git功能用法-全功能
工作就是玩
编写代码,或编辑文档,其实和玩游戏差不多。在你做出了很多进展之后,你最好保存一下。 要做到这点,点击编辑器的保存按钮就好了。
但这将覆盖老版本。就像那些学校里玩的老游戏,只有一个存档:你确实可以保存,但你不能回到更老的状态。这真让人扫兴,因为那个状态可能恰好保存了这个游戏特别有意思一关,说不定哪天你想再玩一下呢。或者更糟糕的事情,你当前的保存是个必败局, 这样你就不得不从头开始玩了。
版本控制
在编辑文档的时候,如果想保留旧版本,你可以将文件“另存为”一个不同的文件,或在保存之前将文件拷贝到别处。你可能会压缩这些文件以节省空间。这是一个初级的依赖手工进行的版本控制方式。游戏软件在这块早就做了很多提高,很多游戏都提供基于时间戳的多个存档。
让我们看看稍稍复杂的情况。比如你有很多放在一起的文件,比如项目源码或网站文件。现在如你想保留旧版本,你不得不把整个目录存档。手工保存多个版本很不方便, 而且很快会耗费巨大的存储空间。
在一些电脑游戏里,一个存档包含在一个充满文件的目录里。这些游戏为玩家屏蔽了一些细节,并提供一个方便易用的界面来管理该目录的不同版本。
版本控制系统也没有什么不同。提供友好的用户界面,来管理目录里的东西。你可以频繁保存,也可以在之后加载任一存档。不像大多数计算机游戏,版本控制系统通常精于节省存储空间。一般情况下,如果两个版本间只有少数文件的变更,每个文件的变更也不大,那就只存储差异的部分,而不是把全部拷贝都保存下来,以达到节省存储空间的目的。
分布控制
现在设想一个很难的游戏。太难打了,以至于世界各地很多骨灰级玩家决定组队,分享他们的游戏存档以攻克它。在同一个游戏里,玩家们分别攻克不同的等级,协同工作以创造惊人战绩。
你如何搭建一个系统,使得他们易于得到彼此的存档?并易于上传新的存档?
在过去,每个项目都使用中心式版本控制(如SVN)。在某个服务器上存放所有保存的游戏记录。其他人就不用再做备份了。每个玩家在他们的机器上最多保留几个游戏记录。当一个玩家想更新至最新进度的时候,他们需要把这个进度从主服务器下载下来,玩一会儿,保存并上传到主服务器以供其他人使用。
假如一个玩家由于某种原因,想得到一个较旧版本的游戏进度,该怎么办?或许当前保存的游戏是一个注定的败局,因为某人在第三级忘记捡某个物品;他们希望能找到最近一个可以完成的游戏记录。或者他们想比较两个旧版本间的差异,来估算某个特定玩家干了多少活。
查看旧版本的理由有很多,但检查的办法都是一样的。他们必须去中心服务器检索那个旧版本的记录。需要的旧版本越多,和服务器的交互就越多。
Git是新一代的版本控制系统中的一员,它的特点是分布式的,广义上也可以被看作是一 种中心式系统。从主服务器下载时,玩家会得到所有保存的记录,而不仅是最新版。这么看来,玩家们好像把中心服务器做了个镜像。最初的克隆操作可能比较费时,特别当存档有很长历史的时候,但从长远看这是值得的。一个显而易见的好处是,当查看一个旧版本时,就不再需要和中心服务器通讯了。
中心式版本控制:我就是仓库,我拥有全部
