FlinkCDC 2.0使用实践体验
一、背景说明
所谓CDC:全称是 Change Data Capture ,在广义的概念上,只要能捕获数据变更的技术,我们都可以称为 CDC 。通常我们说的 CDC 技术主要面向数据库的变更,是一种用于捕获数据库中数据变更的技术。
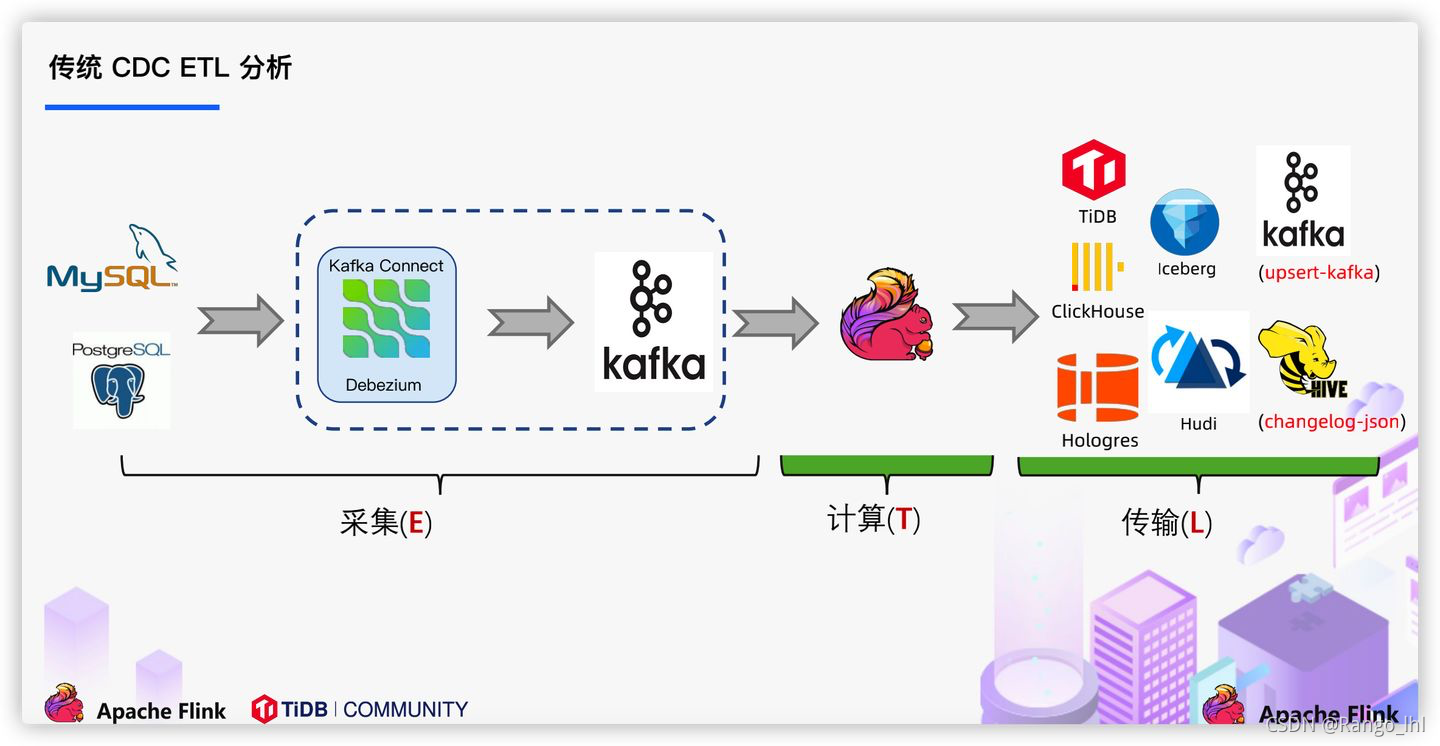
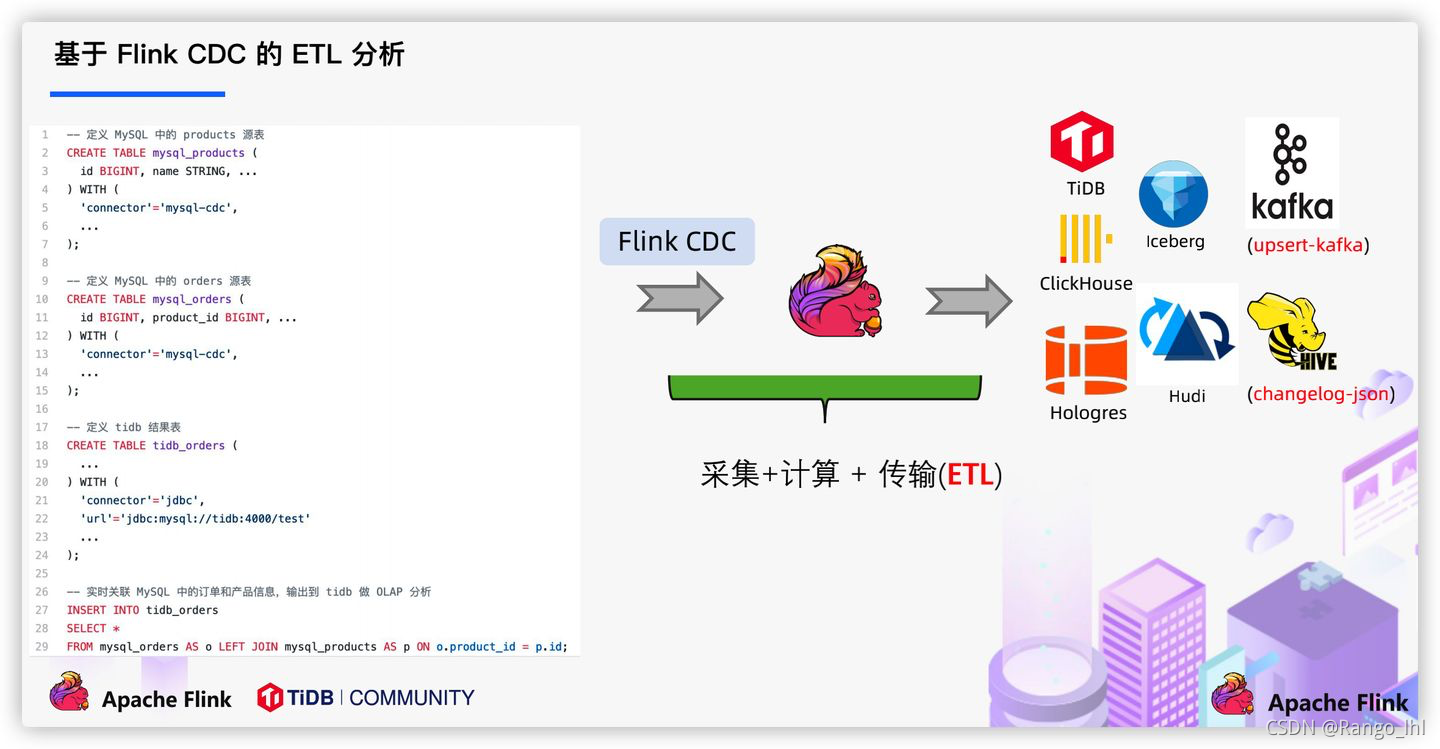
目前实时链路对于数据的处理是大多数使用的方案是通过工具,对业务数据日志的监控(如canal/maxwell),并连接到kafka,实现对业务数据的实时获取,在实时数仓架构上,ods层一般也会设计在kafka(数据入湖另外说),参考下面图1。而通过FlinkCDC则可以在确保数据一致性的前提下,绕过消息中间组件,Flink实现对数据的直接处理,减少数据的流转链路,另外,由于还支持分布式处理,因此可以获得比canal等组件更高的效率,流程如下面图2。
二、代码部分
关于版本兼容一点说明:使用StreamAPI的话,1.12的版本是支持CDC2.0,如若使用FlinkSQL,需按照官方指定的版本,使用1.13

/**
* @Author: Rango
* @Date: 2021/09/12/下午10:25
* @Description: FlinkCDC监控MySQ,DataStream写法,demo不写checkpoint
*/
public class flincdc {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
DebeziumSourceFunction<String> mysqlSource = MySqlSource.<String>builder()
.hostname("localhost")
.port(3306)
.username("root")
.password("123456")
.databaseList("test_cdc")
.tableList("test_cdc.cdc_flink") //必须加库名
.deserializer(new myDeserializationSchema()) //自定义反序列化
//.deserializer(new StringDebeziumDeserializationSchema()) //原反系列化器
.startupOptions(StartupOptions.initial())
.build();
DataStreamSource<String> mysqlDS = env.addSource(mysqlSource);
mysqlDS.print();
env.execute();
}
}
//自定义反序列化器
