
Python数据分析教程(三):实用代码
Python数据分析教程专栏:数据分析 - 标签 - 孤飞 - 博客园 (cnblogs.com)
Python数据分析教程(一):Numpy - 孤飞 - 博客园 (cnblogs.com)
Python数据分析教程(二):Pandas - 孤飞 - 博客园 (cnblogs.com)
文件处理
导包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
添加镜像
# 阿里云
http://mirrors.aliyun.com/pypi/simple/
# 中国科技大学
https://pypi.mirrors.ustc.edu.cn/simple/
# 豆瓣
http://pypi.douban.com/simple/
# 清华大学
https://pypi.tuna.tsinghua.edu.cn/simple/
# 中国科学技术大学
http://pypi.mirrors.ustc.edu.cn/simple/
语法
其中http和https是可选的
! pip install xxx -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
导入文件
excel
data=pd.read_excel(r"C:\Users\ranxi\Desktop\附录1 目标客户体验数据.xlsx", sheet_name='data')
data.head()
csv
data=pd.read_csv()
EDA报告
#生成报告
import pandas_profiling
data.profile_report()
#输出报告文件
pfr = pandas_profiling.ProfileReport(data)
pfr.to_file('report.html')
dataframe导出excel文件
data.to_excel('data.xlsx')
数据处理
数据筛选
分类均值展示
cvr_summary = data.groupby("cvr_group_high")
cvr_summary.mean().reset_index()
标签编码
print("client","--" ,data.client.unique())
from sklearn.preprocessing import LabelEncoder
data.client = LabelEncoder().fit_transform(data.client)
print("client","--" ,data.client.unique())
交叉比例表
pd.crosstab(data['invited_is'],data["cvr_group_high"],normalize=0)
计算分布比例
def percent_value_counts(df, feature):
"""This function takes in a dataframe and a column and finds the percentage of the value_counts"""
percent = pd.DataFrame(round(df.loc[:,feature].value_counts(dropna=False, normalize=True)*100,2))
## creating a df with th
total = pd.DataFrame(df.loc[:,feature].value_counts(dropna=False))
## concating percent and total dataframe
total.columns = ["Total"]
percent.columns = ['Percent']
return pd.concat([total, percent], axis = 1)
percent_value_counts(data, "B7")
多列apply函数
with_N['B7'] = with_N.apply(lambda x: child_estimator(x['B6'], x['B5']), axis=1)
卡方检验
#分组间确实是有显著性差异,频数比较的结论才有可信度,故需进行”卡方检验“
from scipy.stats import chi2_contingency #统计分析 卡方检验
#自定义卡方检验函数
def KF(x):
df1=pd.crosstab(data2['购买意愿'],data2[x])
li1=list(df1.iloc[0,:])
li2=list(df1.iloc[1,:])
kf_data=np.array([li1,li2])
kf=chi2_contingency(kf_data)
if kf[1]<0.05:
print('购买意愿 by {} 的卡方临界值是{:.2f},小于0.05,表明{}组间有显著性差异,可进行【交叉分析】'.format(x,kf[1],x),'\n')
else:
print('购买意愿 by {} 的卡方临界值是{:.2f},大于0.05,表明{}组间无显著性差异,不可进行交叉分析'.format(x,kf[1],x),'\n')
#对 kf_var进行卡方检验
print('kf_var的卡方检验结果如下:','\n')
print(list(map(KF, kf_var)))
条件筛选
specific=data[(data['a1']>100)|(data['a2']>100)|(data['a3']>100)|(data['a4']>100)|(data['a5']>100)|(data['a6']>100)|(data['a7']>100)|(data['a8']>100)]
specific
specific=data[(data['']>x)|&()]
data[data.Cabin=='N']
map函数分组
def hour_group_fun(hour):
x = ''
if 0<=hour<8:
x=1
elif 8<=hour<16:
x=2
else:
