
Hive 1、什么是Hive,Hive有什么用
 Hive是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。
Hive是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。

一、什么是Hive
Hive是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 HQL,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。
Hive 没有专门的数据格式。 Hive 可以很好的工作在 Thrift 之上,控制分隔符,也允许用户指定数据格式。
二、Hive的应用场景
Hive 构建在基于静态批处理的Hadoop 之上,Hadoop 通常都有较高的延迟并且在作业提交和调度的时候需要大量的开销。因此,Hive 并不能够在大规模数据集上实现低延迟快速的查询,例如,Hive 在几百MB 的数据集上执行查询一般有分钟级的时间延迟。因此,Hive 并不适合那些需要低延迟的应用,例如,联机事务处理(OLTP)。Hive 查询操作过程严格遵守Hadoop MapReduce 的作业执行模型,Hive 将用户的HiveQL 语句通过解释器转换为MapReduce 作业提交到Hadoop 集群上,Hadoop 监控作业执行过程,然后返回作业执行结果给用户。Hive 并非为联机事务处理而设计,Hive 并不提供实时的查询和基于行级的数据更新操作。Hive 的最佳使用场合是大数据集的批处理作业,例如,网络日志分析。
三、Hive的体系结构
主要分为以下几个部分:
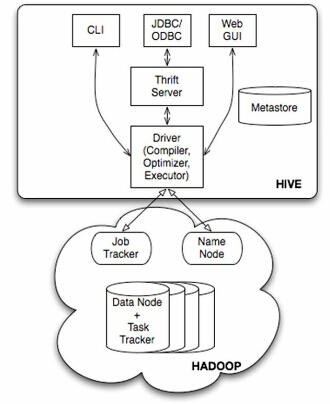
用户接口
用户接口主要有三个:CLI,Client 和 WUI。其中最常用的是 CLI,Cli 启动的时候,会同时启动一个 Hive 副本。Client 是 Hive 的客户端,用户连接至 Hive Server。在启动 Client 模式的时候,需要指出 Hive Server 所在节点,并且在该节点启动 Hive Server。 WUI 是通过浏览器访问 Hive。
