
李宏毅课程笔记
机器学习模型
@(实验室)[笔记]
学习资料
https://datawhalechina.github.io/leeml-notes
李宏毅机器学习课笔记
https://www.bilibili.com/video/av59538266/?p=6
李宏毅课程的视频
问题类型:regression(预测),classification(分类),structured(比如机器翻译、语音识别合成等等)
监督式、半监督、无监督、reinforcement learning(不是给出正确结果而是给出分数/反馈)
回归一节有学习率的定义。更新参数的方法有:梯度下降。
其中正则化的好处:虽然加入更多特征,但其中一些特征权值过高就会过拟合。
p5error来自哪里?
bias 和variance (偏差和方差)。
比较简单的模型不容易受到训练数据的影响,但是表达能力有限,不能够结合更多的特征。(欠拟合),距离真实的function比较远。
梯度下降要注意的
- 调节learning rate。如果太小,loss下降缓慢。如果太大,可能loss爆炸,或者来回震荡无法下降。如果参数很多,可以visualize参数的变化与loss变化。
- 自动调节learning rate。学习率随着学习过程要越来越小。最好给不同参数不同的learning rate,一个方法是:adagrad:
w是参数,g是偏微分值,σ是过去所有偏微分值的均方根值。
均方根:N个数的平方和除以N后开方。
最后约简公式:


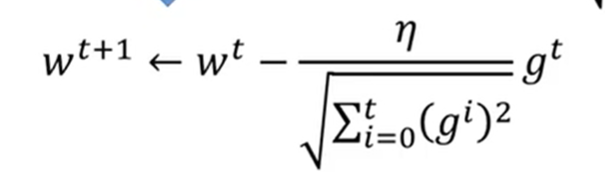
- 更快的梯度下降——stochastic:loss只对一个example进行计算,训练一个example就update一次参数。
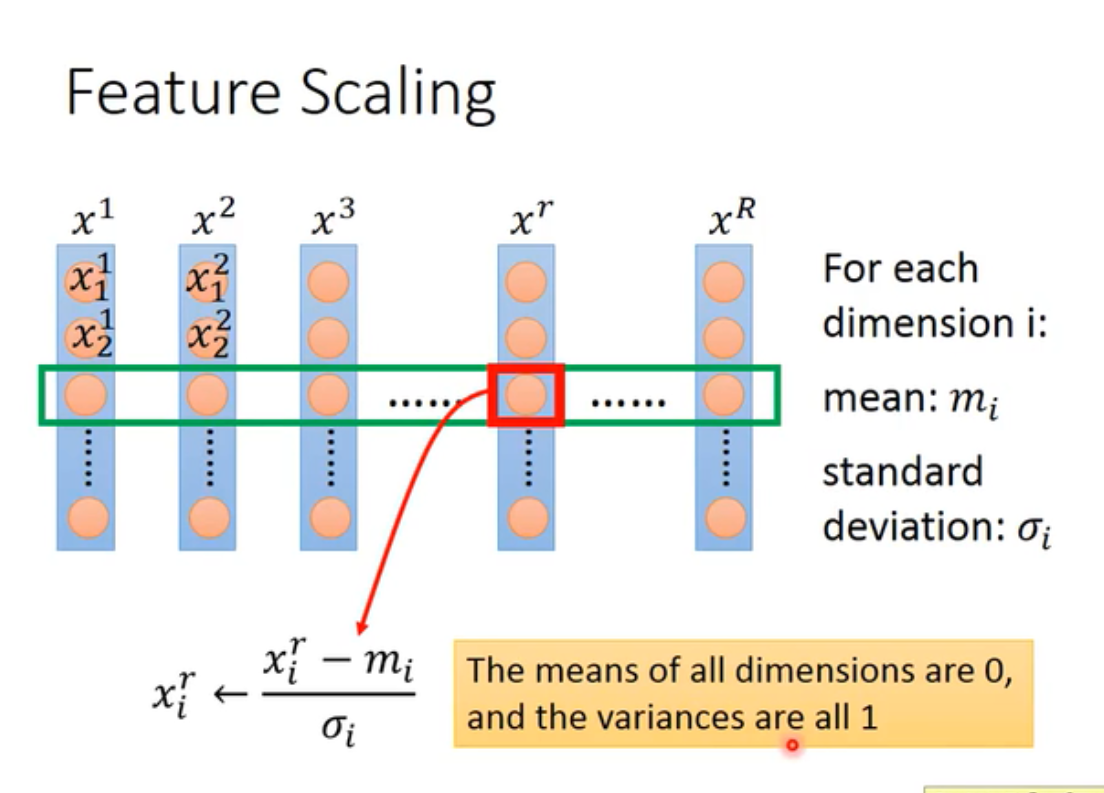
- feature scaling: 如果不同特征值分布的范围很不一样,可以对输入的特征值做rescale使得分布范围一样。这样,会使参数对loss的图形比较像个“圆”,因为参数变化是顺着等高线的,所以圆比椭圆更快。方法:
- 梯度下降的数学原理!泰勒展开。泰勒定理。保证正确的前提是,移动的步伐要很小!