我们首先要明确一个git与先前的版本管理工具(主要是SVN)的不同。下面是使用SVN版本管理工具时,程序员进行代码生产以及程序员间围绕代码仓库进行协作的模式:
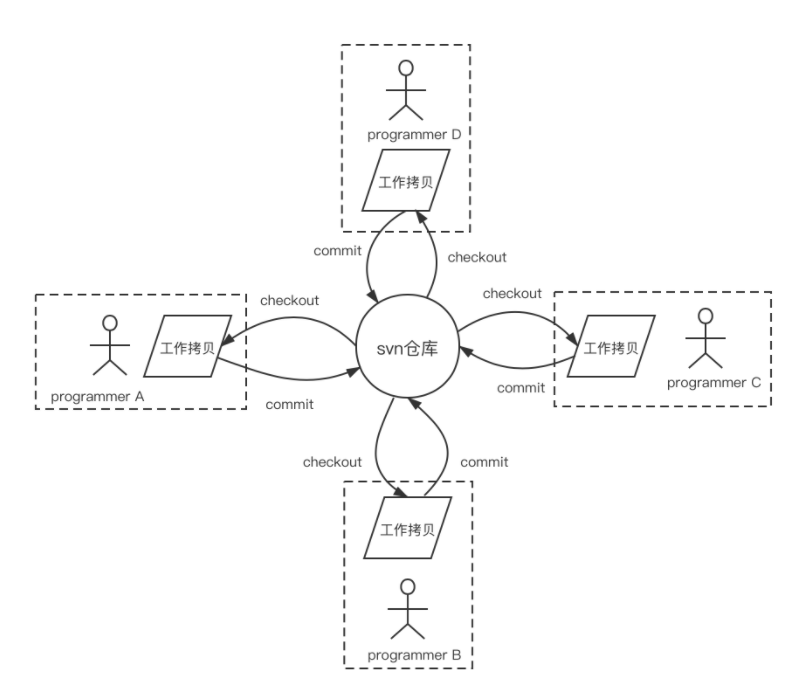
众所周知,SVN是基于中心版本仓库进行版本管理协作的版本管理工具。就像上图中那样,所有开发人员开始生产代码的前提是必须先从中心仓库checkout一份代码拷贝到自己本地的工作目录;而进行版本管理操作或者与他人进行协作的前提也是:中心版本仓库必须始终可用。这有点像以太网的“半双工的集线器(hub)模式”:SVN中心仓库就像集线器本身,每个程序员节点就像连接到集线器上的主机;当一个程序员提交(commit)代码到中心仓库时,其他程序员不能提交,否则会出现冲突;如果中心仓库挂掉了,那么整个版本管理过程也将停止,程序员节点间无法进行协作,这就像集线器(hub)挂掉后,所有连接到hub上的主机节点间的网络也就断开无法相互通信一样。
分布式版本管理
git实现了分布式版本管理系统,每个git仓库节点都是自治的。诸多git仓库节点一起形成了一个分布式git版本管理网络。这样的一个分布式网络存在着与普通分布式系统的类似的问题:如何发现对端节点的git仓库、如何管理和控制仓库间的访问权限等。如果说linus的git本身是这个分布式网络的数据平面工具(实现client/server间的双向数据通信),那么这个分布式网络还缺少一个“控制平面”。
而github恰恰给出了一份git分布式网络控制平面的实现:托管、发现、控制…。其名称中含有的“hub”字样让我们想起了上面的“hub模式”:
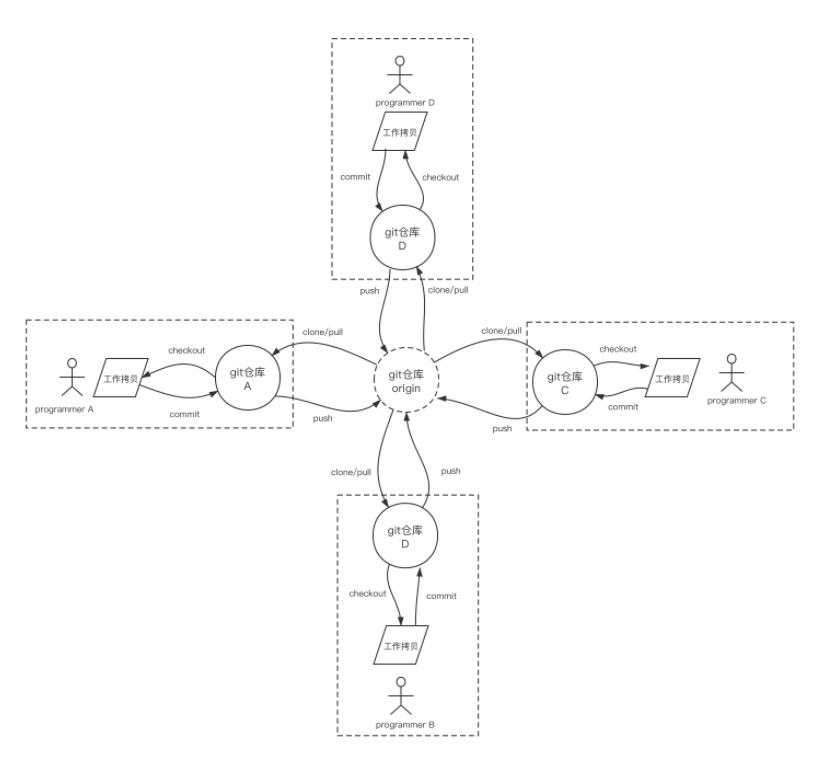
我们看到在github的git协作模式实践中,引入了“中心仓库”的概念,各个程序员的节点git仓库源于(clone于)中心仓库。但是它和SVN的“中心仓库”有着本质的不同,这个仓库只是一个“upstream”库、是一个权威库。它并不是“集线器”,也没有按照“集线器”的那种工作模式进行协作。所有程序员节点的代码生产和版本管理操作完全可以脱离该所谓“中心库”而独立实施。
一个误区
一个很常见的错误观念是,分布式系统不需要中心仓库。这与事实并不相符。克隆主仓库并不会降低它的重要性。
一般来说,一个中心版本控制系统能做的任何事,一个良好设计的分布式系统都能做得更好。网络资源总要比本地资源耗费更昂贵。
一个小项目或许只需要分布式系统提供的一小部分功能,但是,在项目很小的时候,就理应使用规划并不好的系统?就好比说,在计算较小数目的时候应该使用罗马数字?
而且,你的项目的增长可能会超出你最初的预期。从一开始就使用Git好似带着一把瑞士军刀,尽管你很多时候只是用它来开开瓶盖。某天你迫切需要一把改锥,你就会庆幸你所有的不单单是一个启瓶器。
Git 工作流程
- 在工作目录中新建、修改、删除文件;
- 将需要进行版本管理的文件放入暂存区域;
- 将暂存区域的文件commit到Git本地仓库;
- 将Git本地仓库文件push到GIt的远程仓库;
