
HDFS读写过程-从类调用角度
一、HDFS相关类说明
FileSystem:通用文件系统的抽象基类,可以被分布式文件系统继承,所有可能使用Hadoop文件系统的代码都要使用到这个类。
DistributedFileSystem:Hadoop为FileSystem这个抽象类提供了多种具体的实现,DistributedFileSystem就是FileSystem在HDFS文件系统中的实现。
FSDataInputStream:FileSystem的open()方法返回的是一个输入流FSDataInputStream对象,在HDSF文件系统中具体的输入流就是DFSInputStream。
FSDataOutputStream:FileSystem的create()方法返回的是一个输出流FSDataOutputStream对象,在HDFS文件系统中具体的输出流就是DFSOutputStream。
二、读数据的过程
客户端连续调用open()、read()、close()读取数据时,HDFS内部执行流程如下:
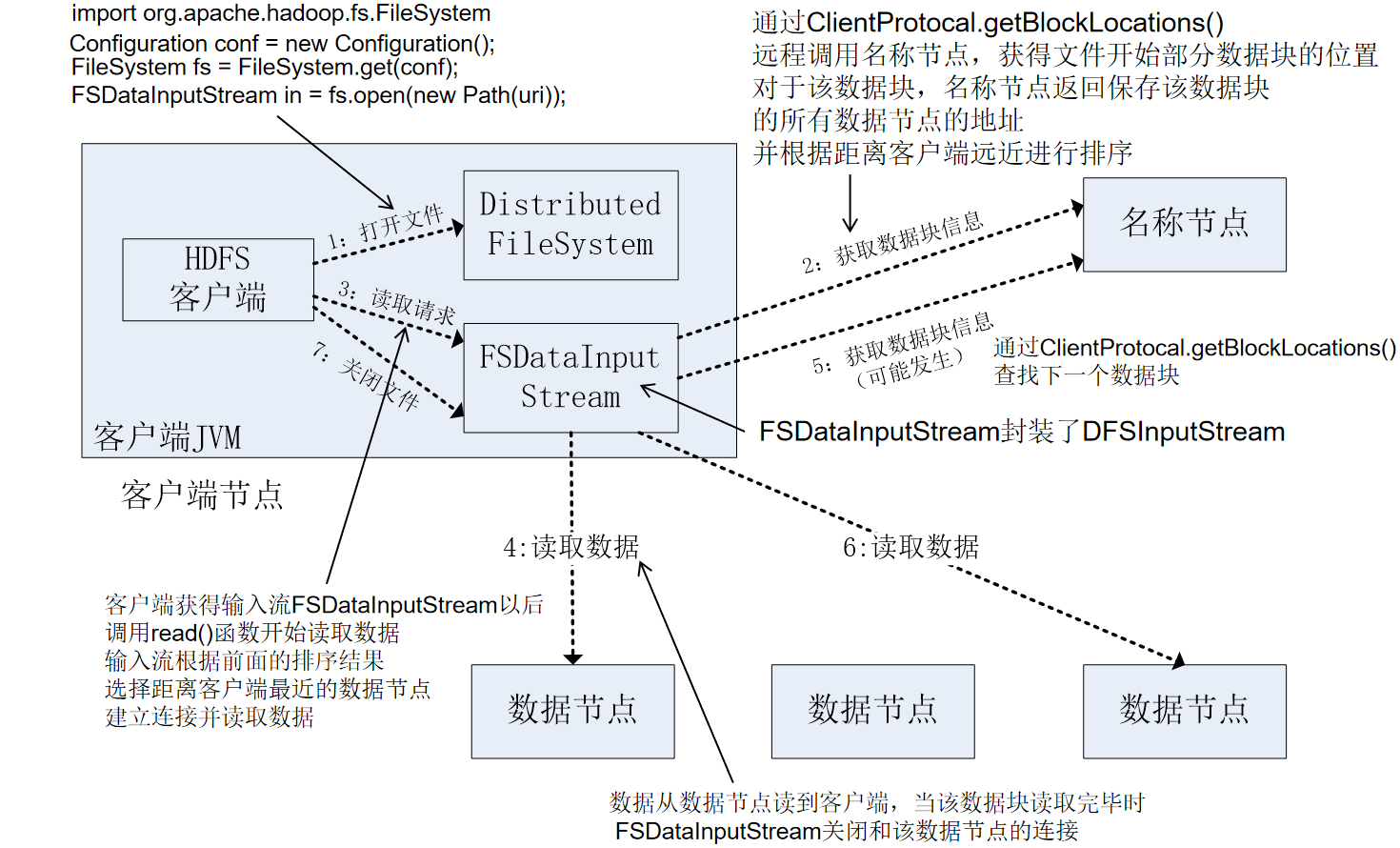
- 客户端通过FileSystem.open()打开文件,相应的,在HDFS文件系统中DistributedFileSystem具体实现了FileSystem。因此,调用open()方法后,DistributedFileSystem会创建输入流FSDataInputStream,对于HDFS而言,具体的输入流就是DFSInputStream。
- 在DFSInputStream的构造函数中,输入流通过ClienProtocal.getBlockLocations()远程调用名称节点,获得文件开始部分数据块的保存位置。对于该数据块,名称节点返回保存该数据块的所有数据节点的地址,同时根据距离客户端的远近对数据节点进行排序;然后,DistributedFileSystem会利用DFSInputStream来实例化FSDataInputStream,返回给客户端,同时返回了数据块的数据节点地址。
- 获得输入流FSDataInputStream后,客户端调用read()函数开始读取数据。输入流根据前面的排序结果,选择距离客户端最近的数据节点建立连接并读取数据。
- 数据从该数据节点读到客户端;当该数据块读取完毕时,FSDataInputStream关闭和该数据节点的连接。
- 输入流通过getBlockLocations()方法查找下一个数据块(如果客户端缓存中已经包含了该数据块的位置信息,就不需要调用该方法)。
- 找到该数据块的最佳数据节点,读取数据。
当客户端读取完毕数据的时候,调用FSDataInputStream的close()函数,关闭输入流。
ps:在读取数据的过程中,如果客户端与数据节点通信时出现错误,就会尝试连接包含此数据块的下一个数据节点
代码举例:
import java.io.BufferedReader;
import java.io.InputStreamReader;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.FSDataInputStream;
public class Hdfsread {
public static void main(String[] args) {
try {