元数据存储
Hive 将元数据存储在数据库中,如 mysql、derby。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
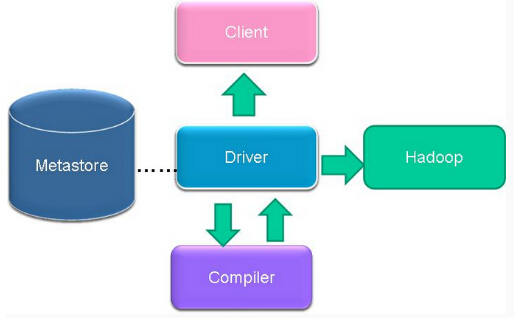
解释器、编译器、优化器、执行器
解释器、编译器、优化器完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并随后由 MapReduce 调用执行。
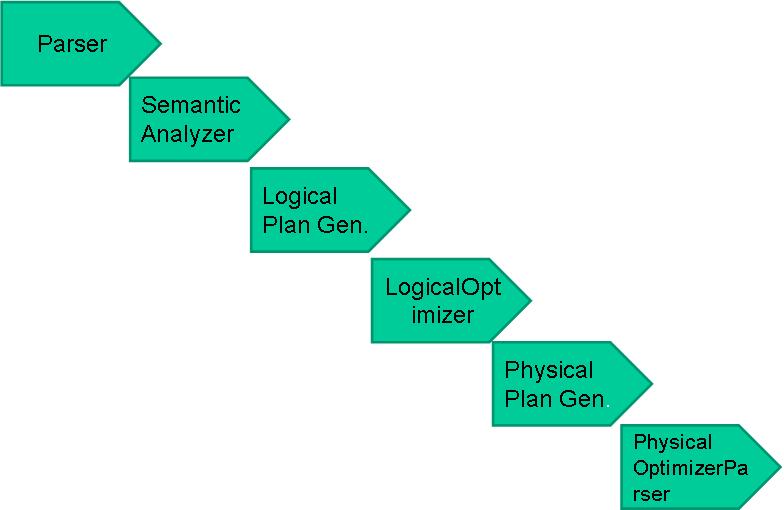
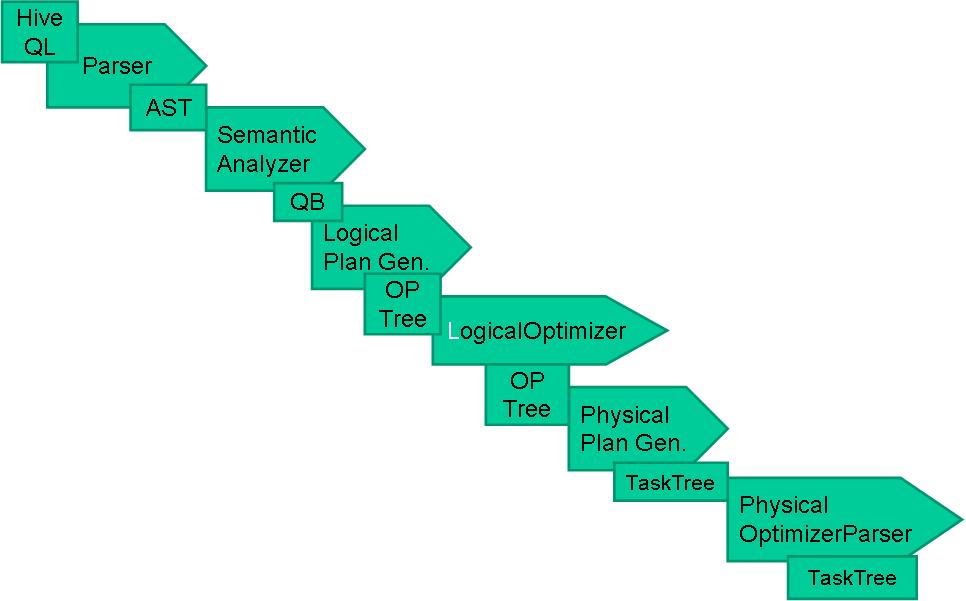
.编译器将一个Hive QL转换操作符
.操作符是Hive的最小的处理单元
.每个操作符代表HDFS的一个操作或者一道MapReduce作业
Hive编译器


编译流程
Hadoop
Hive 的数据存储在 HDFS 中,大部分的查询由 MapReduce 完成(包含 * 的查询,比如 select * from tbl 不会生成 MapReduce 任务)。
四、数据存储
首先,Hive 没有专门的数据存储格式,也没有为数据建立索引,用户可以非常自由的组织 Hive 中的表,只需要在创建表的时候告诉 Hive 数据中的列分隔符和行分隔符,Hive 就可以解析数据。
其次,Hive 中所有的数据都存储在 HDFS 中,Hive 中包含以下数据模型:表(Table),外部表(External Table),分区(Partition),桶(Bucket)。
Hive 中的 Table 和数据库中的 Table 在概念上是类似的,每一个 Table 在 Hive 中都有一个相应的目录存储数据。例如,一个表 pvs,它在 HDFS 中的路径为:/wh/pvs,其中,wh 是在 hive-site.xml 中由 ${hive.metastore.warehouse.dir} 指定的数据仓库的目录,所有的 Table 数据(不包括 External Table)都保存在这个目录中。
