十大接口
十大接口
一、Response响应封装
1.1封装
from rest_framework.response import Response
class APIResponse(Response):
def __init__(self, status=0, msg="ok", results=None, http_status=None, headers=None, exception=False, **kwargs):
data_dic = { # json的response基础有数据状态码和数据状态信息
"status": status,
"msg": msg,
}
if results is not None: # 后台有数据,响应数据
data_dic['results'] = results
if kwargs:
data_dic.update(**kwargs) # 后台的一切自定义响应数据直接放到响应数据data中
super().__init__(data=data_dic, status=http_status, headers=headers, exception=exception)
1.2使用
class MyAPIView(APIView):
def get(self, request, *args, **kwargs):
pk = kwargs.get("pk")
if pk:
book_obj = models.Book.objects.filter(pk=pk).first()
if not book_obj:
return APIResponse(status=1, msg='get error')
book_ser = BookSerializers(book_obj).data
print(book_ser)
return APIResponse(results=book_ser)
else:
book_obj = models.Book.objects.all()
book_list_obj = BookSerializers(book_obj, many=True).data
print(book_list_obj)
return APIResponse(results=book_list_obj)
二、ModelSerializer扩展
2.1连表查询
# models.py
class Book(BaseModel): # 书
name = models.CharField(max_length=49)
price = models.DecimalField(max_digits=5, decimal_places=2)
# 出版社与书是一对多的关系, 设置反向查询字段 断外键之间的关系 设置级联,不进行级联删除(出版社删了,书不删) 一对多关系
publish = models.ForeignKey(to="Publish", related_name="books", db_constraint=False, on_delete=models.DO_NOTHING)
# 书与作者是多对多的关系 断关联
# 在多对多外键实际在关系表中,ORM默认关系表中两个外键都是级联
# ManyToManyField字段不提供设置on_delete,如果想设置关系表级联,只能手动定义创建第三张关系表
author = models.ManyToManyField(to="Author", related_name="books", db_constraint=False)
# 自定义连表深度,不需要反序列化,因为自定义插拔属性不参与反序列化
@property
def publish_name(self):
return self.publish.name
# 连表查询
@property
def author_list(self):
temp_author_list = []
for author in self.author.all():
temp_author_list.append({
'name': author.name,
'sex': author.get_sex_display(),
'mobile': author.detail.mobile
})
return temp_author_list
# serializers.py 序列化类
class BookSerializers(serializers.ModelSerializer):
class Meta:
model = models.Book
fields = ("name", "price", "publish_name" ,"author_list")
# views.py
class MyAPIView(APIView):
# 单查和群查
def get(self, request, *args, **kwargs):
pk = kwargs.get("pk")
if pk:
# 单挑数据
book_obj = models.Book.objects.filter(pk=pk, is_delete=False).first()
if not book_obj:
return APIResponse(status=1, msg='get error')
book_ser = BookSerializers(book_obj,many=False).data
print(book_ser)
return APIResponse(results=book_ser)
else:
book_obj = models.Book.objects.all()
# 全部数据
book_list_obj = BookSerializers(book_obj, many=True).data
print(book_list_obj)
return APIResponse(results=book_list_obj)
总结
- 连表查询在modes.py中自定义的字段,一旦其中的逻辑出错,他对应的返回值就不会做出任何响应
- 自定义连表深度,不需要反序列化,因为自定义插拔属性不参与反序列化
- 子序列化可以辅助快速实现自定义外键深度的序列化,但是不能进行反序化,__all__
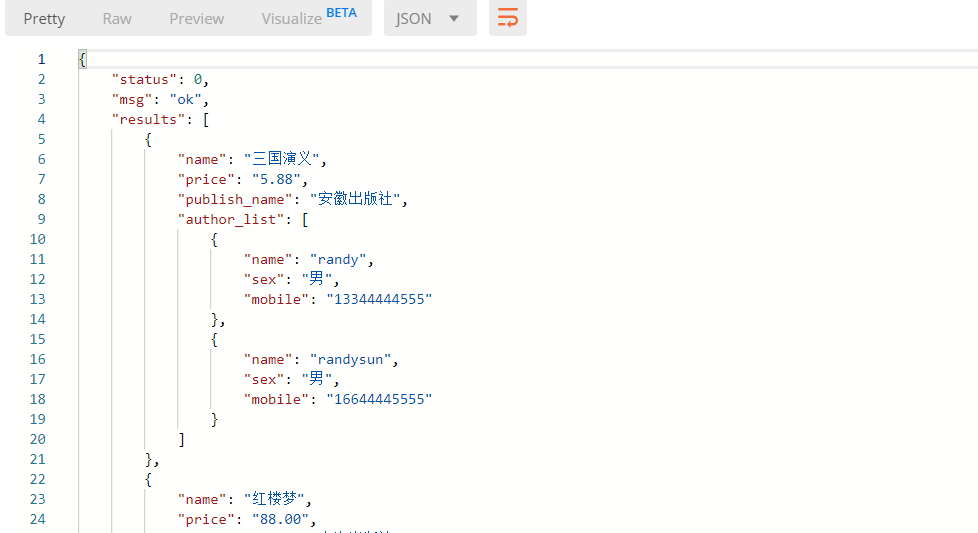
2.2指定字段
1) 使用fields来明确字段, __all__ 表名包含所有字段,也可以写明具体哪些字段,如
class BookInfoSerializer(serializers.ModelSerializer):
"""图书数据序列化器"""
class Meta:
model = BookInfo
fields = "__all__"
2) 使用exclude可以明确排除掉哪些字段
class BookInfoSerializer(serializers.ModelSerializer):
"""图书数据序列化器"""
class Meta:
model = BookInfo
exclude = ('id',)
3) 指明只读字段
可以通过read_only_fields指明只读字段,即仅用于序列化输出的字段
class BookInfoSerializer(serializers.ModelSerializer):
"""图书数据序列化器"""
class Meta:
model = BookInfo
fields = ('id', 'btitle', 'bpub_date', 'bread', 'bcomment')