git管理的文件有三种状态:modified(已修改),staged(已暂存),committed(已提交)
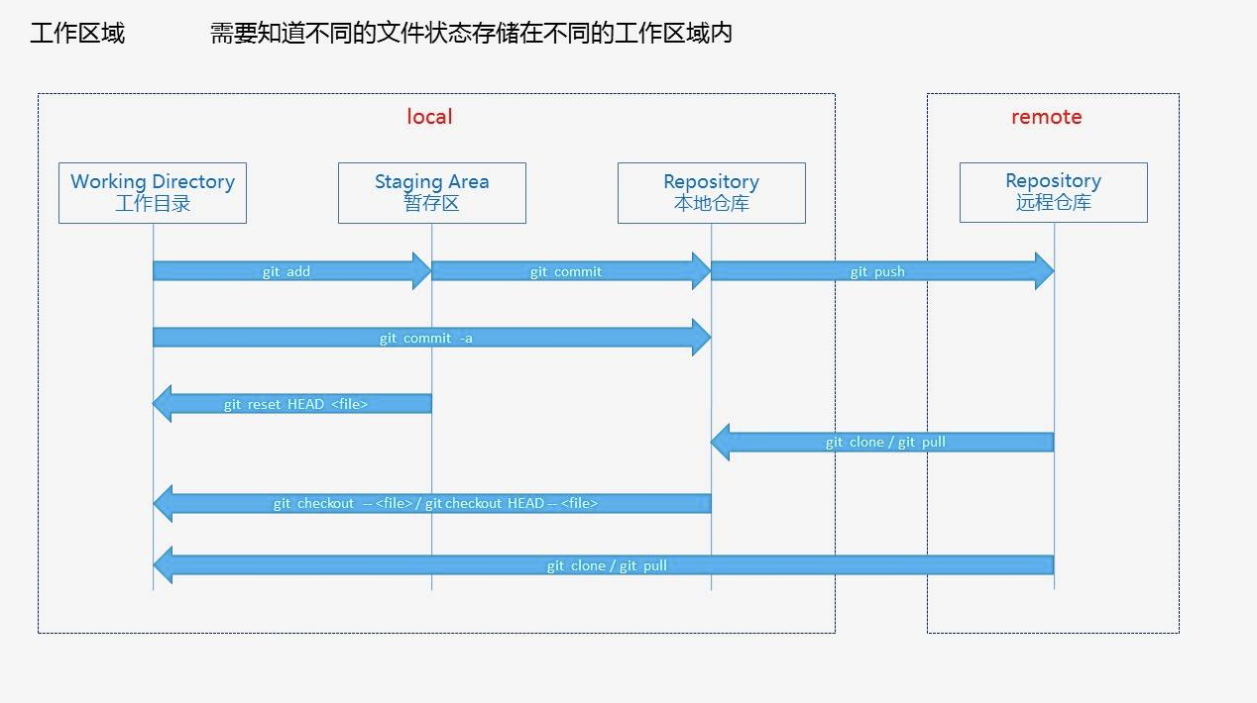
Git文件的四种状态
- Untracked: 未跟踪, 此文件在文件夹中, 但并没有加入到git仓库, 不参与版本控制. 通过
git add filename状态变为Staged. - Unmodify: 文件已经入库, 未修改, 即版本库中的文件快照内容与文件夹中完全一致. 这种类型的文件有两种去处:
- 如果它被修改, 而变为Modified.
- 如果使用
git rm filename, 删除text1.txt文件,并把它从git的仓库管理系统中移除( - Modified: 文件已修改, 仅仅是修改, 并没有进行其他的操作. 这个文件也有两个去处:
- 通过
git add filename可进入暂存staged状态, - 使用
git checkout filename则丢弃修改, 返回到 unmodify 状态, 这个git checkout filename即从本地仓库中取出文件, 覆盖当前修改 ! - Staged: 暂存状态. 执行
git commit则将修改同步到库中, 这时库中的文件和本地文件又变为一致, 文件为Unmodify状态. 执行git reset HEAD filename取消暂存, 文件状态为 Modified;
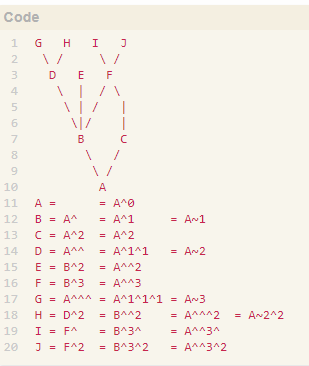
Git 中 ~和^的区别
- ~ 的作用是查找
祖先提交, 例如:想要 HEAD 的第10 个祖先提交,直接使用 HEAD~10 就可以了。<rev>~<n> 用来表示一个提交的第 n 个祖先提交,如果不指定 n,那么默认为 1。 另外,HEAD~~~ 和 HEAD~3 是等价的。 - ^ 的作用是查找 父提交,<rev>^<n> 用来表示一个提交的第 n 个父提交,如果不指定 n,那么默认为 1。 和~ 不同的是,HEAD^^^ 并不等价于 HEAD^3,而是等价与 HEAD^1^1^1。 。因为,很多情况下一个提交并不是只有一个父提交。 就如图表示
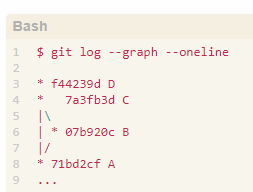 ,7a3fb3d (C) 就有两个父提交:07b920c (B) 、71bd2cf (A)。
,7a3fb3d (C) 就有两个父提交:07b920c (B) 、71bd2cf (A)。 - 具体区别
查看命令详情
$ git ${command} --help
创建仓库
$ git init $ git add . $ git commit -m "Initial commit"
克隆仓库
$ git clone <repo> <directory>
<directory>省略,说明克隆仓库到当前所在文件夹;
查看Git文件状态
$ git status
添加文件到暂存区