Partition 对应于数据库中的 Partition 列的密集索引,但是 Hive 中 Partition 的组织方式和数据库中的很不相同。在 Hive 中,表中的一个 Partition 对应于表下的一个目录,所有的 Partition 的数据都存储在对应的目录中。例如:pvs 表中包含 ds 和 city 两个 Partition,则对应于 ds = 20090801, ctry = US 的 HDFS 子目录为:/wh/pvs/ds=20090801/ctry=US;对应于 ds = 20090801, ctry = CA 的 HDFS 子目录为;/wh/pvs/ds=20090801/ctry=CA
Buckets 对指定列计算 hash,根据 hash 值切分数据,目的是为了并行,每一个 Bucket 对应一个文件。将 user 列分散至 32 个 bucket,首先对 user 列的值计算 hash,对应 hash 值为 0 的 HDFS 目录为:/wh/pvs/ds=20090801/ctry=US/part-00000;hash 值为 20 的 HDFS 目录为:/wh/pvs/ds=20090801/ctry=US/part-00020
External Table 指向已经在 HDFS 中存在的数据,可以创建 Partition。它和 Table 在元数据的组织上是相同的,而实际数据的存储则有较大的差异。
Table 的创建过程和数据加载过程(这两个过程可以在同一个语句中完成),在加载数据的过程中,实际数据会被移动到数据仓库目录中;之后对数据对访问将会直接在数据仓库目录中完成。删除表时,表中的数据和元数据将会被同时删除。
External Table 只有一个过程,加载数据和创建表同时完成(CREATE EXTERNAL TABLE ……LOCATION),实际数据是存储在 LOCATION 后面指定的 HDFS 路径中,并不会移动到数据仓库目录中。当删除一个 External Table 时,仅删除元数据,表中的数据不会真正被删除。
