

Focal Loss(RetinaNet) 与 OHEM
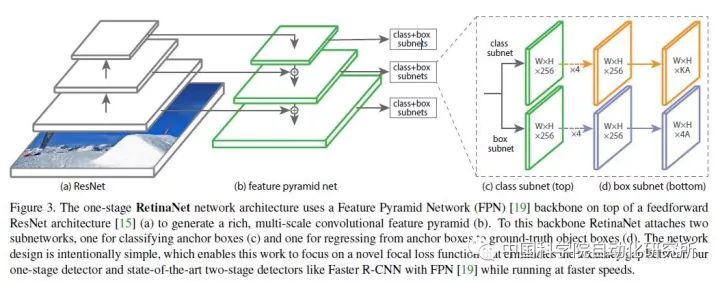
Focal Loss for Dense Object Detection-RetinaNet
YOLO和SSD可以算one-stage算法里的佼佼者,加上R-CNN系列算法,这几种算法可以说是目标检测领域非常经典的算法了。这几种算法在提出之后经过数次改进,都得到了很高的精确度,但是one-stage的算法总是稍逊two-stage算法一筹,于是就有了Focal Loss来找场子。
在Focal Loss这篇论文中中,作者认为one-stage精确度不如two-stage是因为下面的原因:
① 正负样本比例极度不平衡。由于one-stage detector没有专门生成候选框的子网络,无法将候选框的数量减小到一个比较小的数量级(主流方法可以将候选框的数目减小到数千),导致了绝大多数候选框都是背景类,大大分散了放在非背景类上的精力;
② 梯度被简单负样本主导。我们将背景类称为负样本。尽管单个负样本造成的loss很小,但是由于它们的数量极其巨大,对loss的总体贡献还是占优的,而真正应该主导loss的正样本由于数量较少,无法真正发挥作用。这样就导致收敛不到一个好的结果。
既然负样本数量众多,one-stage detector又不能减小负样本的数量,那么很自然的,作者就想到减小负样本所占的权重,使正样本占据更多的权重,这样就会使训练集中在真正有意义的样本上去,这也就是Focal Loss这个题目的由来。
其实在Focal Loss之前,就有人提出了OHEM(online hard example mining)方法。OHEM的核心思想就是增加错分类样本的权重,但是OHEM却忽略了易分类样本,而我们知道这一部分是所有样本中的绝大部分。

与OHEM不同,Focal Loss把注意力放在了易分类样本上,它的形式如图所示。Focal Loss是一种可变比例的交叉熵损失,当正确分类可能性提高时比例系数会趋近于0。这样一来,即使再多的易分类样本也不会主导梯度下降的过程,于是训练网络自然可以自动对易分类样本降权,从而快速地集中处理难分类样本。
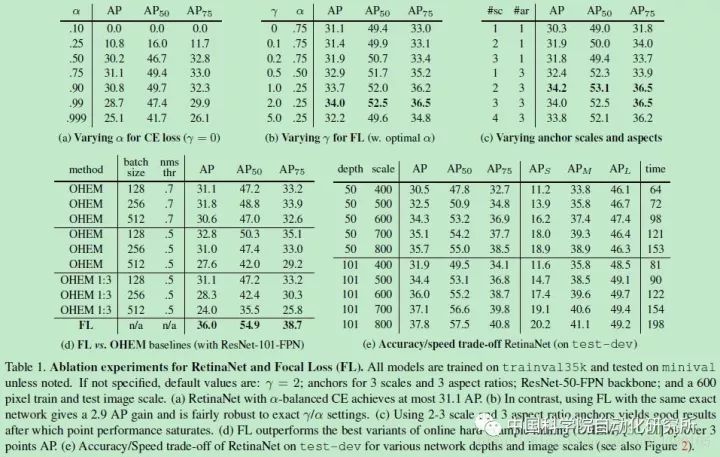
可以看出,Focal Loss打败了所有state-of-the-art的算法,而且竟然在速度上也是一马当先,可以说相当有说服力。但是作者为了证明Focal Loss的有效性,并没有设计更新颖的网络,这与其他算法提高精确度的做法是不一样的——他们要么改造原有算法的网络结构,要么另辟蹊径。另外,Focal Loss函数的形式并不是不可变的,只要可以达到对易分类样本降权的目的,可以在形式上有所变化。