class myDeserializationSchema implements DebeziumDeserializationSchema<String> {
/*
期望输出效果
{
db:数据库名
tb:表名
op:操作类型
befort:{} 数据修改前,create操作没有该项
after:{} 数据修改后,delete操作没有该项
}
*/
public void deserialize(SourceRecord sourceRecord, Collector<String> collector) throws Exception {
JSONObject result = new JSONObject();
String[] split = sourceRecord.topic().split("\\.");
result.put("db",split[1]);
result.put("tb",split[2]);
//获取操作类型
Envelope.Operation operation = Envelope.operationFor(sourceRecord);
result.put("op",operation.toString().toLowerCase());
Struct value =(Struct)sourceRecord.value();
JSONObject after = getValueBeforeAfter(value, "after");
JSONObject before = getValueBeforeAfter(value, "before");
if (after!=null){result.put("after",after);}
if (before!=null){result.put("before",before);}
collector.collect(result.toJSONString());
}
public JSONObject getValueBeforeAfter(Struct value,String type){
Struct midStr = (Struct)value.get(type);
JSONObject result = new JSONObject();
if(midStr!=null){
List<Field> fields = midStr.schema().fields();
for (Field field : fields) {
result.put(field.name(),midStr.get(field));
}
return result;
}return null;
}
public TypeInformation<String> getProducedType() {
return BasicTypeInfo.STRING_TYPE_INFO;
}
}
效果展示:
#监控的MySQL数据库对应的表结构及数据如下:
mysql> select * from test_cdc.cdc_flink;
+------+----------+--------+
| id | name | sex |
+------+----------+--------+
| 1001 | zhangsan | female |
| 1002 | lisilsi | male |
+------+----------+--------+
2 rows in set (0.00 sec)
#命令行提交jar包
./bin/flink run -c com.hll.flincdc FlinkCDC-1.0-SNAPSHOT-jar-with-dependencies.jar
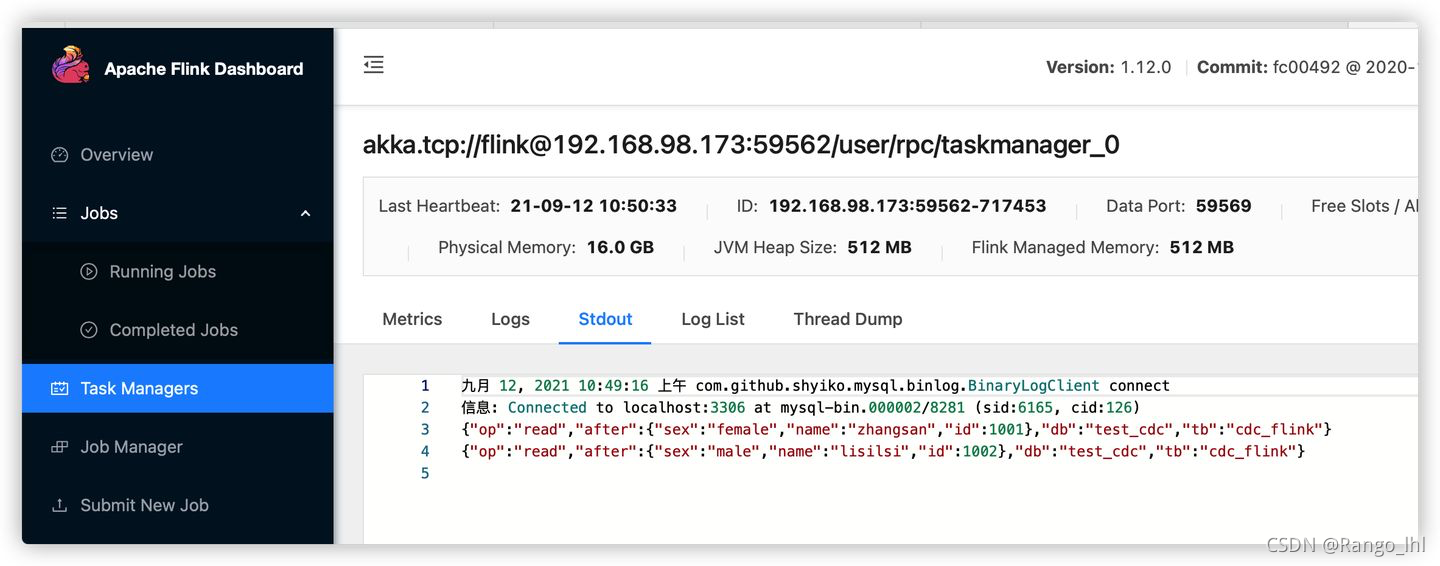
默认 initial 模式,也就是任务启动会把数据库原有数据全打印出来。其他模式在第三部分介绍
三、2.0版本的主要优化点说明
在1.x的版本有如下提到的几个问题,而在2.0的版本,则实现了无锁读取的方式来实现一致性的保证,并且全量读取支持checkpoint,失败无需从头再开启任务。

所谓无锁读取的方式则是通过全量数据chunk切分后并行读取,通过高低水位的方式来确保全量数据一致性读取,而增量部分则是单线程汇报方式,碍于篇幅此处不做源码解读,感兴趣可以看看源码BlinlogSplit部分。
四、其他说明
- 关于反序列那块,由于cdc直连数据库会有太多冗余信息,只提取需要内容即可,原生内容为SourceRecord对象,对内容进行对应提取即可,SourceRecord对象完整内容如下:
SourceRecord{sourcePartition={server=mysql_binlog_source}, sourceOffset={ts_sec=1631413470, file=mysql-bin.000002, pos=8281, snapshot=true}} ConnectRecord{topic='mysql_binlog_source.test_cdc.cdc_flink', kafkaPartition=null, key=Struct{id=1001}, keySchema=Schema{mysql_binlog_source.test_cdc.cdc_flink.Key:STRUCT}, value=Struct{after=Struct{id=1001,name=zhangsan,sex=female},source=Struct{version=1.5.2.Final,connector=mysql,name=mysql_binlog_source,ts_ms=1631413470946,snapshot=true,db=test_cdc,table=cdc_flink,server_id=0,file=mysql-bin.000002,pos=8281,row=0},op=r,ts_ms=1631413470950}, valueSchema=Schema{mysql_binlog_source.test_cdc.cdc_flink.Envelope:STRUCT}, timestamp=null, headers=ConnectHeaders(headers=)}