五、Hive的模式
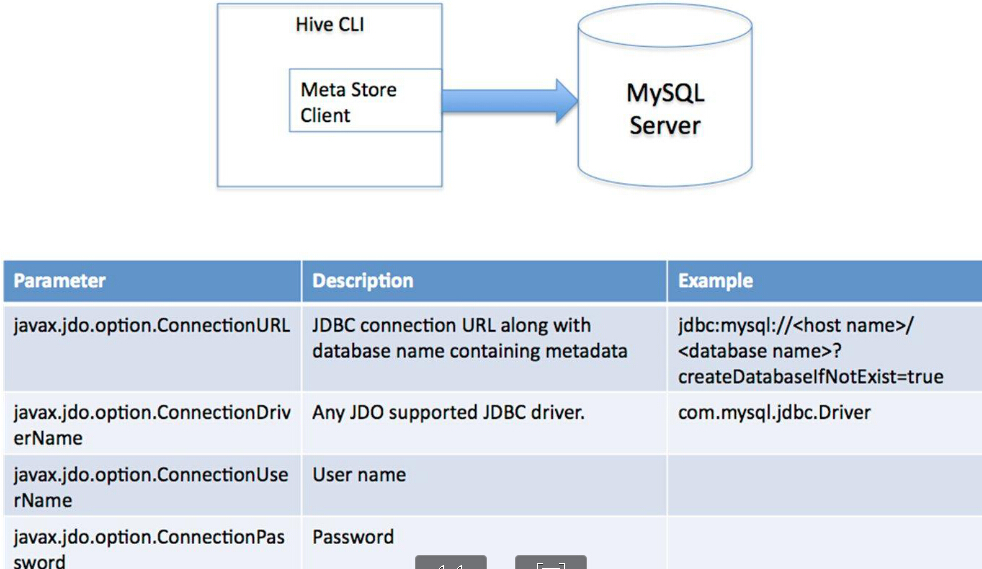
单用户数据库模式
单用户数据库模式:通过网络连接到一个数据库中,是最经常使用到的模式。
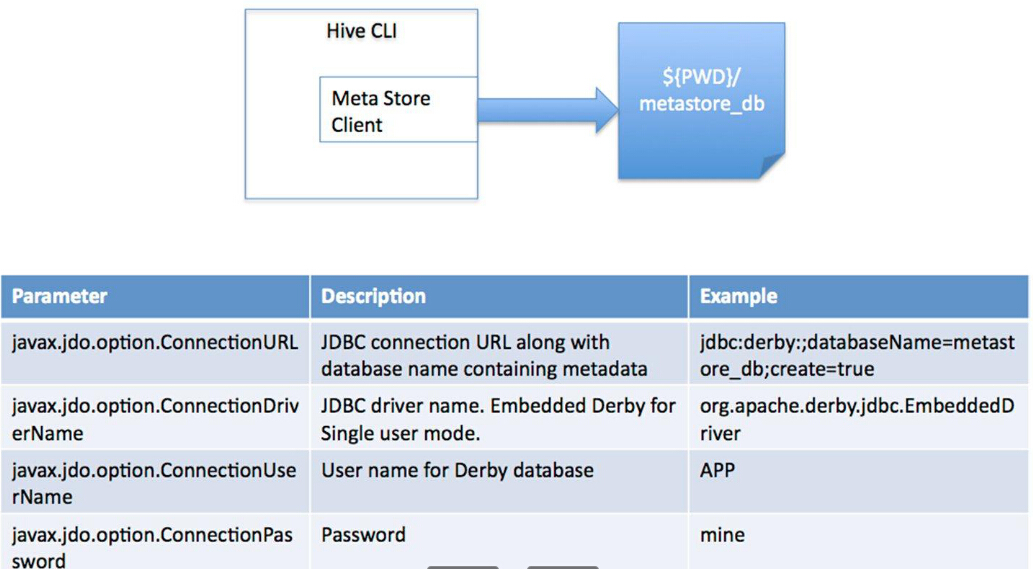
单用户Derby模式
单用户Derby模式:此模式连接到一个In-memory 的数据库Derby,一般用于Unit Test。
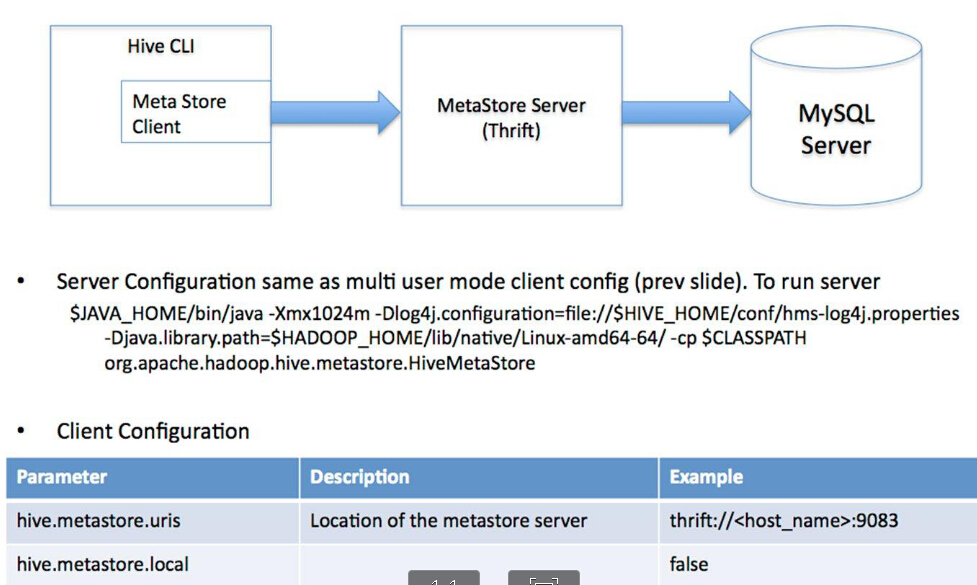
多用户远程服务器模式
多用户远程服务器模式:用于非Java客户端访问元数据库,在服务器端启动MetaStoreServer,客户端利用Thrift协议通过MetaStoreServer访问元数据库。
六、Hive执行流程
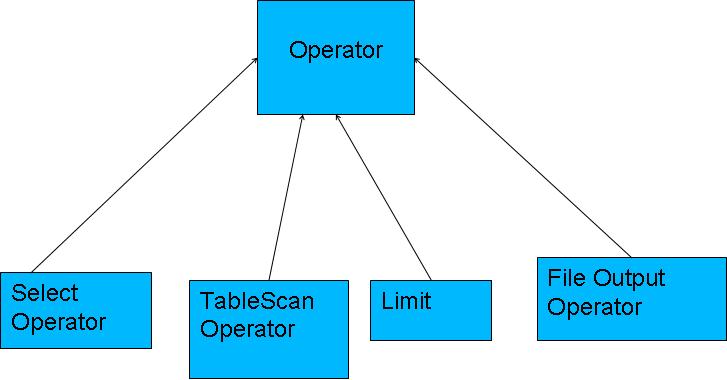
•编译器将一个Hive QL转换操作符
•操作符是Hive的最小的处理单元
•每个操作符代表HDFS的一个操作或者一道MapReduce作业
Operator
•Operator都是hive定义的一个处理过程
•Operator都定义有:
•protected List <Operator<? extends Serializable >> childOperators;
•protected List <Operator<? extends Serializable >> parentOperators;
•protected boolean done; // 初始化值为false
•所有的操作构成了 Operator图,hive正是基于这些图关系来处理诸如limit, group by, join等操作
|
操作符
|
描述
|
|
TableScanOperator
|
扫描hive表数据
|
|
ReduceSinkOperator
|
创建将发送到Reducer端的<Key,Value>对
|
|
JoinOperator
|
Join两份数据
|
|
