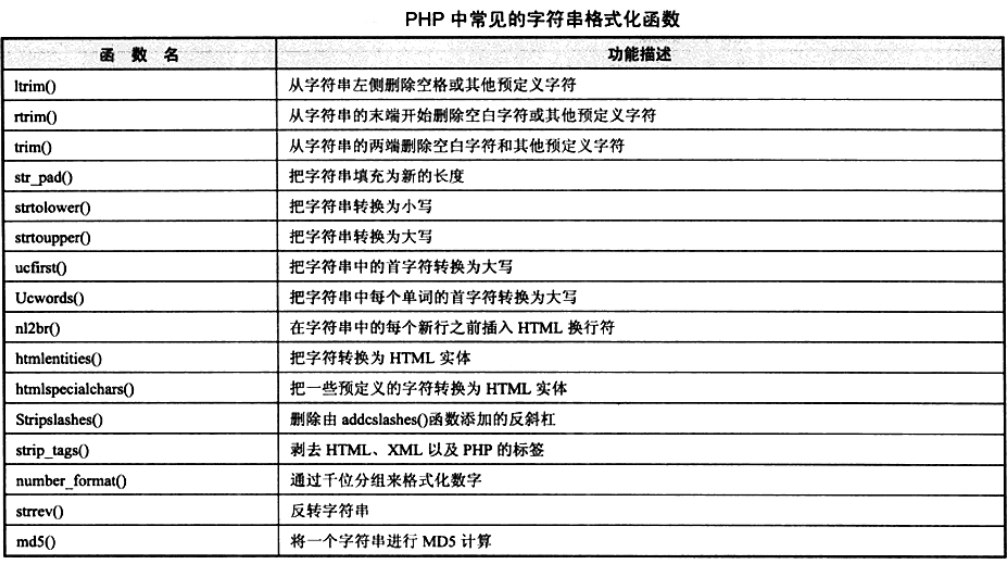
常用的字符串格式化函数
字符串比较函数
按字节顺序进行字符串比较
strcmp(),strcasecmp();
按自然排序进行字符串比较
strnatcmp(),strnatcasecmp();
正则表达式简介
PHP支持两套正则表达式的处理函数库。
- PCRE:以preg_前缀命名的函数
- POSIX:以ereg_为前缀命名的函数
正则表达式语法规则
示例
$pattern='/<a.*?(?: |\\t|\\r|\\n)?href=[\'"]?(.+?)[\'"]?(?:(?: |\\t|\\r|\\n)+.*?)?>(.+?)<\/a.*?>/sim';
$content="请进单击进入<a href='http://www.brophp.com'>LAMP兄弟连</a>技术社区。";
if(preg_match($pattern, $content)) { //使用preg_match()函数进行正则表达式的模式匹配
echo "成功匹配,在第二个参数中包含有效的HTML链接标签字符串。";
} else {
echo "在第二个参数的字符串中搜索不到有效的HTML链接标签。";
}
定界符
/^ $/ @ @
除了字母、数字和反斜杠”\”以外的任何字符都可以作为定界符。
原子
/a/
- 普通字符:a-z、A-Z、0-9
- 特殊字符:需要在特殊字符前面加”\”取消转义。例如\”、\*等等
例如:
/\./ --匹配. / \<br \/ \> / --匹配<br/>
- 非打印字符:空格、回车、制表符
/\n/ --匹配回车或者换行 /\r\n/ --匹配回车换行
- 通用字符类型原子:\d、\D、\s、\S、\w、\W
- 自定义原子表:[]
例如:[0-9]表示匹配数字 \d
[^0-9] \D
[asp]表示匹配a或者s或者p
Index.asp index.jsp index.php
/[asp]/
除换行符以外的字符串表示:
- .*?
- .+?
元字符
|
字符 |
描述 |
|
^ |
匹配输入字符串的开始位置。如果设置了 RegExp 对象的 Multiline 属性,^ 也匹配 '\n' 或 '\r' 之后的位置。 |
|
$ |
匹配输入字符串的结束位置。如果设置了RegExp 对象的 Multiline 属性,$ 也匹配 '\n' 或 '\r' 之前的位置。 |
|
* |
匹配前面的子表达式零次或多次。例如,zo* 能匹配 "z" 以及 "zoo"。 * 等价于{0,}。 |
|
+ |
匹配前面的子表达式一次或多次。例如,'zo+' 能匹配 "zo" 以及 "zoo",但不能匹配 "z"。+ 等价于 {1,}。 |
|
? |
匹配前面的子表达式零次或一次。例如,"do(es)?" 可以匹配 "do" 或 "does" 中的"do" 。? 等价于 {0,1}。 |
|
{n} |
n 是一个非负整数。匹配确定的 n 次。例如,'o{2}' 不能匹配 "Bob" 中的 'o',但是能匹配 "food" 中的两个 o。 |
|
{n,} |
n 是一个非负整数。至少匹配n 次。例如,'o{2,}' 不能匹配 "Bob" 中的 'o',但能匹配 "foooood" 中的所有 o。'o{1,}' 等价于 'o+'。'o{0,}' 则等价于 'o*'。 |
|
{n,m} |
m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。刘, "o{1,3}" 将匹配 "fooooood" 中的前三个 o。'o{0,1}' 等价于 'o?'。请注意在逗号和两个数之间不能有空格。 |
|
? |
当该字符紧跟在任何一个其他限制符 (*, +, ?, {n}, {n,}, {n,m}) 后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。例如,对于字符串 "oooo",'o+?' 将匹配单个 "o",而 'o+' 将匹配所有 'o'。 |
|
. |
匹配除 "\n" 之外的任何单个字符。要匹配包括 '\n' 在内的任何字符,请使用象 '[.\n]' 的模式。 |
|
\b |
匹配一个单词边界,也就是指单词和空格间的位置。例如, 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。 |
|
\B |
匹配非单词边界。'er\B' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'。 |
|
(pattern) |
匹配pattern 并获取这一匹配。所获取的匹配可以从产生的 Matches 集合得到,在VBScript 中使用 SubMatches 集合,在Visual Basic Scripting Edition 中则使用 $0…$9 属性。要匹配圆括号字符,请使用 '\(' 或 '\)'。 |
|
x|y |
匹配 x 或 y。例如,'z|food' 能匹配 "z" 或 "food"。'(z|f)ood' 则匹配 "zood" 或 "food"。 |
|
[xyz] |
字符集合。匹配所包含的任意一个字符。例如, '[abc]' 可以匹配 "plain" 中的 'a'。 |
|
[^xyz] |
负值字符集合。匹配未包含的任意字符。例如, '[^abc]' 可以匹配 "plain" 中的'p'。 |
|
[a-z] |
字符范围。匹配指定范围内的任意字符。例如,'[a-z]' 可以匹配 'a' 到 'z' 范围内的任意小写字母字符。 |
|
[^a-z] |
负值字符范围。匹配任何不在指定范围内的任意字符。例如,'[^a-z]' 可以匹配任何不在 'a' 到 'z' 范围内的任意字符。 |
与perl兼容的正则表达式函数
函数preg_match()
函数perg_match_all()
函数preg_grep()
函数perg_replace()
函数str_replace()
函数preg_split()
函数explode()
函数implode()
文章发布操作(自学内容)
本博客文章未经许可,禁止转载和商业用途!
如有疑问,请联系: 2083967667@qq.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号