# add change form all tracked and untracked files $ git add -all $ git add -A $ git add . # add specified folder $ git add filename
提交变更到本地仓库
$ git commit -m ${changeLog}
# vim 编辑提交记录(i、esc、wq)
$ git commit
查看commit信息
# 查看当前的提交信息
$ git show
$ git show ${commitId}
$ git show ${tag}
merge
从目标 branch 和当前 branch (即 HEAD 所指向的 commit)分叉的位置起,把目标 branch 的路径上的所有 commit 的内容一并应用到当前 branch,然后自动生成一个新的 commit。
merge原理
例如:提交记录如下,当前分支为master

执行: git merge topic 之后,提交计入如下:

- 查找查找 特性分支 和 当前分支 的
- 对比 特性分支topic 相对于 共同祖先E 的历次提交,提取相应的变更作为 临时文件H;
- 将 临时文件H 指向当前分支master的 G提交记录 ,master指针 指向 临时提交E;
- topic 分支 不受影响
$ git merge ${featureBranch} $ git merge (--continue | --abort | --quit)
merge 冲突解决
这里的线条要么与共同 祖先没有变化,要么因为只有一侧发生了变化而被彻底解决。 <<<<<<< yours:sample.txt 冲突解决很难; 我们去买东西吧。 ======== Git 使冲突解决变得容易。 >>>>>> theirs:sample.txt 这是另一行已完全解析或未修改的行。
其中一对相互矛盾的变化发生的区域标有标记 ,和。之前的部分通常是当前分支一方,之后的部分通常是特性分支一方。
如何解决merge冲突
看到冲突后,你可以做两件事:
- 决定不合并:git merge --abort 可以用于此。
- 解决冲突:
- 解决冲突文件;
- 将冲突文件添加到索引区,git add filename;
- 使用 git commit 执行最后的收尾工作;
rebase
的意思是,给你的 序列重新设置基础点(也就是父 )。展开来说就是,把你指定的 以及它所在的 串,以指定的目标 为基础,依次重新提交一次。
# branchName 若没有指定,默认为当前分支
$ git rebase ${upstream} ${branchName}
rebase 原理
例如: 当前提交记录如下,当前分支为topic:

执行
# 如下两条指令等价 $ git rebase -i master $ git rebase -i master topic
之后,分支记录如下:

- 因为 branchName 指定为 topic,所以
git rebase首先自动执行git switch topic,HEAD切换到topic; - 查找topic和master的 共同祖先E;