read_only_fields = ('id', 'bread', 'bcomment')
3、添加额外参数
我们可以使用extra_kwargs参数为ModelSerializer添加或修改原有的选项参数
class BookInfoSerializer(serializers.ModelSerializer):
"""图书数据序列化器"""
class Meta:
model = BookInfo
fields = ('id', 'btitle', 'bpub_date', 'bread', 'bcomment')
extra_kwargs = {
'bread': {'min_value': 0, 'required': True},
'bcomment': {'min_value': 0, 'required': True},
}
2.3 ListSerializer序列化
class BookListSerializers(serializers.ListSerializer):
"""
# 1. create方法父级ListSerializer已经提供了
def create(self, validated_data):
通过self.child来访问绑定的ModelSerializer
return [
self.child.create(attrs) for attrs in validated_data
]
"""
# 2、父级ListSerializer没有通过update方法的实现体,需要自己重写
def update(self, instance, validated_data):
# ModelSerializer中的update方法
return [
# 单个对象 当前要修改的数据
self.child.update(instance[i], attrs) for i, attrs in enumerate(validated_data)
]
2.4 数据,多表联查
class BookListSerializers(serializers.ListSerializer):
"""
# 1. create方法父级ListSerializer已经提供了
def create(self, validated_data):
通过self.child来访问绑定的ModelSerializer
return [
self.child.create(attrs) for attrs in validated_data
]
"""
# 2、父级ListSerializer没有通过update方法的实现体,需要自己重写
def update(self, instance, validated_data):
# ModelSerializer中的update方法
return [
# 单个对象 当前要修改的数据
self.child.update(instance[i], attrs) for i, attrs in enumerate(validated_data)
]
class PublishModelSerializer(serializers.ModelSerializer):
class Meta:
models = models.Publish
fields = ["name", "addr"]
class BookSerializers(serializers.ModelSerializer):
class Meta:
# 群修改
list_serializer_class = BookListSerializers
model = models.Book
# 1.多表连查
# fields = ("name", "price", "publish_name", "author_list", 'publish', 'author')
# 子序列化都是提供给外键(正向方向)完成深度查询的,外键数据是唯一:many=False;不唯一:many=True
# 注:只能参与序列化,且反序列化不能写(反序列化外键字段会抛异常)
# # 前提:如果只有查需求的接口,自定义深度还可以用子序列化方式完成
publish = PublishModelSerializer(many=True)
fields = ("name", "price", "publish")
extra_kwargs = {
"publish": {
"write_only": True # 制作反序列化,不做序列化
},
"author": {
"write_only": True
}
}
三、单查和群查接口
urlpatterns = [
# url(r'^admin/', admin.site.urls),
url(r'^books/$', views.BookAPIView.as_view()),
url(r'^books/(?P<pk>\d+)/', views.BookAPIView.as_view()),
]
class BookSerializers(serializers.ModelSerializer):
class Meta:
model = models.Book
# 1.多表连查
fields = ("name", "price", "publish_name" ,"author_list")
# 2.__all__ 获取所有字段
# fields = "__all__"
# 3. __exclude__ 除了这个字段
# exclude = ('id', )
# 4. depth 深度查询, 与__all__一起连用
# depth = 2
class BookAPIView(APIView):
"""
单查:前台数据为pk,接口为 /books/(pk)/
群查:前台数据为pks,接口为 /books/
"""
# 单查和群查
def get(self, request, *args, **kwargs):
pk = kwargs.get("pk")
if pk:
# 单查
book_obj = models.Book.objects.filter(pk=pk, is_delete=False).first()
# 判断
if not book_obj:
return APIResponse(status=1, msg='get error', http_status=400)
# 返回数据
book_data = BookSerializers(book_obj, is_delete=False).data
return APIResponse(results=book_data)
else:
# 群查
book_obj = models.Book.objects.all()
book_list_data = BookSerializers(book_obj, many=True).data
return APIResponse(0, "ok", results=book_list_data)
总结:
- 单查从请求中获取get单条数据
- 过滤False数据库中的记录
- 群查序列化,many设置True
- 单查群查接口,序列化类提供序列化对象,many参数控制着操作的数据是一条还是多条
四、单删和群删接口
class BookSerializers(serializers.ModelSerializer):
class Meta:
model = models.Book
# 1.多表连查
fields = ("name", "price", "publish_name" ,"author_list")
def delete(self, request, *args, **kwargs):