分类问题:
- 二元分类:方程的结果用》/《0来划分。loss可以是这个方程在训练集中分类错误的次数。 找到最佳参数的方法: perceptron/SVM。
- 或者 概率分类模型 高斯分布有两个参数μ和Σ,如果调整参数,就可以让一个类的feature分布在这个高斯分布的中心。参数越好,在高斯分布下的特征就会有更高的概率。
要防止overfitting,所以可以给所有的高斯分布都用一个Σ(但是μ不同),取极值的Σ就是所有Σ的加权和。
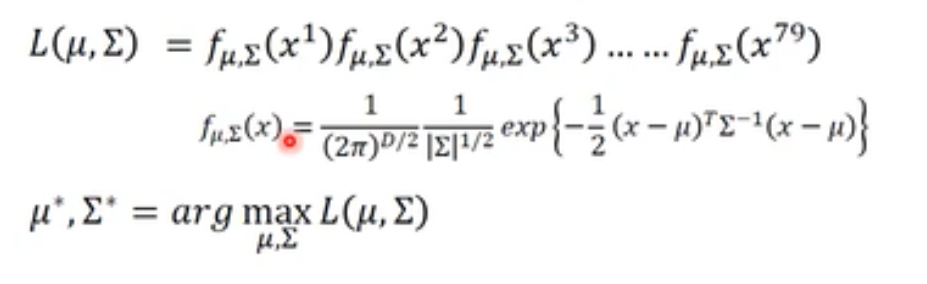
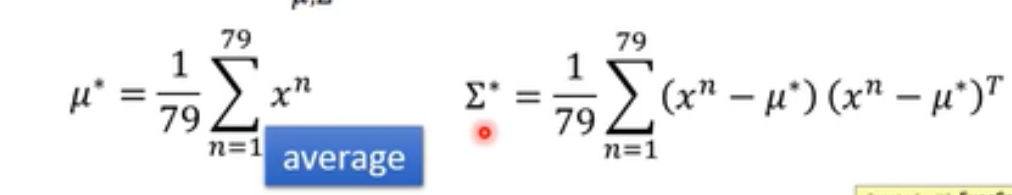
- sigmoid函数:上面的概率模型化简之后,会变成sigmoid函数fz,z又可以化简为线性的WX+B(所以就是用了同一个Σ之后,概率模型就是线性的)。→逻辑回归。