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://localhost:9000");
conf.set("fs.hdfs.impl","org.apache.hadoop.hdfs.DistributedFileSystem");
FileSystem fs = FileSystem.get(conf);
Path file = new Path("test");
FSDataInputStream getIt = fs.open(file);
BufferedReader d = new BufferedReader(new InputStreamReader(getIt));
String content = d.readLine(); //读取文件一行
System.out.println(content);
d.close(); //关闭文件
fs.close(); //关闭hdfs
} catch (Exception e) {
e.printStackTrace();
}
}
}
三、写数据过程
客户端向HDFS写数据是一个复杂的过程,客户端连续调用create()、write()和close()时,HDFS内部执行过程如下:(ps:不发生任何异常情况)
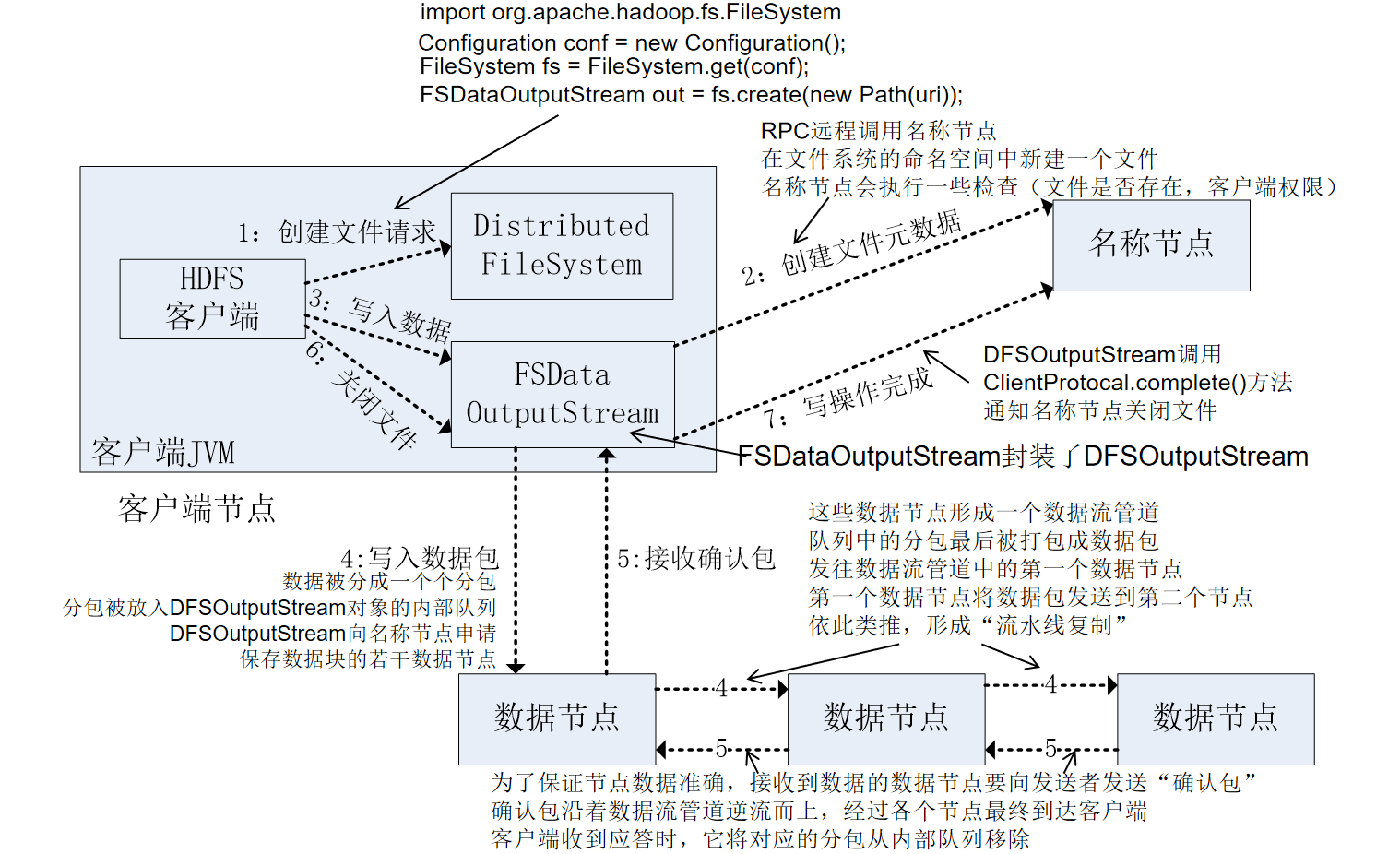
- 客户端通过FileSystem.create()创建文件,相应的,在HDFS文件系统中DistributedFileSystem具体实现了FileSystem。因此,调用create()方法后,DistributedFileSystem会创建输出流FSDataOutputStream,对于HDFS而言,具体的输出流就是DFSOutputStream。
- DistributedFileSystem通过RPC远程调用名称节点,在文件系统的命名空间中创建一个新的文件。名称节点会执行一些检查,比如文件是否已经存在、客户端是否有权限创建文件等。检查通过之后,名称节点会构造一个新文件,并添加文件信息。远程方法调用结束后,DistributedFileSystem会利用DFSOutputStream来实例化FSDataOutputStream,返回给客户端,客户端使用这个输入流写入数据。
- 获得输出流FSDataOutputStream以后,客户端调用输出流的write()方法向HDFS中对应的文件写入数据。
- 客户端向输出流FSDataOutputStream中写入的数据会首先被分成一个个的分包,这些分包被放入DFSOutputStream对象的内部队列。输出流FSDataOutputStream会向名称节点申请保存文件和副本数据块的若干个数据节点,这些数据节点形成一个数据流通道。队列中的分包最后被打包成数据包,发往数据流管道中的第一个数据节点,第一个数据节点将数据包发送给第二个数据节点,第二个数据节点将数据包发送给第三个数据节点,这样,数据包会流经管道上的各个数据节点(流水线复制策略)。
- 因为各个数据节点位于不同的机器上,数据需要通过网络发送。因此,为了保证所有的数据节点的数据都是准确的,接收到数据的数据节点要向发送者发送“确认包”(ACK Packet)。确认包沿着数据流管道逆流而上,从数据流管道依次通过各个数据节点并最终发往客户端,当客户端收到应答时,它将对应的分包从内部队列移除。不断执行3~5步骤,直到数据全部写完。