- 提取 topic 相对 E 的历次提交记录
A、B、C,并保存为临时文件 - 最终将topic 指针指向 C`;
rebase解决冲突
这里的线条要么与共同 祖先没有变化,要么因为只有一侧发生了变化而被彻底解决。 <<<<<<< theirs:sample.txt 冲突解决很难; 我们去买东西吧。 ======== Git 使冲突解决变得容易。 >>>>>> yours:sample.txt 这是另一行已完全解析或未修改的行。
其中一对相互矛盾的变化发生的区域标有标记 ,和。之前的部分通常是upstream分支一方,之后的部分通常是当前分支一方。rebase 之前,自动执行了git switch ${upstream}
如何解决rebase冲突
看到冲突后,你可以做两件事:
- 决定不在继续rebase:git rebase --abort 可以用于此。
- 解决冲突:
- 解决冲突文件;
- 将冲突文件添加到索引区,git add filename;
- git rebase --continue
- 还没好,淡定,重复前面步骤,直到返回正常分支。
rebase的黄金法则
只能在自己的私有分支上使用,绝对不能在公共的分支上使用。
branch
# 创建分支 $ git branch ${branchName} # 切换分支 $ git checkout ${branchName} # 创建并切换分支 $ git checkout -b ${branchName} # 列出所有本地分支 $ git branch # 列出所有远程分支 $ git branch -r # 列出所有本地分支和远程分支 $ git branch -a # 删除分支 $ git branch -d ${branchName} $ git branch -D ${branchName} # 查看各个本地分支的最后一次提交 $ git branch -v # 查看本地分支与远程分支的关联情况 $ git branch -vv # 重命名分支 $ git branch -m|-M ${oldBranch} ${newBranch} # 为 local_branch_name 设置远程关联信息 $ git branch --set-upstream-to=<upstream> <local_branch_name> # 取消 local_branch_name 的远程关联信息 $ git branch --unset-upstream [<local_branch_name>] # 提交所属分支 $ git branch --contains commitId # 本地分支 $ git branch -r --contains commitId # 远程分支 $ git branch -a --contains commitId # 本地和远程分支
stash
