


R-FCN论文阅读(R-FCN: Object Detection via Region-based Fully Convolutional Networks )
链接:https://www.zhihu.com/question/68483928/answer/306680428
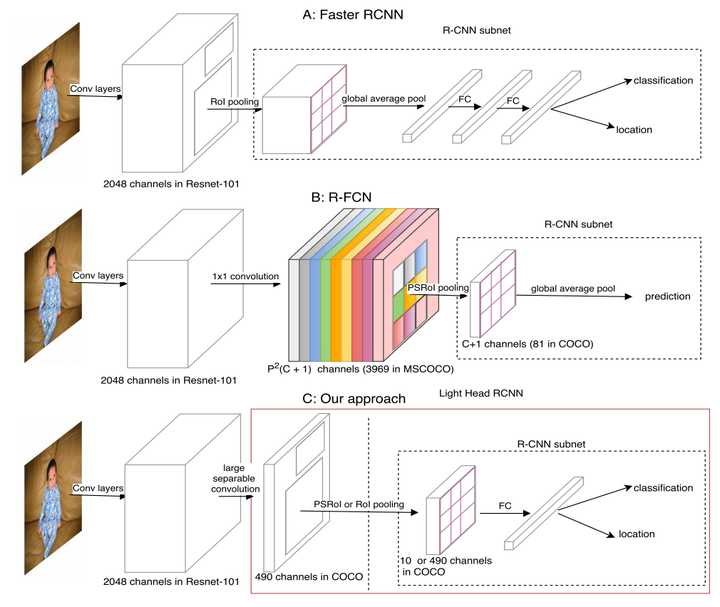 light head文章里的示意图
light head文章里的示意图
这篇文章主要是基于faster rcnn 和 r-fcn 做的改进。
这篇文章将two stage的检测模型分为了两个部分,body和head。body指的是roi pooling之前的网络部分,head指的是roi pooling和r-cnn子网络部分,r-cnn子网络是对roi进行分类和预测roi位置的那一部分。
faster rcnn的roi pooling的channel数很大,有2048,这使得后面的两个fc层计算量很大, 而且faster rcnn的roi数目是很大的,针对每个roi都要调用一次r-cnn子网络,这个开销十分大。
r-fcn在r-cnn子网络前设计了一个score map,试图共享roi的计算,以解决faster rcnn的这个问题,但是引入的score map的channel数很大,是P*P(C+1),C为类别数,在COCO数据集上,这个值为3969(7*7*81),这使得r-fcn的计算量相比faster rcnn小了一些,但依然很大,真是“按下葫芦起来瓢”。
综上,faster rcnn和r-fcn的head计算量都很大,即使body用了轻量化的网络,它们的速度依然比不上one stage的方法。
light head rcnn的目标就是减小head部分的计算量。模型的改进是在r-fcn上进行的。一个很直接的方法就是降低进入head部分feature map的channel数,也就是将r-fcn的score map从P*P(C+1)减小到P*P *α,α是一个与类别数无关且较小的值,比如10。这样,score map的channel数与类别数无关,使得后面的分类不能像r-fcn那样vote,于是在roi pooling之后添加了一个fc层进行预测类别和位置。light head rcnn的head部分前面是r-fcn score map的改进,后面是faster rcnn进行region分类和位置预测的改进。
总体而言,各种深度学习模型(比如检测、分类等等)如果要提高速度,从模型的角度来说,主要的思路其实都是减少模型中冗余的部分,比如减少channell数目、减少层数、用1x1的conv降低channel数目、将普通convolution拆解为depth wise convolution和point wise convolution、将k*k的convolution拆成k*1和1*k两个separable convolution等等。
毫无疑问,深度学习模型中存在着冗余的部分,但是现在深度学习相关理论不成熟,无法去分析一个深度学习模型的capacity,也无法确定一个任务到底需要多大capacity的模型,所以我们不知道哪部分是冗余的,就如同广告业一句名言“ 我知道在广告上的投资有一半是无用的,但问题是我不知道是哪一半”。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号