x=3
return x
## Applying function to the column.
police['hour_group'] =police['hour'].map(hour_group_fun)
apply多列赋值
with_N['B7'] = with_N.apply(lambda x: child_estimator(x['B6'], x['B5']), axis=1)
这是一个分布比例函数
def percent_value_counts(df, feature):
"""This function takes in a dataframe and a column and finds the percentage of the value_counts"""
percent = pd.DataFrame(round(df.loc[:,feature].value_counts(dropna=False, normalize=True)*100,2))
## creating a df with th
total = pd.DataFrame(df.loc[:,feature].value_counts(dropna=False))
## concating percent and total dataframe
total.columns = ["Total"]
percent.columns = ['Percent']
return pd.concat([total, percent], axis = 1)
特征工程
时间数据处理
police['date'] = pd.to_datetime(police['接警日期'],errors='coerce')
police['year'] =police['date'].dt.year.fillna(0).astype("int") #转化提取年
police['month'] = police['date'].dt.month.fillna(0).astype("int") #转化提取月
police['day'] = police['date'].dt.day.fillna(0).astype("int") #转化提取天
police['dates'] = police['month'].map(str) + '-' + police['day'].map(str) #转化获取月-日
police['time'] = pd.to_datetime(police['接警时间点'],errors='coerce').dt.time
police['hour'] = pd.to_datetime(police['接警时间点'],errors='coerce').dt.hour.fillna(0).astype("int") #转化提取小时
SMOTE过抽样
from imblearn.over_sampling import SMOTE
model_smote=SMOTE()
X,y=model_smote.fit_resample(X,y)
X=pd.DataFrame(X,columns=t.columns)
#分拆数据集:训练集 和 测试集
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.3,random_state=0)
print('过抽样数据特征:', X.shape,
'训练数据特征:',X_train.shape,
'测试数据特征:',X_test.shape)
print('过抽样后数据标签:', y.shape,
' 训练数据标签:',y_train.shape,
' 测试数据标签:',y_test.shape)
输出缺失值
print ("Train age missing value: " + str((train.Age.isnull().sum()/len(train))*100)+str("%"))
影响分析
xgb输出特征重要性
model_xgb= XGBClassifier()
model_xgb.fit(X,y)
from xgboost import plot_importance
plot_importance(model_xgb,height=0.5,color='green',title='')
# plt.savefig('imp.png')
plt.show()
计算相关系数并画图
plt.style.use('classic')
plt.rcParams['font.sans-serif'] = ['SimHei'] # 黑体
plt.rcParams['axes.unicode_minus'] = False # 解决无法显示符号的问题
plt.rc("figure", facecolor="white") #去除灰色边框
plt.figure(figsize=(15,6),dpi=300)
df_onehot.corr()['购买意愿'].sort_values(ascending=False).plot(kind='bar',color='dodgerblue')
plt.savefig('buyvary1.png', dpi=300)
plt.show()
data.corr(method='pearson')
data.corr(method='spearman')
data.corr(method='kendall')
Pandas处理
常用操作
为dataframe添加1列
data['age']=list
合并表格再排序
data = pd.concat([with_N, without_N], axis=0)
data.sort_values(by = '目标客户编号', inplace=True)
dataframe排序
useful=useful.sort_values(by = ['购买难度'], ascending = [True])
选取指定行(以列的值筛选)
first1=data3[(data3['品牌编号']==1)]
获取列名
kf=list(data2.columns[1:7])
for x in [9,11,12,20,21,24,25,26]:
kf.append(data2.columns[x])
print(kf)
修改列名
#1、修改列名a,b为A、B。
df.columns = ['A','B']
#2、只修改列名a为A
df.rename(columns={'a':'A'})
删除一列
data3=data3.drop(1,axis=0)
列表转dataframe(嵌套列表)
from pandas.core.frame import DataFrame
data7=DataFrame(week)
data7
类型转换
Dataframe到Series
Series = Dataframe['column']
Series到list
list = Series.to_list()
list 转 array
array = np.array(list)
array 转 torch.Tensor
tensor = torch.from_numpy(array)
torch.Tensor 转 array
array = tensor.numpy()
# gpu情况下需要如下的操作
array = tensor.cpu().numpy()
torch.Tensor 转 list