- 客户端调用close()方法关闭输出流,此时开始,客户端不会再向输出流写入数据,所以,当DFSOutputStream对象内部队列的分包都收到应答后,就可以使用ClientProtocol.complete()方法通知名称节点关闭文件,完成一次正常的写文件过程。
代码举例:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.Path;
public class Hdfswrite {
public static void main(String[] args) {
try {
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://localhost:9000");
conf.set("fs.hdfs.impl","org.apache.hadoop.hdfs.DistributedFileSystem");
FileSystem fs = FileSystem.get(conf);
byte[] buff = "Hello world".getBytes(); // 要写入的内容
String filename = "test"; //要写入的文件名
FSDataOutputStream os = fs.create(new Path(filename));
os.write(buff,0,buff.length);
System.out.println("Create:"+ filename);
os.close();
fs.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
四、简单总结
读的过程:
- 客户端访问名称节点,查询并获取文件的数据块位置列表,返回输入流对象。
- 就近挑选一台数据节点服务器,请求建立输入流 。
- 数据节点向输入流中中写数据。
- 关闭输入流。
写的过程:
- 客户端向名称发出写文件请求。
- 检查是否已存在文件、检查权限。若通过检查,返回输出流对象。
- 客户端按128MB的块切分文件。
- 客户端将名称节点返回的分配的可写的数据节点列表和Data数据一同发送给最近的第一个数据节点,此后客户端和名称节点分配的多个数据节点构成pipeline管道,客户端向输出流对象中写数据。客户端每向第一个写入一个packet,这个packet便会直接在pipeline里传给第二个、第三个…数据节点。
- 每个数据节点写完一个块后,会返回确认信息。
- 写完数据,关闭输输出流。
- 发送完成信号给名称节点。
补充2:若通过检查,直接先将操作写入EditLog,WAL(write aheadlog)操作,先写log在写内存,写入失败通过EditLog记录校验。
补充4:packet默认64k。
补充5:写完一个block块后汇总确认,不会每个packet确认。
补充7:HDFS一般情况下都是强调强一致性,即所有数据节点写完后才向名称节点汇报。
Reference:
dblab.xmu.edu.cn
blog.csdn.net/qq_38202756/article/details/82262453
学习交流,有任何问题还请随时评论指出交流。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号