总之,Class imbalance是阻碍one-stage方法提高准确率的主要障碍,过多的easy negative examples会在训练过程中占据主导地位,使训练结果恶化,所以要用Focal Loss对easy negative examples进行降权,而把更多的注意力集中在hard examples上。
OHEM: Training Region-based Object Detectors with Online Hard Example Mining
Hard example mining:https://github.com/abhi2610/ohem
主要有2种参见Hard example mining算法,优化SVM时候的算法和非SVM时的利用。
在优化SVM中使用Hard example mining时,训练算法主要维持训练SVM和在工作集上收敛的平衡迭代过程,同时在更新过程中去除一些工作集中样本并添加其他特殊的标准。这里的标准即去掉一些很容易区分的样本类,并添加一些用现有的模型不能判断的样本类,进行新的训练。工作集为整个训练集中的一小部分数据。
非SVM中使用时,该Hard example mining算法开始于正样本数据集和随机的负样本数据集,机器学习模型在这些数据集中进行训练使其达到该数据集上收敛,并将其应用到其他未训练的负样本集中,将判断错误的负样本数据(false positives)加入训练集,重新对模型进行训练。这种过程通常只迭代一次,并不获得大量的再训练收敛过程。
网络结构框架:
OHEM算法基于Fast R-CNN算法进行改进,作者认为Fast R-CNN算法中创造mini-batch用来进行SGD算法,并不具有高效和最优的状态,而OHEM可以取得lower training loss,和higher mAP。对比下图两种算法Fast R-CNN和OHEM结构: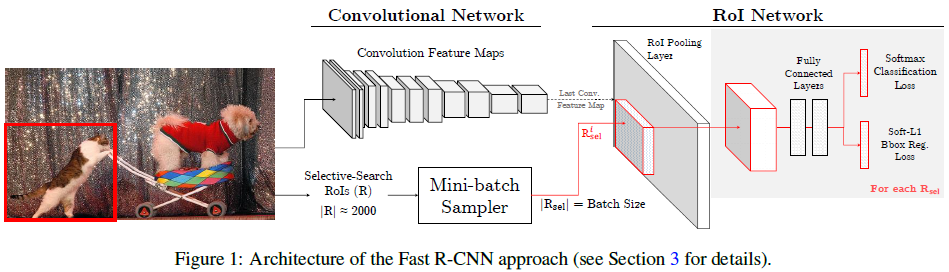
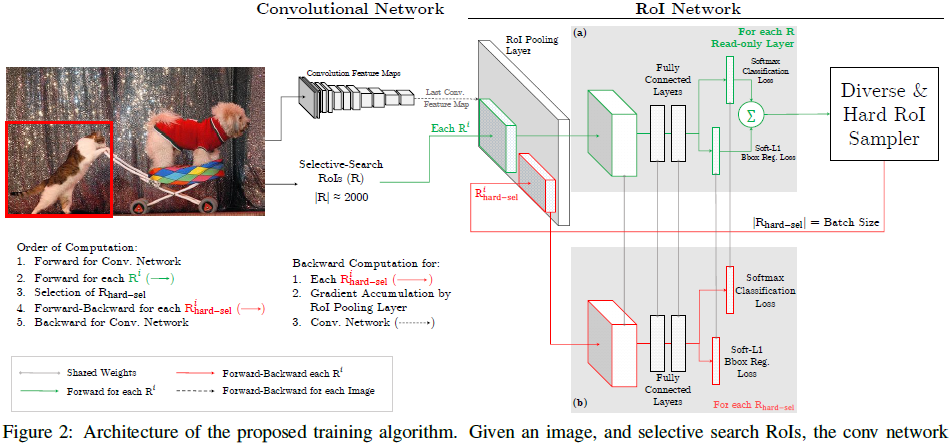
对比可以发现,文章提出的OHEM算法里,对于给定图像,经过selective search RoIs,同样计算出卷积特征图。但是在绿色部分的(a)中,一个只读的RoI网络对特征图和所有RoI进行前向传播,然后Hard RoI module利用这些RoI的loss选择B个样本。在红色部分(b)中,这些选择出的样本(hard examples)进入RoI网络,进一步进行前向和后向传播。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号