# 先转numpy,后转list
list = tensor.numpy().tolist()
array 转 list
list = array.tolist()
list 转 torch.Tensor
tensor=torch.Tensor(list)
array或者list转Series
series = pd.Series({'a': array})
series2 = pd.Series({'a': list})
list转dataframe
data4=DataFrame(li)
array转dataframe
df = pd.DataFrame(data=data[0:,0:],columns='pregnants','Plasma_glucose_concentration','blood_pressure','Triceps_skin_fold_thickness','serum_insulin','BMI','Diabetes_pedigree_function','Age','Target'] )
python需要注意的地方
变量
列表的复制:直接采用a=b的方式会指向同一个内存地址
全局变量:函数内部的变量,外部是无法访问的,在函数内部定义global 后函数运行过才可访问
循环
- continue: 跳出本次循环
- break: 跳出本层循环
运算
矩阵numpy乘法:
- 点乘: np.dot(xy)
- 数乘: np.mat(x,int)
随机数
import random
print( random.randint(1,10) ) # 产生 1 到 10 的一个整数型随机数
print( random.random() ) # 产生 0 到 1 之间的随机浮点数
print( random.uniform(1.1,5.4) ) # 产生 1.1 到 5.4 之间的随机浮点数,区间可以不是整数
print( random.choice('tomorrow') ) # 从序列中随机选取一个元素
print( random.randrange(1,100,2) ) # 生成从1到100的间隔为2的随机整数
a=[1,3,5,6,7] # 将序列a中的元素顺序打乱
random.shuffle(a)
print(a)
import random
import string
# 随机整数:
print random.randint(1,50)
# 随机选取0到100间的偶数:
print random.randrange(0, 101, 2)
# 随机浮点数:
print random.random()
print random.uniform(1, 10)
# 随机字符:
print random.choice('abcdefghijklmnopqrstuvwxyz!@#$%^&*()')
# 多个字符中生成指定数量的随机字符:
print random.sample('zyxwvutsrqponmlkjihgfedcba',5)
# 从a-zA-Z0-9生成指定数量的随机字符:
ran_str = ''.join(random.sample(string.ascii_letters + string.digits, 8))
print ran_str
# 多个字符中选取指定数量的字符组成新字符串:
print ''.join(random.sample(['z','y','x','w','v','u','t','s','r','q','p','o','n','m','l','k','j','i','h','g','f','e','d','c','b','a'], 5))
# 随机选取字符串:
print random.choice(['剪刀', '石头', '布'])
# 打乱排序
items = [1, 2, 3, 4, 5, 6, 7, 8, 9, 0]
print random.shuffle(items)
画图
画图准备
解决中文符号显示问题
plt.rcParams['font.sans-serif'] = ['SimHei'] # 黑体
plt.rcParams['axes.unicode_minus'] = False # 解决无法显示符号的问题
sns.set(font='SimHei', font_scale=0.8) # 解决Seaborn中文显示问题
设置背景样式
plt.style.use('classic')
plt.rc("figure", facecolor="white") #去除灰色边框
绘图
这是一个画箱线图代码
import matplotlib.pyplot as plt
sns.set_style('darkgrid')
fig, ax = plt.subplots(figsize=(16,12),ncols=2)
ax1 = sns.boxplot(x="Embarked", y="Fare", hue="Pclass", data=train, ax = ax[0]);
ax2 = sns.boxplot(x="Embarked", y="Fare", hue="Pclass", data=test, ax = ax[1]);
ax1.set_title("Training Set", fontsize = 18)
ax2.set_title('Test Set', fontsize = 18)
fig.show()
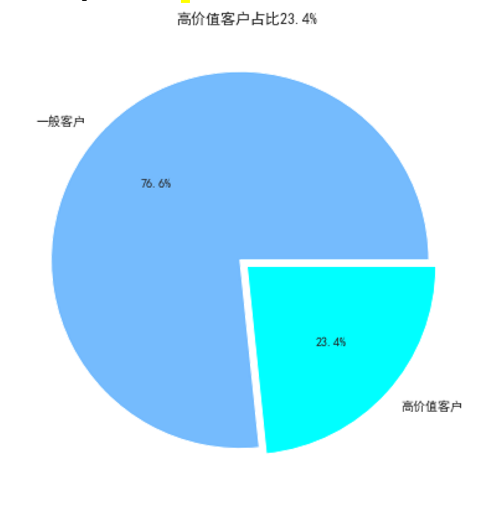
画缺口饼图
churn_value=data['cvr_group_high'].value_counts()
labels=data['cvr_group_high'].value_counts().index
plt.figure(figsize=(7,7))
plt.pie(churn_value,labels=['一般客户', '高价值客户'],colors=["#75bbfd","#00ffff"], explode=(0.05,0),autopct='%1.1f%%', shadow=False)
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.title("高价值客户占比23.4%")
#plt.savefig('pie.png', dpi=300)
画相关性系数图
mask = np.zeros_like(data.corr(), dtype=np.bool)
#mask[np.triu_indices_from(mask)] = True
plt.subplots(figsize = (15,12))
sns.heatmap(data.corr(),
annot=True,
# mask = mask,
cmap = 'RdBu', ## in order to reverse the bar replace "RdBu" with "RdBu_r"
linewidths=.9,
linecolor='gray',
fmt='.2g',
center = 0,
square=True)
plt.title("Correlations Among Features", y = 1.03,fontsize = 20, pad = 40) #相关性矩阵
plt.savefig('cor.png', dpi=300)
plt.show()
画核密度估计
fig = plt.figure(figsize=(15,8),)