SelectOperator
|
选择输出列
|
|
FileSinkOperator
|
建立结果数据,输出至文件
|
|
FilterOperator
|
过滤输入数据
|
|
GroupByOperator
|
GroupBy语句
|
|
MapJoinOperator
|
/*+mapjoin(t) */
|
|
LimitOperator
|
Limit语句
|
|
UnionOperator
|
Union语句
|
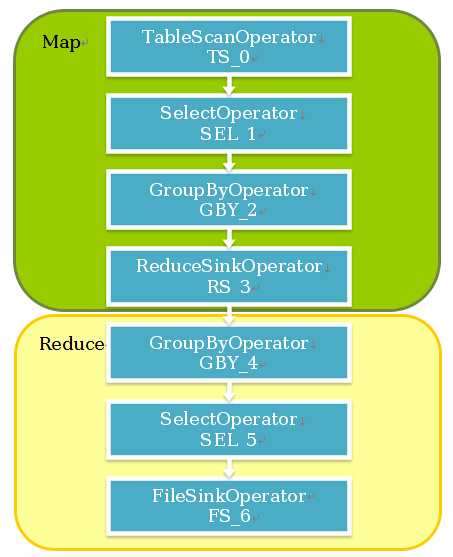
•Hive通过ExecMapper和ExecReducer执行MapReduce任务
•在执行MapReduce时有两种模式
•本地模式
•分布式模式
ANTLR词法语法分析工具
•ANTLR—Another Tool for Language Recognition
•ANTLR 是开源的
•为包括Java,C++,C#在内的语言提供了一个通过语法描述来自动构造自定义语言的识别器(recognizer),编译器(parser)和解释器(translator)的框架
•Hibernate就是使用了该分析工具
七、一条HQL引发的思考
案例HQL
•select key from test_limit limit 1
•Stage-1
•TableScan Operator>Select Operator-> Limit->File Output Operator
•Stage-0
•Fetch Operator
•读取文件
Mapper与InputFormat
•该hive MR作业中指定的mapper是:
•mapred.mapper.class = org.apache.hadoop.hive.ql.exec.ExecMapper
•input format是:
•hive.input.format = org.apache.hadoop.hive.ql.io.CombineHiveInputFormat

 浙公网安备 33010602011771号
浙公网安备 33010602011771号