SURF特征识别
如果对Surf的探究或者使用到此为止,我觉得只是用Surf这把牛刀吓唬了一个小鸡仔,万里长征才刚刚开始第一步,最少有三个问题需要得到解答:
- 1. 保存特征点信息的keyPoints向量内每个元素包含有哪些内容?
- 2. 通过comput方法生成的特征描述子是一个Mat矩阵,该Mat矩阵的结构是怎样的?
- 3. 特征点匹配后生成一个DMatch型的向量matches,这个matches里边的内容又是什么,以及如何有效操作众多匹配信息,为之后在实际中的应用做好基础?
1. 保存特征点信息的keyPoints向量内每个元素包含有哪些内容?
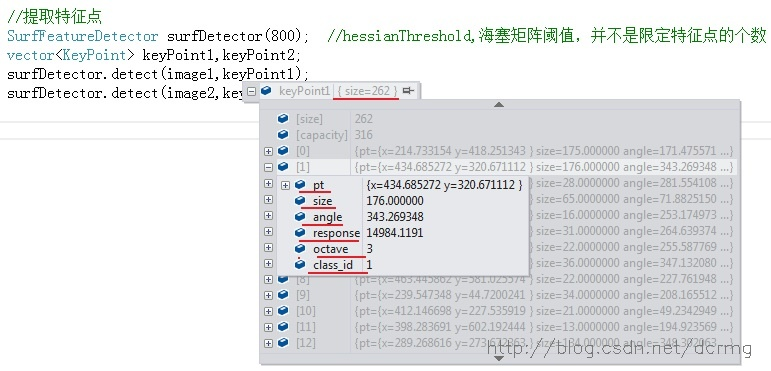
keyPoints数据结构包含的内容有:
- size1:特征点的总个数
- pt: 特征点的坐标
- size2:特征点的大小
- angle:特征点的角度
- response:特征点的响应强度,代表该点的稳健程度,可以在Surf特征探测器的含参构造函数中设置响应强度的最低阈值,如: SurfFeatureDetector surfDetector(800);
- octave:特征点所在的金字塔的哪一组
- class_id:特征点的分类
2. 通过comput方法生成的特征描述子是一个Mat矩阵,该Mat矩阵的结构是怎样的?
经过归一化后的描述子Mat矩阵显示
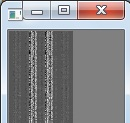
这两个长的很大条的图像就是描述子的图像显示,图像的行数是特征点的个数,上例中图像1的特征点数比图像二的少,表现出来就是图像的高度小一些。
图像的列数是描述特征点的描述子的维度数,在Surf中,维度是64,在SIft中,维度是128,所以如果使用Sift特征的话,图像应该宽两倍。
3. 特征点匹配后生成一个DMatch型的向量matches,这个matches里边的内容又是什么,以及如何有效操作众多匹配信息,为之后在实际中的应用做好基础?
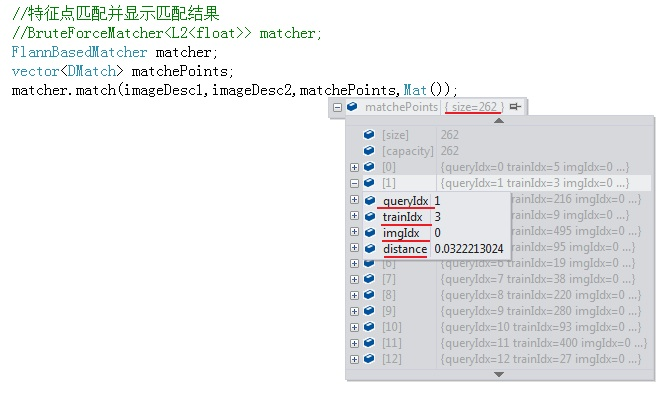
matches数据结构包含的内容有:
- size:配对成功的特征点对数
- queryIdx:当前“匹配点”在查询图像的特征在KeyPoints1向量中的索引号,可以据此找到匹配点在查询图像中的位置
- trainIdx:当前“匹配点”在训练(模板)图像的特征在KeyPoints2向量中的索引号,可以据此找到匹配点在训练图像中的位置
- imgIdx:当前匹配点对应训练图像(如果有若干个)的索引,如果只有一个训练图像跟查询图像配对,即两两配对,则imgIdx=0
- distance:连个特征点之间的欧氏距离,越小表明匹配度越高
4. 匹配特征点sort排序
sort方法可以对匹配点进行从小到大的排序: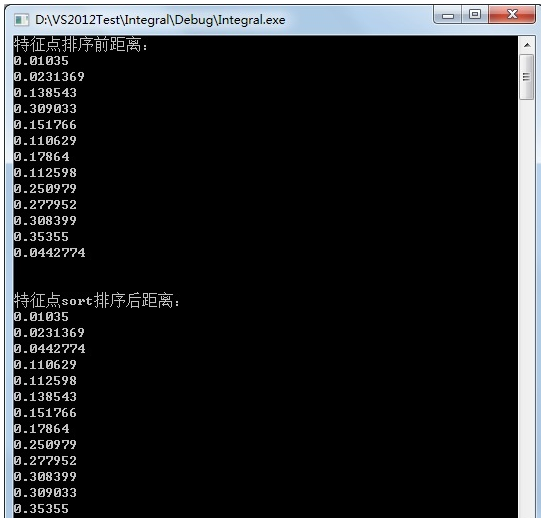
使用sort排序之前,每个匹配点对间的距离(即匹配稳健性程度)是随机分布的,排序之后,距离按由小到大的顺序排列,越靠前的,匹配度越高,可以通过排序后把靠前的匹配提取出来。