## I have included to different ways to code a plot behigh, choose the one that suites you.
ax=sns.kdeplot(data.client[data.cvr_group_high == 0] ,
color='gray',
shade=True,
label='high')
ax=sns.kdeplot(data.loc[(data['cvr_group_high'] == 1),'client'] ,
color='g',
shade=True,
label='high',
)
plt.title('client - high vs high', fontsize = 25, pad = 40)
plt.ylabel("Frequency of cvr", fontsize = 15, labelpad = 20)
plt.xlabel("Client", fontsize = 15,labelpad =20)
## Converting xticks into words for better understanding
labels = ['H5', 'android', 'ios','pc','wap']
plt.xticks(sorted(data.client.unique()), labels)
plt.legend()

模型训练
导入模块
#加载模块
from sklearn.preprocessing import StandardScaler
import warnings
warnings.filterwarnings("ignore") #过滤掉警告的意思
from pyforest import *
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestClassifier #随机森林
from sklearn.svm import SVC,LinearSVC #支持向量机
from sklearn.linear_model import LogisticRegression #逻辑回归
from sklearn.neighbors import KNeighborsClassifier #KNN算法
from sklearn.cluster import KMeans #K-Means 聚类算法
from sklearn.naive_bayes import GaussianNB #朴素贝叶斯
from sklearn.tree import DecisionTreeClassifier #决策树
import xgboost as xgb
from xgboost import XGBClassifier
from catboost import CatBoostClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import classification_report,precision_score,recall_score,f1_score,accuracy_score #分类报告
from sklearn.metrics import confusion_matrix #混淆矩阵
from sklearn.metrics import silhouette_score #轮廓系数(评价k-mean聚类效果)
from sklearn.model_selection import GridSearchCV #交叉验证
from sklearn.metrics import make_scorer
from sklearn.ensemble import VotingClassifier #投票
def plot_predictions(test,predicted):
#整体平移
x=np.arange(0,len(test))+1
# x[0]=1
# my_x_ticks = np.arange(1, 14, 1)
# plt.xticks(my_x_ticks)
plt.plot(x,test,label='Real')
plt.plot(x,predicted,color='darkOrange',linestyle='--',label='Predicted')
# plt.xlabel('month')
plt.ylabel('count')
plt.legend()
import math
def mse_loss(y_true, y_pred):
return np.sum(np.power(y_true - y_pred, 2)) / y_true.shape[0] / 2
def return_rmse(test,predicted):
rmse = math.sqrt(mse_loss(test, predicted))
return rmse
# print("The mean squared error is {}.".format(rmse))
Classifiers=[
["Random Forest",RandomForestClassifier()],
["Support Vector Machine",SVC()],
["LogisticRegression",LogisticRegression()],
["KNN",KNeighborsClassifier(n_neighbors=5)],
["Naive Bayes",GaussianNB()],
["Decision Tree",DecisionTreeClassifier()],
["AdaBoostClassifier",AdaBoostClassifier()],
["GradientBoostingClassifier", GradientBoostingClassifier()],
["XGB", XGBClassifier()],
]
设置训练集
X=train.drop(['目标客户编号','品牌类型','购买意愿'], axis = 1)
# X=train.drop(['目标客户编号','品牌类型'], axis = 1)
t=X
headers = X.columns
X= X.astype(float)
y = train["购买意愿"]
训练模型
import warnings
warnings.filterwarnings('ignore')
Classify_result=[]
names=[]
prediction=[]
for name,classifier in Classifiers:
classifier=classifier
classifier.fit(X_train,y_train)
y_pred=classifier.predict(X_test)
recall=recall_score(y_test,y_pred,average='macro')
precision=precision_score(y_test,y_pred,average='macro')
f1score = f1_score(y_test, y_pred,average='macro')
mse = return_rmse(y_test,y_pred)
class_eva=pd.DataFrame([recall,precision,f1score,mse])
Classify_result.append(class_eva)
name=pd.Series(name)
names.append(name)
y_pred=pd.Series(y_pred)
prediction.append(y_pred)
plot_predictions(y_test,y_pred)
# # plt.savefig('seven1.png', dpi=300)
plt.show()
模型评估
names=pd.DataFrame(names)
names=names[0].tolist()
result=pd.concat(Classify_result,axis=1)
result.columns=names
result.index=["recall","precision","f1score","mse"]
result
小工具
tqdm显示进度条
from tqdm import tqdm
for I in tqdm():
记录时间
Import time
time_begin = time.time()
#code,你的程序
time_end = time.time()
time = time_end - time_begin
print('time:', time)
jupyter操作
- Shift+上下键 # 按住Shift进行上下键操作可复选多个cell
- Shift-M # 合并所选cell或合并当前cell和下方的cell
- Ctrl + Shift + - # 从光标所在的位置拆分cell
原创作者:孤飞-博客园
原文链接:https://www.cnblogs.com/ranxi169/p/16838967.html

