

实例分割初探,Fully Convolutional Instance-aware Semantic Segmentation论文解读
- 清华大学与微软研究院合作,提出了一种新的架构 FCIS,是首个用于图像实例分割任务的全卷积、端到端的解决方案,该架构在 COCO 2016 图像分割竞赛中获得了第一名。论文现被 CVPR 2017 作为 spotlight paper 接收,代码也已开源:https://github.com/msracver/FCIS
- FCIS 是首个全卷积、端到端的实例分割解决方案,为实例分割提供了一个简单、快速、准确的框架,由于考虑到实例分割预测和分类这两个步骤之间的关联,FCIS 能够同时对多个物体实例进行检测和分割。
1.介绍
现有的主流实例分割方法,几乎都是在常用的物体检测方法的基础上进行简单直接的扩展,对于问题的理解还不够深入,计算效率和精确度都还有很大的提升空间。
例如,对于兴趣区域(Region of Interests, RoI)的分类和分割作为单独的两个步骤进行,没有充分利用这两个任务的关联性;对于分割子网络的训练没有考虑物体类别的差异;对于每个 RoI 运行一个分割子网络导致计算效率低下;RoI Pooling 应该用更精确的对齐方式……
“我们之前在 NIPS 2016 发表的做物体检测的工作 R-FCN,其两个主要思想,一是基于高效的全卷积网络,二是利用位置敏感的 RoI Pooling 打破平移不变性,也都适合用来做实例分割,于是就沿着这个思路做下来了,希望能解决上述问题。”微软研究人员介绍说。
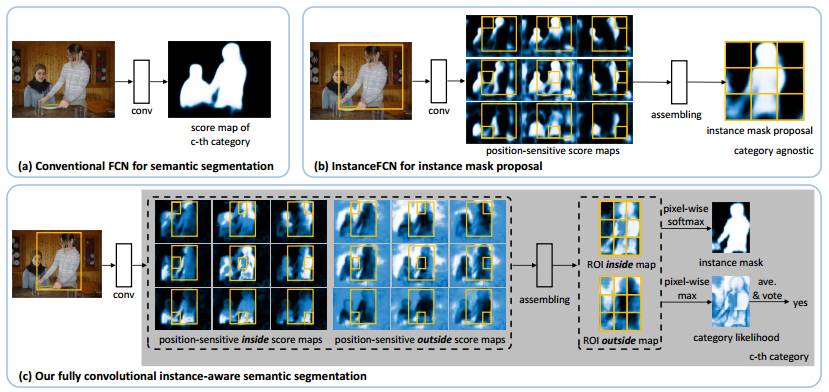
提出 FCIS 的思路示意图。(a) 用于语义分割的全卷积网络(FCN)。每一类都有单独的一张 score map,这张图不会区分单个的物体实例。(b) 用于实例分割预测的 InstanceFCN,一个大小为 3×3 位置敏感的 score map 会将相关的位置信息编码。InstanceFCN 产生一系列的分割候选,后续有一个网络会对这些分割候选做分类判别。(c) 新提出的全卷积实例语义分割方法(FCIS),其中位置敏感的内/外 score maps 会在同一时间对多张连在一起的图像进行分割和检测。
实例分割初探,Fully Convolutional Instance-aware Semantic Segmentation论文解读
进入2017年之后,深度学习计算机视觉领域有了新的发展。在以往的研究中,深度神经网络往往是单任务的,比如图像分类(AlexNet, VGG16等等),图像分割(以FCN为代表的一众论文),目标检测(R-CNN,Fast R-CNN和Fatser R-CNN,以及后来的YOLO和SSD,目标检测领域已经实现多任务)。而在最新的研究中,上述的任务往往被集成了,通过一个框架完成,代表就是实例分割。先来看看实例分割的例子:
第一个是户外的测试结果:

第二个是检测的泰迪熊:

大家可以看到,实例分割的效果一共有三点:
1. 将物体从背景中分离(测试结果上只是没有画出目标框),即目标检测。
2. 对检测到的物体进行逐像素提取,即图像分割。
3. 对检测到的物体进行类别划分,即图像分类。
因此,实例分割是一个很综合的问题,融合了目标检测,图像分割与图像分类。实例分割的结果包含的信息相当丰富,代表作包括Mask R-CNN与本文介绍的FCIS,前者是Facebook团队贡献的(Mask R-CNN的一作何凯明之前也供职于微软),后者是是微软的团队贡献的,下面,笔者就来分析一下FCIS。
首先,要达到“实例分割”效果,我们先来看一下以FCN为代表的传统图像分割算法有什么问题:

上面的图片是一张DeepLab论文中的效果图,图中的白色框和黄色框是笔者自己加上的。大家可以看到,如果是实例分割,在白色框的内部某些像素会被分类成“person”,属于前景,而剩余的像素则是背景。同样地,在黄色框内,某些像素会被划分为"motorcycle",而其余的像素会被划分为背景。那么,在白色框与黄色框重复的区域,有些像素的语义就出现了差池,如在白色框中是背景,在黄色框中是前景。对于这个问题,由于传统的图像分割网络采用交叉熵,结合图像标签端到端训练,在标签中,对于一个像素点,语义类别是固定的,一个像素点只能对应一种固定的语义,由于卷积的平移不变性,一个像素点只能对应一种语义,因此没有办法达到实例分割的效果。也因此,产生了实例分割的问题。
对于这个问题,论文中的阐述是:
However, conventional FCNs do not work for the instance-aware semantic segmentation task, which requires the detection and segmentation of individual object instances. The limitation is inherent. Because convolution is translation invariant, the same image pixel receives the same responses (thus classification scores) irrespective to its relative position in the context. However, instance-aware semantic segmentation needs to operate on region level, and the same pixel can have different semantics in different regions. This behavior cannot be modeled by a single FCN on the whole image.
那么,现存的实例分割领域的方法是如何解决上面的问题呢?主要是通过多任务网络来解决(Multi-task Network),笔者以Instance-aware Semantic Segmentation via Multi-task Network Cascades这篇代表作举例(值得一提的是,这篇文章也是微软团队贡献的,何凯明位居二作,发表于CVPR 2016)。多任务网络是这样做的:首先,通过卷积神经网络先提取初级特征,并提出ROI(region of interest)。然后,对于每个ROI区域,通过ROI Warping和ROI Pooling提取出对应的特征。接着,使用全连接层(FC layer)进行前景与背景的划分(Mask Predictoin)。最后,再针对每一个ROI,使用全连接层(FC layer)进行图像分类。示意图如下(该示意图来自论文):

然后,我们来看一看上述的多任务网络方法有什么问题:
问题1:由于全连接层的输入要求,所有ROI区域都要被转化为相同的尺度,这对于不同尺度的目标(尤其是面积比较大的目标)来说,细节信息损失巨大。大家都知道,全连接层的本质是矩阵乘法,因此需要相同尺度的输入,才能和固定尺度的参数进行矩阵相乘得出结果。那么,所有目标区域(ROI)都要被放大或者缩小成一样的尺度(这个被称为ROI-Pooling技术被Fast R-CNN提出,该论文发表于ICCV 2015,值得一提的是这也是微软团队的工作)。那么,在前景与背景分离这个问题上面,对于面积大的目标区域,是将其缩小之后再进行分离,然后将得到的结果(Mask)放大到原来的尺度作为前景,这样对ROI区域的操作非常容易损失掉目标的细节信息(比如说,车子的轮子在缩小的过程中就没了,再放大之后也不会再有)。
对于问题1,论文做出了如下表述:
First,
the ROI pooling step losses spatial details due to feature warping
and resizing, which however, is necessary to obtain a
fixed-size representation for fc layers.
Such distortion and fixed-size representation degrades the
segmentation accuracy, especially for large objects.
问题2:全连接层参数规模庞大,这种尾大不掉的架构很有可能发生过拟合。从笔者的caffemodel解析这一篇博文中提到了,将一个简单的LeNet模型的可训练参数提取出来,最后两个全连接的参数竟然达到了网络参数规模的90%以上。由于这个问题,训练与测试的代价也会增多。
对于问题2,论文做出了如下表述:
Second, the fc layers over-parametrize the task, without using regularization of local weight sharing.
问题3:在ROI区域提出后,图像分割的子任务与图像分类的子任务之间没有共享参数。大家从上图可以看到,在图标区域提出后,图像分割任务与图像分类任务都是各自训练不同的全连接层,这样使得架构的效率异常低下。
对于问题3,论文做出了如下表述:
Last, the per-ROI network computation in the last step is not shared among ROIs. As observed empirically, a considerably complex sub-network in the last step is necessary to obtain good accuracy. It is therefore slow for a large number of ROIs (typically hundreds or thousands of region proposals).
针对以上3个问题,我们来看看FCIS是怎么解决的。
首先针对问题1,ROI-Pooling被取消了,取而代之的是对ROI区域的聚合,实质就是复制粘贴。
然后针对问题2,全连接层(FC layer)被取消了,取而代之的是分类器(softmax)。
最后,针对问题3,图像分割与图像分类使用的是相同的特征图。
下面详细讲述一下FCIS的解决方案。
对于卷积层的平移不变性,本文采用的方法是生成若干组特征图(k×k组),但这个方法并不是FCIS的首创,而是在论文Instance-sensitive fully convolutional networks中提出,该篇论文发表于ECCV 2016。值得一提的是,这篇论文依然是微软团队的作品,何凯明依然是二作。该篇论文提出的方案采用了如下的做法:

对于每一张输入图片,生成k×k组特征图(在上图的例子中k为3),每一组特征图,称为score map。每一组score map,表示的是输入图像中每一个ROI的不同位置的分数(score)。比如,左上角的一张score map,代表的就是输入图像中每一个ROI中的左上角部分(标志为1的小框内部)的score,其他的类推。score代表的含义是某个特定位置(小窗)的像素点属于ROI中的前景的分数。
那么,这么做有什么好处呢?这样做解决了卷积的平移不变性带来的问题,使得不同ROI中的重叠区域在不同ROI中的score是不一样的。见下图所示:
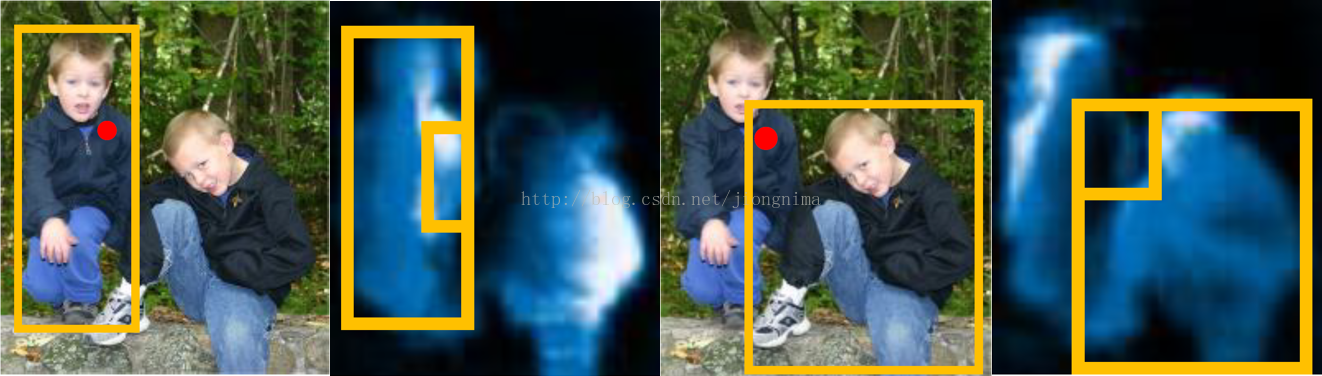
大家可以看到,输入图像中的红点区域被不同ROI共享,那么,在不同的score map中,该区域对应的score完全不同。这就很好的实现了,相同区域,不同语义的问题。
那么,这样做可以解决图像分割这个子问题。可是,没法解决图像分类的问题。对于图像分类的问题,目前的方案往往是采用一个后续的网络进行,也就是说,图像分割和图像分类的子任务还是串联方式完成的,并没有并联。
针对上述的问题,FCIS是怎么实现图像分类与图像分割的并联呢?答案是通过两类score map解决,一类叫inside score map,一类叫outside score map。inside score map表征了像素点在ROI区域内部中前景的分数,如果一个像素点是位于一个ROI区域内部并且是目标(前景),那么在inside score map中就应该有较高的分数,而在outside score map中就应该有较低的分数。反之亦然,如果一个像素点是位于一个ROI区域内部并且是背景,那么在inside score map中就应该有较低的分数,而在outside score map中就应该有较高的分数。针对图像分割,使用两类score map,通过一个分类器就可以分出前景与背景。针对图像分类,将两类score map结合起来,可以实现分类问题。
这样做还有一个好处,通过两类score map的结合,可以甄别出ROI检测失误的区域。