# 暂存 untracked 和 modified 的文件 $ git stash push -u -m <message> # 查看暂存列表 $ git stash list # 显示具体的改动信息,num 默认为0 $ git stash show stash@{num} # 应用暂存记录,但不会删除已应用的暂存记录,num 默认为0 $ git stash apply stash@{num} # 应用暂存记录,同时删除已应用的暂存记录,num 默认为0 $ git stash pop stash@{num} # 从暂存列表中,删除指定的暂存记录,num 默认为0 $ git stash drop stash@{num} # 清空暂存列表 $ git stash clear
上传本地分支(push)
# 上传本地分支 $ git push <远程主机名> <本地分支名>:<远程分支名> # 从远程分支删除与本地分支同名的远程分支 $ git push -d origin master # push方式1 $ git push --delete origin master # push方式1 # 等同于 push方式1、2,等同于推送了一个空的本地分支到指定的远程分支 $ git push origin <省略本地分支名>:master # 将本地仓库上传到远程 $ git remote add origin ${ssh@url} $ git push -u origin master
如果 省略 远程分支名,则表示将本地分支推送到与之存在 追踪关系的 远程分支,如果对应的远程分支不存在,则对应的远程分支被创建。
如:
git push origin master
表示将本地的master分支推送到origin主机的master分支,如果origin主机的master分支不存在,则被创建;
获取远程分支(pull)
获取远程分支资源,再与指定的本地分支合并
# 本地分支名可省略,如果省略本地分支表示的是当前的本地分支 $ git pull <远程主机名> <远程分支名> $ git pull <远程主机> <远程分支名>:<本地分支名> # 等价与 $ git fetch <远程主机名> <远程分支名> $ git merge ${<远程主机名>/<远程分支名>} <本地分支名> # 拉取所有的远程分支 $ git fetch <remote_origin> # 拉取指定的远程分支 $ git fetch <远程主机名> <远程分支名>
checkout
的本质,其实是把 指向指定的 ,然后签出这个 所对应的 的工作目录。所以同样的, 的目标也可以不是 ,而直接指定某个 :
git checkout -b <new-branch> [<start_point>]
另外,如果你留心的话可能会发现,在 的提示语中,Git 会告诉你可以用 的格式,通过「签出」的方式来撤销指定文件的修改:
reset
众所周知 这个指令虽然可以用来撤销 ,但它的实质行为并不是撤销,而是移动 ,并且「捎带」上 所指向的 (如果有的话);也就是说,它是用来重置 以及它所指向的 的位置的。
后面总是跟着的那个 是什么意思呢?