-
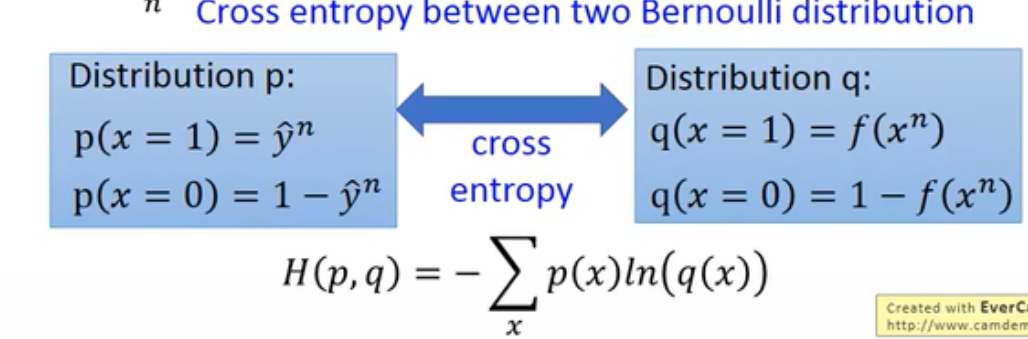
逻辑回归的loss方程!就是交叉熵

按照概率模型,就是要找到w、b,使得这个方程得到trainingdata的概率最大。二分类,当方程表示是C1的概率时,用1表示C1,0表示C2,所有项可以写成一样的,然后相加。:
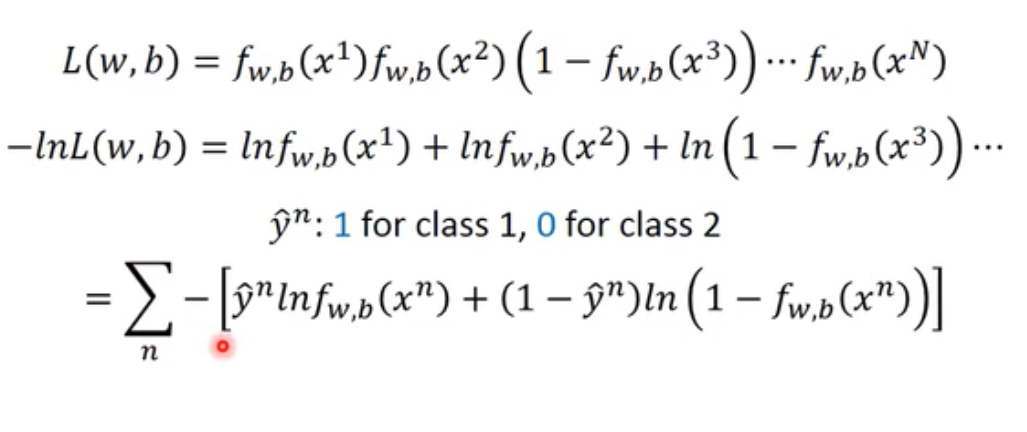
该方程即 Cross entropy between two Bernoulli distribution
得到这个LOSS方程后,也可以用梯度下降来优化参数。首先要对w求偏微分:(w是i维的向量,因为每一个x有i个输入特征)
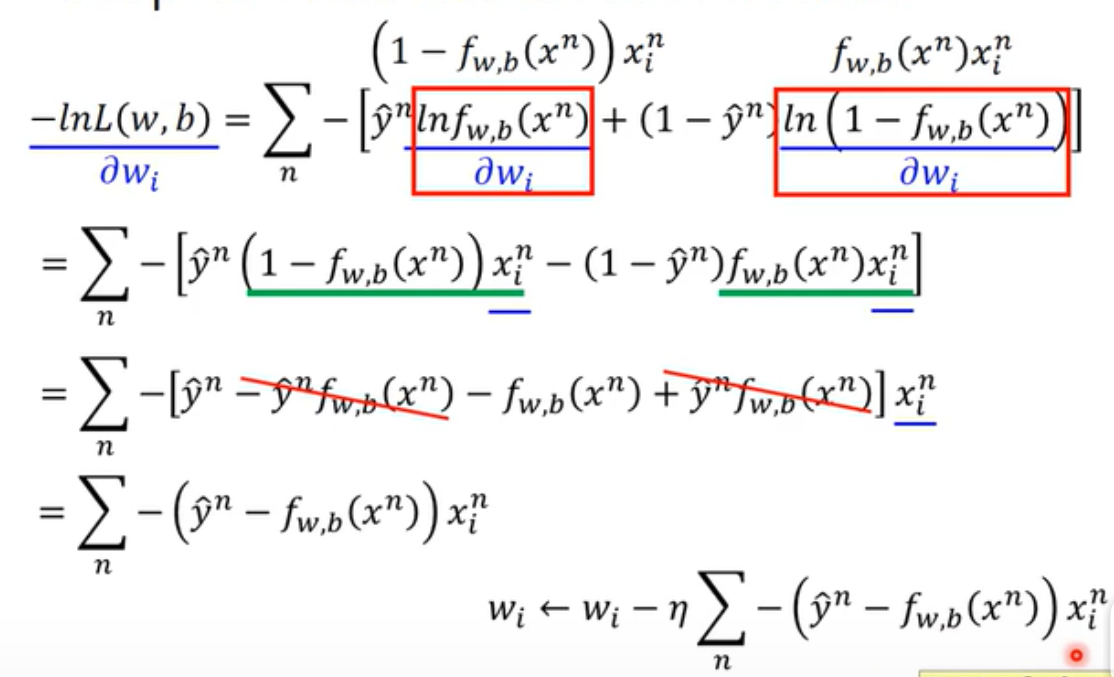
求出来的梯度下降公式,和linear regression是一模一样的!