""""
单删:前台数据为pk,接口为 /books/(pk)/
群删:前台数据为pks(json),接口为 /books/
"""
pk = kwargs.get("pk")
# 将单删群删逻辑整合
if pk: # /books/(pk)/的接口就不考虑群删,就固定为单删 请求要带斜杠
pks = [pk] # 获取单删
else:
# 获取群删
pks = request.data.get("pk")
# 判断前台是否是否pk
if not pks:
# 前台数据有误,没有提供pk
return APIResponse(1, "delete error", http_status=400)
# 返回操作的行,受影响行,就是删除成功,反之失败
rows = models.Book.objects.filter(is_delete=False, pk__in=pks).update(is_delete=True)
# 判断是否删除成功
if rows:
return APIResponse(0, "delete ok")
else:
return APIResponse(0, "delete error")
总结:
-
delete请求的时候url要添加斜杠,2的后面
-
将单删和群删进行逻辑整合
-
单删群删接口,后台操作删除字段即可,前台7提供pk就是单删,提供pks就是群删
五、单增和群增接口
class BookSerializers(serializers.ModelSerializer):
class Meta:
model = models.Book
# 1.多表连查
fields = ("name", "price", "publish_name", "author_list", 'publish', 'author')
extra_kwargs = {
"publish": {
"write_only": True # 制作反序列化,不做序列化
},
"author": {
"write_only": True
}
}
class BookAPIView(APIView):
def post(self, request, *args, **kwargs):
"""
save源码
if self.instance is not None:
self.instance = self.update(self.instance, validated_data)
assert self.instance is not None, (
'`update()` did not return an object instance.'
)
else:
self.instance = self.create(validated_data)
assert self.instance is not None, (
'`create()` did not return an object instance.'
)
"""
request_data = request.data
print(request_data)
# 单填
if isinstance(request_data, dict):
# 校验单条数据
book_result = BookSerializers(data=request_data)
# 获取校验结果
if book_result.is_valid(raise_exception=True):
book_obj = book_result.save()
# 返回序列化对象
return APIResponse(0, "post ok", results=BookSerializers(book_obj).data)
# 群填
elif isinstance(request_data, list) and request_data:
# 校验多条数据
book_result = BookSerializers(data=request_data, many=True)
if book_result.is_valid(raise_exception=True):
# 返回保存对象列表
book_list_obj = book_result.save()
# 返回序列化结果
result = BookSerializers(book_list_obj, many=True)
return APIResponse(0, 'data ok ', results=result)
else:
# 其他错误
return APIResponse(1, "data error", http_status=400)
总结:
- 单条数据为字典,判断是否为字典 ,对数据进行校验,校验结果由is_valid进行处理,保存对象,返回序列化对象
- 多条数据,判断是否为列表,列表是否为空,对象进行校验,设置mandy为True校验多条数据,校验结果又is_valid进行处理,保存对象,返回序列化对象结果多条mandy为True
- 单增群增接口,根据数据判断是单增还是群增,对应序列化类要设置many,而序列化类只需要通过data即可
六、单条数据整改和多条数据整改
# 序列化.py
class BookListSerializers(serializers.ListSerializer):
"""
# 1. create方法父级ListSerializer已经提供了
def create(self, validated_data):
通过self.child来访问绑定的ModelSerializer
return [
self.child.create(attrs) for attrs in validated_data
]
"""
# 2、父级ListSerializer没有通过update方法的实现体,需要自己重写
def update(self, instance, validated_data):
# ModelSerializer中的update方法
return [
# 单个对象 当前要修改的数据
self.child.update(instance[i], attrs) for i, attrs in enumerate(validated_data)
]
class BookSerializers(serializers.ModelSerializer):
class Meta:
list_serializer_class = BookListSerializers
model = models.Book
# 1.多表连查
fields = ("name", "price", "publish_name", "author_list", 'publish', 'author')
extra_kwargs = {
"publish": {
"write_only": True # 制作反序列化,不做序列化
},
"author": {
"write_only": True
}
}
class BookAPIView(APIView):
# 单整体改,群整体改
def put(self, request, *args, **kwargs):
"""
save源码
if self.instance is not None:
self.instance = self.update(self.instance, validated_data)
assert self.instance is not None, (
'`update()` did not return an object instance.'