指令可以重置 和 的位置,不过在重置它们的同时,对工作目录可以选择不同的操作,而对工作目录的操作的不同,就是通过 后面跟的参数来确定的。
- 工作区有代码(未执行add)
- 暂存区有代码(未执行commit)
reset --hard:重置工作目录
撤销commit, 撤销add, 删除工作区改动;
这个参数慎用,会直接恢复到某次的 commit 状态,同时删除工作区和暂存区的代码。
reset --soft:保留工作目录
撤销 commit,不撤销 add,还原工作区改动代码。
会在重置 和 时,保留工作目录和暂存区中的内容,并把重置 所带来的新的差异放进暂存区。
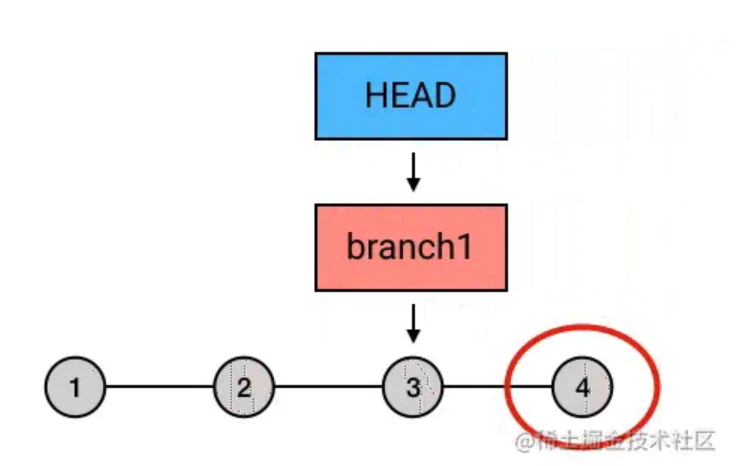
由于 从 移动到了 ,而且在 的过程中工作目录的内容没有被清理掉,所以 中的改动在 后就也成了工作目录新增的「工作目录和 的差异」。这就是上面一段中所说的「重置 所带来的差异」。
reset --mixed 不加参数:保留工作目录,并清空暂存区
撤销 commit,撤销 add,还原工作区改动代码。
如果不加参数,那么默认使用 参数。它的行为是:保留工作目录,并且清空暂存区。也就是说,工作目录的修改、暂存区的内容以及由 所导致的新的文件差异,都会被放进工作目录。简而言之,就是「把所有差异都混合(mixed)放在工作目录中」。
revert
撤销之前的一个指定的提交,这次改动只是被「反转」了,并没有在历史中消失掉,你的历史中会存在两条 :一个原始 ,一个对它的反转 。
git revert -n master~5..master~2
将提交所做的更改从 master 中的倒数第五次提交(包括)恢复到 master 中的倒数第三次提交(包括),但不要使用恢复的更改创建任何提交。
diff
# 比对 **工作目录和暂存区** 的不同 $ git diff (不加参数) $ git diff <file> # 比对 **暂存区和最后一次提交(HEAD)** 之间的不同 $ git diff --staged $ git diff --cached $ git diff --cached <file> # 比对 **工作目录和最后一次提交(HEAD)** 之间的不同 $ git diff HEAD $ git diff HEAD <file>
cherry-pick
功能: 将指定的提交应用于其它分支;
git cherry-pick -x ([commitId] | [first-commitId]..[last-commitId]) # 其中,[first-commitId]..[last-commitId] 是前开后闭, # 即不包括first-commitId,但包括last-commitId # -x cherry picked from commit
上面命令就会将指定的提交commitId,应用于当前分支。这会在当前分支产生一个新的提交,当然它们的哈希值会不一样。
git cherry-pick 命令的参数,不一定是提交的哈希值,分支名也是可以的,表示转移该分支的最新提交。
a - b - c - d Master \ e - f - g - i - j Feature 现在将提交f应用到master分支 # 切换到 master 分支 $ git checkout master # 将commit f 转移到master分支,则运行 $ git cherry-pick f # 操作之后的代码库样式 a - b - c - d - f Master \ e - f - g Feature # 可以看到,master分支的末尾增加了一个提交f; # 将commit f、commit g 转移到master分支,则运行 $ git cherry-pick f g # 将commit f 到 commit i 转移到master分支,则运行 $ git cherry-pick e..i
git rm
touch txt.txt
# 将txt.txt 文件添加到索引库
git add txt.txt
# 将 txt.txt 文件从索引库中移除,但是对txt.txt文件本身没有进行任何操作
git rm --cached txt.txt
远程分支已经被删除,删除本地同名的远程分支
# 远程分支已经被删除,删除本地同名的远程分支
$ git fetch -p
恢复提交信息
刚刚提交的代码,发现写错了怎么办?
