

Python机器学习-分类
- 监督学习下的分类模型,主要运用sklearn实践
-
kNN分类器
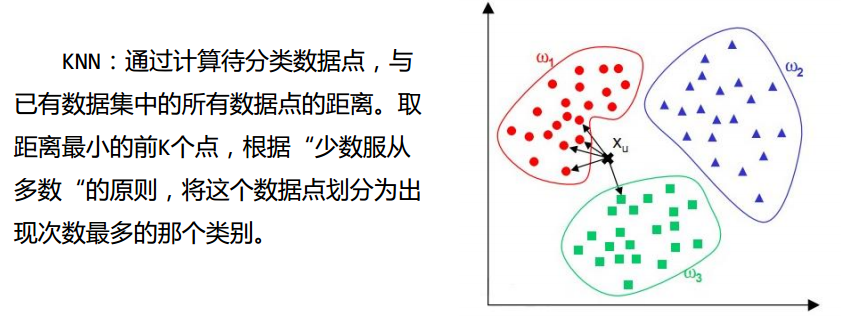



-
决策树



-
朴素贝叶斯

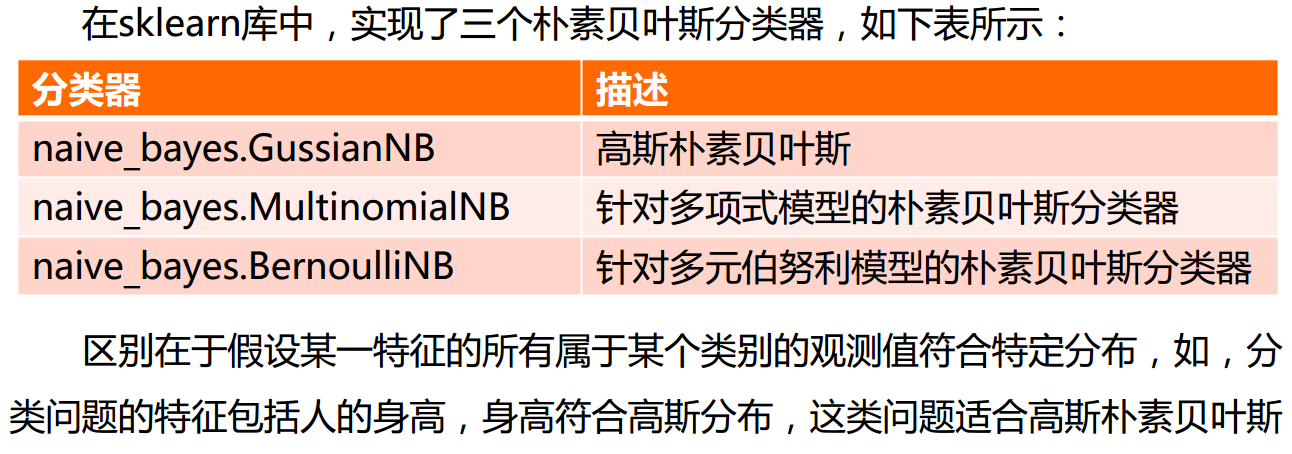



-
实战一:预测股市涨跌
# -*- coding: utf-8 -*- """ Created on Mon Aug 28 15:42:55 2017 @author: Administrator """ # unit4 classify #数据介绍: #网易财经上获得的上证指数的历史数据,爬取了20年的上证指数数据。 #实验目的: #根据给出当前时间前150天的历史数据,预测当天上证指数的涨跌。 import pandas as pd import numpy as np from sklearn import svm from sklearn import cross_validation fpath='F:\RANJIEWEN\MachineLearning\Python机器学习实战_mooc\data\classify\stock\\000777.csv' data=pd.read_csv(fpath,encoding='gbk',parse_dates=[0],index_col=0) data.sort_index(0,ascending=True,inplace=True) dayfeature=150 featurenum=5*dayfeature x=np.zeros((data.shape[0]-dayfeature,featurenum+1)) y=np.zeros((data.shape[0]-dayfeature)) for i in range(0,data.shape[0]-dayfeature): x[i,0:featurenum]=np.array(data[i:i+dayfeature] \ [[u'收盘价',u'最高价',u'最低价',u'开盘价',u'成交量']]).reshape((1,featurenum)) x[i,featurenum]=data.ix[i+dayfeature][u'开盘价'] for i in range(0,data.shape[0]-dayfeature): if data.ix[i+dayfeature][u'收盘价']>=data.ix[i+dayfeature][u'开盘价']: y[i]=1 else: y[i]=0 clf=svm.SVC(kernel='rbf') result = [] for i in range(5): x_train, x_test, y_train, y_test = \ cross_validation.train_test_split(x, y, test_size = 0.2) clf.fit(x_train, y_train) result.append(np.mean(y_test == clf.predict(x_test))) print("svm classifier accuacy:") print(result)
-