)
else:
self.instance = self.create(validated_data)
assert self.instance is not None, (
'`create()` did not return an object instance.'
)
单整体改: 前台提交字典,根据pk一个数据,接口/books/(pk)/
群整体改: 前台提交列表套字典, 接口 /books/ 注每一个字典都可以通过pk添加
"""
# 单改,将获取的json数据,通过获取pk对应数据库对象记录,进行修改数据
pk = kwargs.get("pk")
request_data = request.data
print(request_data)
if pk:
try:
book_obj = models.Book.objects.get(pk=pk)
except:
return APIResponse(1, "pk error")
# 修改和新增,都需要通过数据,数据依旧给data,修改和新增不同点,需要将被修改对象给instance
book_ser = BookSerializers(initial=book_obj, data=request_data)
book_ser.is_valid(raise_exception=True)
# 在保存数据之前必须调用 is_valid,在保存数据之前不可以调用book_ser不可以调用data属性,以为会提前产生_data
book_new_obj = book_ser.save()
return APIResponse(results=BookSerializers(book_new_obj).data)
else: # 群改
if not isinstance(request_data, list) or len(request_data) == 0:
return APIResponse(1, "data error", http_status=400)
# [{pk:1,...}, {pk:3,...}, {pk:100,...}] => [obj1, obj3, obj100] + [{...}, {...}, {...}]
# 要考虑pk对应的对象是否被删,以及pk没有对应的对象
# 假设pk3被删,pk100没有 => [obj1] + [{...}]
# 注: 一定不要在循坏体重对循坏对象进行增删(影响对象的长度的操作
obj_list = []
data_list = []
for dic in request_data:
try:
pk = dic.pop("pk")
try:
obj = models.Book.objects.get(pk=pk, is_delete=False)
# 获取对象是否存在
obj_list.append(obj)
# 添加数据
data_list.append(dic)
except:
pass
except:
return APIResponse(1, "data error", http_status=400)
# 修改的对象列表 对应的修改的数据 多条
book_ser = BookSerializers(instance=obj_list,data=data_list, many=True)
# 校验数据
book_ser.is_valid(raise_exception=True)
book_list_obj = book_ser.save()
# 返回序列化修改的数据
return APIResponse(results=BookSerializers(book_list_obj, many=True).data)
总结:
- 单整体改和群整体改每个字段必须填,
- 没有提供整体改的方法需要自定义类继承ListSerializer类重写update方法,需要在子类进行绑定list_serializer_class = BookListSerializers
- 单整体改传参BookSerializers(initial=book_obj, data=request_data)
- 群整体改BookSerializers(instance=obj_list,data=data_list, many=True)
- 群改,前台提供的数据,后台要转化成要修改的对象们和用来更新的数据们,ModelSerializer设置list_serializer_class关联自己的ListSerializer,重写update方法,完成群改
七、单局部改和群局部改
# 序列化.py
class BookListSerializers(serializers.ListSerializer):
"""
# 1. create方法父级ListSerializer已经提供了
def create(self, validated_data):
通过self.child来访问绑定的ModelSerializer
return [
self.child.create(attrs) for attrs in validated_data
]
"""
# 2、父级ListSerializer没有通过update方法的实现体,需要自己重写
def update(self, instance, validated_data):
# ModelSerializer中的update方法
return [
# 单个对象 当前要修改的数据
self.child.update(instance[i], attrs) for i, attrs in enumerate(validated_data)
]
class BookSerializers(serializers.ModelSerializer):
class Meta:
list_serializer_class = BookListSerializers
model = models.Book
# 1.多表连查
fields = ("name", "price", "publish_name", "author_list", 'publish', 'author')
extra_kwargs = {
"publish": {
"write_only": True # 制作反序列化,不做序列化
},
"author": {
"write_only": True
}
}
class BookAPIView(APIView):
# 单局部改、群局部改
def patch(self, request, *args, **kwargs):
"""
save源码
if self.instance is not None:
self.instance = self.update(self.instance, validated_data)
assert self.instance is not None, (
'`update()` did not return an object instance.'