此方式用于解决:刚刚提交的代码,发现写错了,但还没有push到代码仓库;
$ git commit --amend
在提交时,如果加上 参数,Git 不会在当前 上增加 ,而是会把当前 里的内容和暂存区(stageing area)里的内容合并起来后创建一个新的 ,用这个新的 commit 把当前 commit 替换掉。
写错的不是最新的提交,而是倒数第n个?
此方式用于解决:提交的代码不是最新的,而是倒数第n个,发现写错了,但还没有push到代码仓库;
$ git rebase -i head~n
比错还错,想直接丢弃刚写的提交?
此方式用于解决:刚刚提交的代码是最新的,但是不想要了,但还没有push到代码仓库;
有的时候,刚写完的 写得实在太烂,连自己的都看不下去,与其修改它还不如丢掉重写。这种情况,就可以用 来丢弃最新的提交。
git reset --hard head~
代码已经push上去了,才发现写错了?
分两种情况进行处理
- 出错的内容在自己的独立开发分支,和他人无关。可以使用本地内容强行覆盖中央仓库的内容,修改的内容是刻意的、可预料的;
$ git push -f origin <branch_name>
- 出错的内容在公共分支,使用 revert 操作;
$ git revert <commit_id>
在 完成之后,把新的 再 上去,这个 的内容就被撤销了。它和前面所介绍的撤销方式相比,最主要的区别是,这次改动只是被「反转」了,并没有在历史中消失掉,你的历史中会存在两条 :一个原始 ,一个对它的反转 修改了gitignore文件,刷新Git暂存区
$ git rm -rf --cached . $ git add . $ git commit -m "update .gitignore" $ git push origin master
branch 删过了才想起来有用?
用完就删是好习惯,但有的时候,不小心手残删了一个还有用的 ,或者把一个 删掉了才想起来它还有用,怎么办?
$ git reflog ${branch_name}
是 "reference log" 的缩写,使用它可以查看 Git 仓库中的引用的移动记录。如果不指定引用,它会显示 的移动记录。假如你误删了 这个 ,那么你可以查看一下 的移动历史:
git reflog
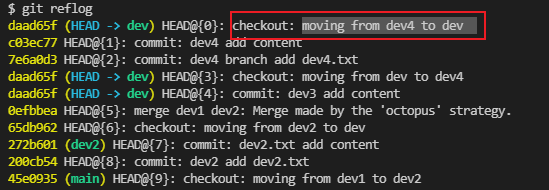
从图中可以看出, 的最后一次移动行为是「从 移动到 」。而在这之后, 就被删除了。所以它之前的那个 就是 被删除之前的位置了,也就是第二行的 。
所以现在就可以切换回 ,然后重新创建 :
$ git checkout c03ec77
$ git checkout -b dev4
这样,你刚删除的 就找回来了。
不确定那个分支有自己提交的commit
Git 提供了一种能够直接通过 commit-id 查找出包含该内容分支的命令。
$ git branch --contains <commit-id> $ git branch --contains 700920
查看其他引用的 reflog
默认查看 的移动历史,除此之外,也可以手动加上名称来查看其他引用的移动历史,例如查看 :
git reflog main