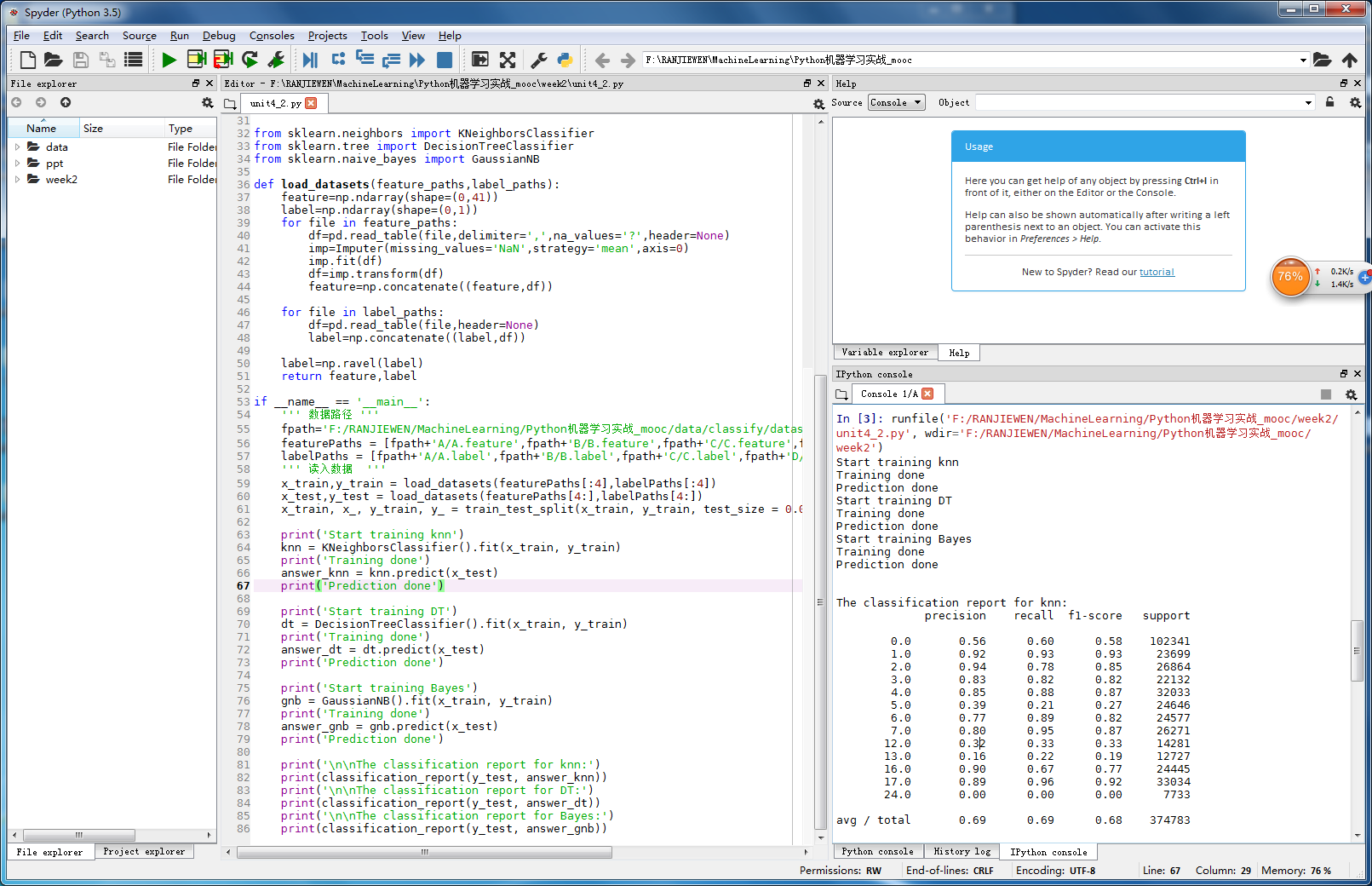
实战二:通过运动传感器采集的数据分析运行状态
# -*- coding: utf-8 -*- """ Created on Mon Aug 28 19:41:21 2017 @author: Administrator """ ''' 现在收集了来自 A,B,C,D,E 5位用户的可穿戴设备上的传感器数据, 每位用户的数据集包含一个特征文件(a.feature)和一个标签文件 (a.label) 特征文件中每一行对应一个时刻的所有传感器数值,标签文件中每行记录了 和特征文件中对应时刻的标记过的用户姿态,两个文件的行数相同,相同行 之间互相对应 标签文件内容如图所示,每一行代表与特征文件中对应行的用户姿态类别。 总共有0-24共25种身体姿态,如,无活动状态,坐态、跑态等。标签文件作为 训练集的标准参考准则,可以进行特征的监督学习。 假设现在出现了一个新用户,但我们只有传感器采集的数据,那么该如何得到 这个新用户的姿态呢? 或者对同一用户如果传感器采集了新的数据,怎么样根据新的数据判断当前 用户处于什么样的姿态呢? ''' import pandas as pd import numpy as np from sklearn.preprocessing import Imputer from sklearn.cross_validation import train_test_split from sklearn.metrics import classification_report from sklearn.neighbors import KNeighborsClassifier from sklearn.tree import DecisionTreeClassifier from sklearn.naive_bayes import GaussianNB def load_datasets(feature_paths,label_paths): feature=np.ndarray(shape=(0,41)) label=np.ndarray(shape=(0,1)) for file in feature_paths: df=pd.read_table(file,delimiter=',',na_values='?',header=None) imp=Imputer(missing_values='NaN',strategy='mean',axis=0) imp.fit(df) df=imp.transform(df) feature=np.concatenate((feature,df)) for file in label_paths: df=pd.read_table(file,header=None) label=np.concatenate((label,df)) label=np.ravel(label) return feature,label if __name__ == '__main__': ''' 数据路径 ''' fpath='F:/RANJIEWEN/MachineLearning/Python机器学习实战_mooc/data/classify/dataset/' featurePaths = [fpath+'A/A.feature',fpath+'B/B.feature',fpath+'C/C.feature',fpath+'D/D.feature',fpath+'E/E.feature'] labelPaths = [fpath+'A/A.label',fpath+'B/B.label',fpath+'C/C.label',fpath+'D/D.label',fpath+'E/E.label'] ''' 读入数据 ''' x_train,y_train = load_datasets(featurePaths[:4],labelPaths[:4]) x_test,y_test = load_datasets(featurePaths[4:],labelPaths[4:]) x_train, x_, y_train, y_ = train_test_split(x_train, y_train, test_size = 0.0) print('Start training knn') knn = KNeighborsClassifier().fit(x_train, y_train) print('Training done') answer_knn = knn.predict(x_test) print('Prediction done') print('Start training DT') dt = DecisionTreeClassifier().fit(x_train, y_train) print('Training done') answer_dt = dt.predict(x_test) print('Prediction done') print('Start training Bayes') gnb = GaussianNB().fit(x_train, y_train) print('Training done') answer_gnb = gnb.predict(x_test) print('Prediction done') print('\n\nThe classification report for knn:') print(classification_report(y_test, answer_knn)) print('\n\nThe classification report for DT:') print(classification_report(y_test, answer_dt)) print('\n\nThe classification report for Bayes:') print(classification_report(y_test, answer_gnb))
- result
C/C++基本语法学习
STL
C++ primer

 浙公网安备 33010602011771号
浙公网安备 33010602011771号