对于上面的描述,论文中的原句是:
For
each pixel in a ROI, there are two tasks: 1) detection: whether it
belongs to an object bounding box at a relative position (detection+)
or not (detection-); 2) segmentation: whether it is inside an object
instance’s boundary (segmentation+) or not (segmentation-).
大家可以看到,上图中的left/right: position-sensitive inside/outside score maps,分别表示了所有ROI中的不同区域的inside/outside scores。为啥是所有ROI呢?因为这一系列score map是所有ROI共享的,大家可以留心上图中从上到下三组inside/outside score maps(每组18张)都是相同的。
针对图像分割任务和图像分类任务的并行,FCIS这样处理:
首先,对于每个ROI区域,将inside score maps和outside score maps中的小块特征图复制出来,拼接成为了ROI inside map和ROI outside map。针对图像分割任务,直接对上述两类map通过softmax分类器分类,得到ROI中的目标前景区域(Mask)。针对图像分类任务,将两类map中的score逐像素取最大值,得到一个map,然后再通过一个softmax分类器,得到该ROI区域对应的图像类别。在完成图像分类的同时,还顺便验证了ROI区域检测是否合理,具体做法是求取最大值得到的map的所有值的平均数,如果该平均数大于某个阈值,则该ROI检测是合理的。
针对输入图像上的每一个像素点,有三种情况:第一种情况是inside score高,outside score低;则该像素点位于ROI中的目标部分。第二种情况是inside score低,outside score高,则该像素点位于ROI中的背景部分。第三种情况是inside score和outside score都很低,那么该像素点不在任何一个ROI里面。因此,我们在上一段中描述的,针对ROI inside map和ROI outside map中逐像素点取最大值得到的图像:如果求平均后分数还是很低,那么,我们可以断定这个检测区域是不合理的。如果求平均后分数超过了某个阈值,我们就通过softmax分类器求ROI的图像类别,再通过softmax分类器求前景与背景。
对于上面的阐述,论文中的原句如下:
Our
joint formulation fuses the two answers into two scores: inside and
outside. There are three cases: 1) high inside score and low outside
score: detection+, segmentation+; 2) low inside score and high outside
score: detection+, segmentation-; 3) both scores are low:
detection-, segmentation-. The two scores answer the two
questions jointly via softmax and max operations. For detection, we use
max to differentiate cases 1)-2) (detection+) from case 3)
(detection-). The detection score of the whole ROI is then obtained via
average pooling over all pixels’ likelihoods (followed by a softmax
operator across all the categories). For segmentation, we
use softmax to differentiate cases 1) (segmentation+) from 2)
(segmentation-), at each pixel. The foreground mask (in probabilities)
of the ROI is the union of the per-pixel segmentation scores (for
each category).
FCIS的架构如下所示:

图像输入进来,经过卷积层提取初步特征,然后利用这些特征,一边经过RPN(Region Proposal Network)网络提取ROI区域,一边再经过一些卷积层生成2×(C+1)×k×k个特征图。2代表inside和outside两类;C+1代表图像类别一共C类,再加上背景(未知的)1类;k×k代表每一类score map中各有k个(上图的例子中k就为3)。在经过assembling之后(其实就是复制粘贴),对于每一个ROI,k×k个position-sensitive score map被综合成了一个,然后放小了16倍(长宽各变成1/4),得到2×(C+1)个特征图。然后开始并行操作,第一条线:对于每一类的ROI inside map和ROI outside map逐像素取最大值,得到了C+1个特征图,对这C+1个特征图逐个求平均值,将平均值同阈值比较,若大于阈值,则判定该ROI合理,则直接送入softmax分类器进行分类,得到图像类别。若小于阈值,则不进行任何操作。第二条线:做C+1次softmax分类,对每一个类别得到前景与背景,然后根据第一条并行线的分类结果,选择出对应类别的前景与背景划分结果。
对于训练过程,对于每一个ROI,loss由三部分组成,如下表述:
1. 在C+1类上面的分类loss(softmax loss)。
2. 对于positive ROI,有一个前景与背景的分类loss(softmax loss)。
3. 对于positive ROI,有一个包围框回归的loss(L1 loss)(由Fast R-CNN提出)
positive ROI指的是,这个ROI与Ground Truth上面与其最近的目标包围框重叠区域占比在0.5以上。
论文中的表述如下:
Training: An ROI is positive if its box IoU with respect to the nearest ground truth object is larger than 0:5, otherwise it is negative. Each ROI has three loss terms in equal weights: a softmax detection loss over C + 1 categories, a softmax segmentation loss over the foreground mask of the ground-truth category only, and a bbox regression loss as in. The latter two loss terms are effective only on the positive ROIs.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号