Spark Structured Streaming延迟数据处理实例
一、Spark中水印作用
Spark内部引擎的实现是保留内部状态的,以便让基于事件时间的窗口聚合可以更新旧的数据,但是如果一个查询持续运行多天,那么系统绑定中间状态累积的数量也会随之增加,为了释放资源,用户可以通过自定义水印来告知系统可以丢弃哪些在内存中旧状态的数据。自定义水印可以使用withWatermark()方法。
二、延迟数据处理实例(基于pyspark)
通过一个实例说明,Spark如何处理迟到数据以及水印在迟到数据处理的作用。
该实例中,首先建立一个基于CSV文件的输入源,模拟实时写入CSV文件,并构造不同的正常到达和迟到的数据;然后,在控制台观察Structured Streaming的输出。CSV文件每行包含两个字段,第一个字段为事件时间的说明,如“一小时以内延迟到达”“正常”等;第二个字段为事件时间。我们对不同的事件时间和时间的说明进行更改和组合,然后在控制台观察不同的程序执行结果。
操作系统:Ubuntu20.04
JDK版本:1.8或以上版本
Spark版本:2.4.0
Python版本:3.6.8(手动降级)
hadoop:2.7.1
在/usr/local/spark/mycode/structuredstreaming/watermark路径下新建spark_ss_test_delay.py文件,代码如下:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import os
import shutil
import time
from functools import partial
from pyspark.sql import SparkSession
from pyspark.sql.functions import window
from pyspark.sql.types import StructType, StructField
from pyspark.sql.types import TimestampType, StringType
#CSV文件路径
TEST_DATA_DIR = '/tmp/testdata/'
TEST_DATA_DIR_SPARK = 'file:///tmp/testdata/'
#判断文件路径是否存在函数
def test_setUp():
if os.path.exists(TEST_DATA_DIR):
shutil.rmtree(TEST_DATA_DIR, ignore_errors=True)
os.mkdir(TEST_DATA_DIR)
#恢复测试环境,对CSV文件夹进行清理
def test_tearDown():
if os.path.exists(TEST_DATA_DIR):
shutil.rmtree(TEST_DATA_DIR, ignore_errors=True)
#写入文件函数
def write_to_csv(filename, data):
with open(TEST_DATA_DIR + filename, "wt", encoding="utf-8") as f:
f.write(data)
if __name__ == "__main__":
test_setUp()
schema = StructType([StructField("word", StringType(), True),StructField("eventTime", TimestampType(), True)])
spark = SparkSession.builder.appName("SNWCW_DELAY").getOrCreate()
spark.sparkContext.setLogLevel('WARN')
lines = spark.readStream.format('csv').schema(schema).option("sep",";").option("header","false").load(TEST_DATA_DIR_SPARK)
#定义窗口
windowDuration = '1 hour'
windowCounts = lines.withWatermark("eventTime", "1 hour").groupBy('word', window('eventTime', windowDuration)).count()
#水印的输出模式必须是append或者update,complete要求保留所有的聚合数据,导致中间状态无法被清理
query = windowCounts.writeStream.outputMode("update").format("console").option('truncate','false').trigger(processingTime="9 seconds").start()
#写入测试文件file1.csv
write_to_csv('file1.csv',"""
正常;2020-10-01 08:00:00
正常;2020-10-01 08:10:00
正常;2020-10-01 08:20:00
""")
#处理当前数据
query.processAllAvailable()
#此时时间时间更新到上次看到的最大的2020-10-01 08:20:00
write_to_csv('file2.csv',"""
正常;2020-10-01 20:00:00
一小时以内延迟到达;2020-10-01 07:20:00
一小时以内延迟到达;2020-10-01 07:30:00
""")
#处理当前数据
query.processAllAvailable()
#此时时间时间更新到上次看到的最大的2020-10-01 20:00:00
write_to_csv('file3.csv',"""
正常;2020-10-01 20:00:00
一小时以外延迟到达;2020-10-01 10:00:00
一小时以外延迟到达;2020-10-01 10:50:00
一小时以内延迟到达;2020-10-01 19:00:00
""")
#处理当前数据
query.processAllAvailable()
query.stop()
test_tearDown()
运行结果如下:
/usr/local/spark/bin/spark-submit spark_ss_test_delay.py
ps:spark流数据存储需要用到hdfs,请确保hdfs开启
运行结果Batch1 Batch3两个空结果,理论上应该不会出现,暂时没发现原因,可能是vmware资源太少延迟导致,不影响
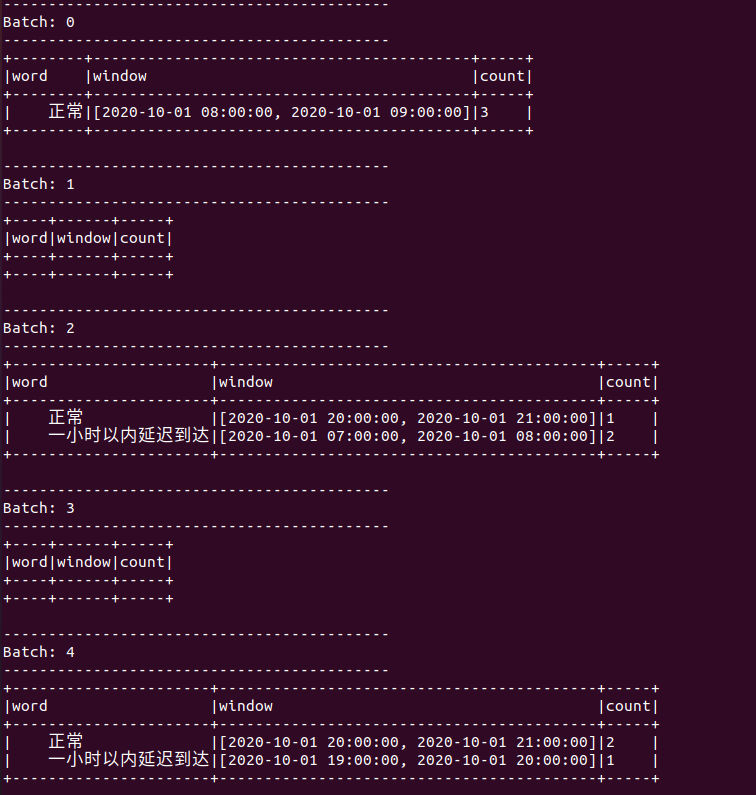
可以看到,一个小时以外延迟到达的数据由于水印的设置被Spark丢弃,而一个小时以内延迟到达的数据则会被正常处理。
学习交流,有任何问题还请随时评论指出交流。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号