- 多个类别的分类:方法差不多,softmax:
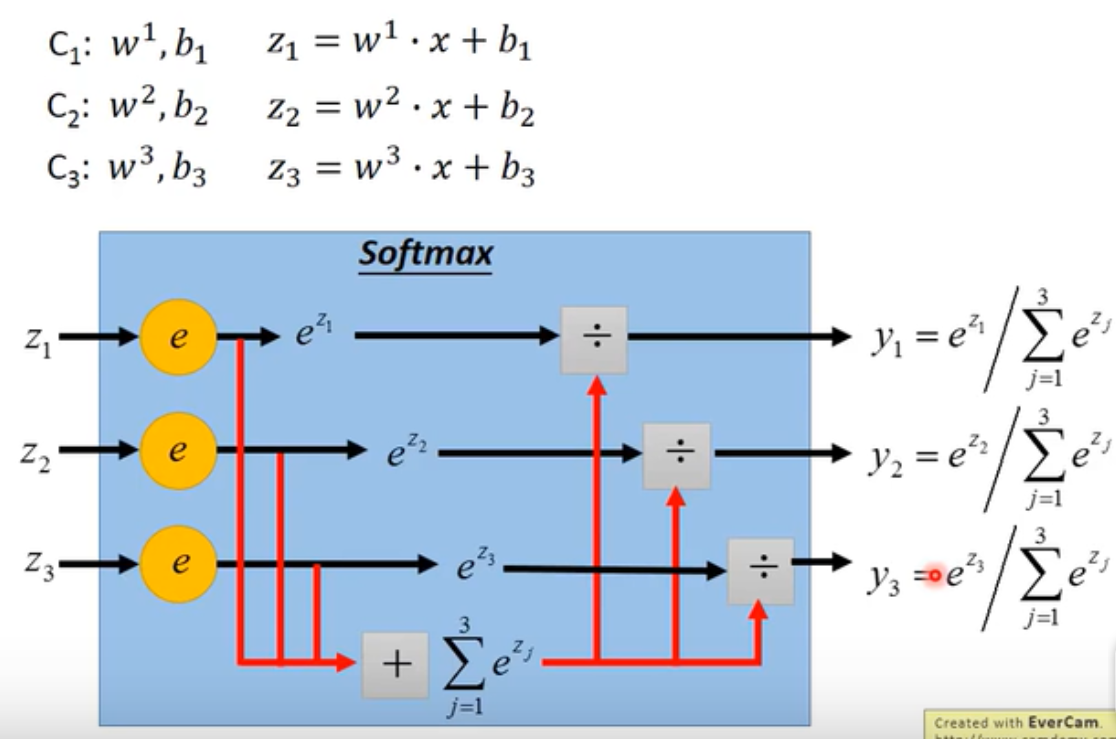
作用就是,output出来的z值限制在[0,1]之间。把大的值和小的值之间的差距拉得更开,强化。经过softmax之后,就是属于某一个类别的概率(分数)。
这个方法的推导,可以有两种角度,一个是假设数据是高斯分布,然后用高斯分布推导出softmax的公式来;另一个是通过maximum entropy的角度。
他的loss函数也是交叉熵:
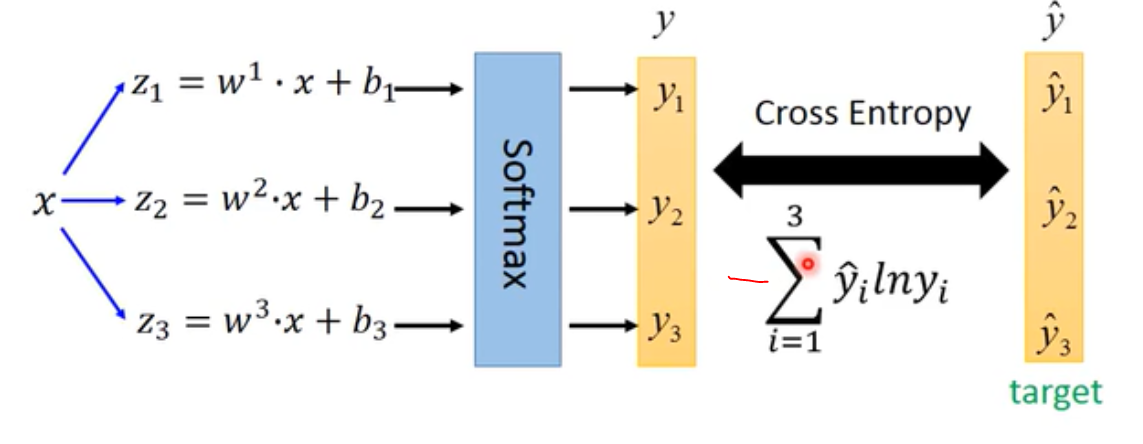
- 如果特征的分布使得用logistic回归不能用直线把类别分开,可以转化feature。
- 让机器自己做feature transformation: 级联的logistic回归。而,一个logistic regression单元,就叫做一个神经元
深度学习
连接各个神经元的方法:
- fully connected feedforward network,几乎跟之前一样,把神经元用不同方式连接,就有不同的网络结构。神经元那里的函数,已经不常用sigmoid了。最后一层仍然还是一个softmax,得到网络的输出。
- loss也和之前一样,分类问题就是算yhead 和y的交叉熵,然后对整个训练集的例子求总和。
- 求参数的方法也用梯度下降,算微分可以用back propagation向后传播的方法。向后传播:

如图,就是利用求微分的链式规则,从最后一层逐步向后传递直到输入层,求微分。(其中的C是y和yhead的距离(一般是交叉熵))。z,是某一个神经元的线性函数的结果。如果已经到输出层前一个hidden layer,那就直接是