- 关于连接source的模式,可以先看官网介绍:
initial (default): Performs an initial snapshot on the monitored database tables upon first startup, and continue to read the latest binlog.
latest-offset: Never to perform snapshot on the monitored database tables upon first startup, just read from the end of the binlog which means only have the changes since the connector was started.
简单理解,initial是默认模式,cdc任务启动后会把数据库中表原数据全打印出来,可用于历史全量历史数据的输出,而last-offset则是任务启动后,以后数据库有数据变更cdc才有数据输出,用于只关注增量数据的方式。
- FlinkSQL的写法比较简单,上面的例子,则写法如下:
//注意sql写法必须指定表,每次只能读一张表,stramapi的方式可以监控整个库
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
tableEnv.executeSql("CREATE TABLE mysql_binlog (" +
" id INT NOT NULL," +
" name STRING," +
" sex STRING," +
" PRIMARY KEY(id) NOT ENFORCED" +
") WITH (" +
" 'connector' = 'mysql-cdc'," +
" 'scan.startup.mode' = 'latest-offset'," +
" 'hostname' = 'localhost'," +
" 'port' = '3306'," +
" 'username' = 'root'," +
" 'password' = '123456'," +
" 'database-name' = 'test_cdc'," +
" 'table-name' = 'cdc_flink')");
学习交流,有任何问题还请随时评论指出交流。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号