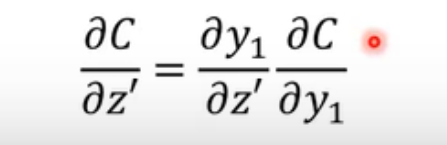
否则就是递归计算。(实际操作肯定是从最后一层往前算)
卷积神经网络
为什么用卷积网络?
- 卷积,可以使深度学习的参数减少。卷积层的原理是,一个整体是由很多小的局部特征构成的,这些特征在图上不同的位置出现效果/意义都是一样的,所以检测这样的小特征的神经元,不需要连接整张图的像素,只要连一小块的区域。
- 检测同样特征的神经元,在图像的不同位置参数都是一样的,这就相当于在神经元之间share参数,可以让参数减少。
- 将图片去掉一些像素看起来也没有什么影响(pooling,也可以减少参数)。
conv
矩阵的内积。点积结果最大的那个值,可以表示该特征在图像的这个位置出现。

移动距离为stride。用不同的filter做卷积,有多少个卷积核,就会得到多少层的特征图。卷积核的厚度总是和输入的图一样。如果是RGB值,是同时考虑三个通道的。
卷积网络实际上就是一个fully connected network,拿掉一些w的结果,(但它不是全连接,而是每个神经元只连对应一部分的像素)。

同一个卷积核生成的神经元共享同一组参数。
maxpooling
[2,2]的pooling,把4个value中最大的值保留。图片缩小一半。
flatten
就是把所有的featuremap 拉直成一维的,然后丢进最后的全连接层,综合检测到的所有局部特征。
activation
一个特征检测器被激活的概念是,它得到的feature map里面,所有分数的和最大。
激活程度就是这个特征的分数总和。
什么时候用CNN比较好?
具有之前所说的特性:
- 一些特征比整个图像小很多
- 这些特征可以出现在不同的区域,但是不影响结果。
异常侦测
异常侦测一般不可以看成是两个类的分类问题,因为一般~x是无穷的,无法穷举。
训练数据:分为干净的和污染的;大多数情况下都是有污染的训练数据,并非所有训练数据都是正常情况。label和没有label的: 有label的可以看作是一种open-set的分类模型,就是它可以识别出训练集中没有出现的东西,然后给出unknown标签。
- 有label的训练资料例子:辛普森一家(有名字),有辛普森一家的训练资料,可以做一个分类器,输出是分类还有置信分数,如果每个类的分数都很低/ 交叉熵很大(说明分布得很平均,代表机器无法分辨这是哪个例子,就说明这是异常数据。
这里dev set是在模型的研究过程中来判断这个模型的好坏的,一定要包括在该分类中的,和不在任何分类中的异常数据,然后看两者的置信分数分布是不是有很大的差距。通过dev set,可以调节threshold λ的值。异常侦测系统好坏的判断?
不止要看正确率,因为一个系统可以啥也不做,但是正确率很高(异常数据本来占比就很小)。异常侦测有两种正确率:错的判成对的&对的判成错的。所以可以给missing 和 false alarm 不同的cost,来权衡这两种错误。


没有label的举例:
检测twitch玩家中的小白
可以收集玩家的行为,建立一个generative模型(概率模型),如果某种行为的概率高于/低于λ就认为是异常的:

Explainable ML
定义: 不仅可以(分类),还要输出分类的理由是什么(局部),以及某一个分类的判断标准(全局)
- 局部: silence map. 把{x1.....xn}中每一个像素加一个偏移量之后,得到的y偏移量与x偏移相除,类似于微分的结果,表示成一张图片。可以看到图片上对与判断结果来说重要的部分。
- 全局: 对某个分类,可以找出使它信心分数最高的x(要加一些regularization),可以画出机器“看到”的样子。
什么是全连接层?
全连接层不是必要的,经常替换成全卷积。
fully connected layer -fc 在整个卷积神经网络中起到“分类器”的作用。如果说卷积层、池化层和激活函数层等操作是将原始数据映射到隐层特征空间的话,全连接层则起到将学到的“分布式特征表示”映射到样本标记空间的作用。在实际使用中,全连接层可由卷积操作实现:对前层是全连接的全连接层可以转化为卷积核为1x1的卷积;而前层是卷积层的全连接层可以转化为卷积核为hxw的全局卷积,h和w分别为前层卷积结果的高和宽。
全连接层参数冗余,但是全连接层可以保证模型表示能力的迁移。(https://www.zhihu.com/question/41037974)
https://blog.csdn.net/zfjBIT/article/details/88075569
感受野?
一个像素可以表示原输入图像几个像素的信息。前面的卷积层感受野小,可以捕捉到局部细节的信息,即输出图像的每个像素(Activation激活值)只是感受到输入图像很小范围数值进行计算的结果。
上、下采样
下采样就是池化,上采样是相反的操作。池化层作用:
- 降维,缩减模型大小,提高计算速度
- 降低过拟合概率,提升特征提取鲁棒性
- 对平移和旋转不敏感
池化有均值池化和max池化。
白化?
白化的目的是去除输入数据的冗余信息。假设训练数据是图像,由于图像中相邻像素之间具有很强的相关性,所以用于训练时输入是冗余的;白化的目的就是降低输入的冗余性。
一幅图像最终成像会受环境照明强度、物体反射、拍摄相机等多因素的影响。为了能获得图像中包含的那些不受外界影响的恒定信息,我们需要对图像进行白化处理。(图像白化(whitening)可用于对过度曝光或低曝光的图片进行处理,处理的方式就是改变图像的平均像素值为0 ,改变图像的方差为单位方差 1。)一般为了去除这些因素的影响,我们将它的像素值转化成零均值和单位方差。所以我们首先计算原始灰度图像的像素平均值和方差值。
————————————————
版权声明:本文为CSDN博主「Dean0Winchester」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_38906523/article/details/79853984