)
else:
self.instance = self.create(validated_data)
assert self.instance is not None, (
'`create()` did not return an object instance.'
)
单局部改: 前台提交字典,根据pk一个数据,接口/books/(pk)/
群局部改: 前台提交列表套字典, 接口 /books/ 注每一个字典都可以通过pk添加
"""
# 单改,将获取的json数据,通过获取pk对应数据库对象记录,进行修改数据
pk = kwargs.get("pk")
request_data = request.data
print(request_data)
print(pk)
if pk:
try:
book_obj = models.Book.objects.get(pk=pk)
except:
return APIResponse(1, 'pk error')
# 局部修改就是在整体修改基础上设置partial=True,将所有参与反序列化字段设置为required=False
book_ser = BookSerializers(instance=book_obj, data=request_data, partial=True)
book_ser.is_valid(raise_exception=True)
book_obj = book_ser.save()
return APIResponse(results=BookSerializers(book_obj).data)
else: # 群改
if not isinstance(request_data, list) or len(request_data) == 0:
return APIResponse(1, "data error", http_status=400)
# [{pk:1,...}, {pk:3,...}, {pk:100,...}] => [obj1, obj3, obj100] + [{...}, {...}, {...}]
# 要考虑pk对应的对象是否被删,以及pk没有对应的对象
# 假设pk3被删,pk100没有 => [obj1] + [{...}]
# 注: 一定不要在循坏体重对循坏对象进行增删(影响对象的长度的操作
obj_list = []
data_list = []
for dic in request_data:
try:
pk = dic.pop("pk")
try:
obj = models.Book.objects.get(pk=pk, is_delete=False)
# 获取对象是否存在
obj_list.append(obj)
# 添加数据
data_list.append(dic)
except:
pass
except:
return APIResponse(1, "data error", http_status=400)
# 修改的对象列表 对应的修改的数据 多条
book_ser = BookSerializers(instance=obj_list, data=data_list, many=True, partial=True)
# 校验数据
book_ser.is_valid(raise_exception=True)
book_list_obj = book_ser.save()
# 返回序列化修改的数据
return APIResponse(results=BookSerializers(book_list_obj, many=True).data)
总结:
- 单局部改和群局部改每个字段必须填,
- 没有提供整体改的方法需要自定义类继承ListSerializer类重写update方法,需要在子类进行绑定list_serializer_class = BookListSerializers
- 单局部改传参BookSerializers(initial=book_obj, data=request_data,partial=True)
- 单局部改BookSerializers(instance=obj_list,data=data_list, many=True,partial=True)
- 单局部改,序列化类参数instance=修改的对象, data=修改的数据, partial=是否能局部修改,单整体修改就是partial=False(默认就是False)
八、子序列化
class PublishModelSerializer(serializers.ModelSerializer):
class Meta:
models = models.Publish
fields = ["name", "addr"]
class BookSerializers(serializers.ModelSerializer):
class Meta:
list_serializer_class = BookListSerializers
model = models.Book
# 1.多表连查
# fields = ("name", "price", "publish_name", "author_list", 'publish', 'author')
# 子序列化都是提供给外键(正向方向)完成深度查询的,外键数据是唯一:many=False;不唯一:many=True
# 注:只能参与序列化,且反序列化不能写(反序列化外键字段会抛异常)
# # 前提:如果只有查需求的接口,自定义深度还可以用子序列化方式完成
publish = PublishModelSerializer(many=True)
fields = ("name", "price", "publish")
class BookAPIView(APIView):
"""
单查:前台数据为pk,接口为 /books/(pk)/
群查:前台数据为pks,接口为 /books/
过滤删除的字段
"""
# # 单查和群查
def get(self, request, *args, **kwargs):
pk = kwargs.get("pk")
if pk:
# 单查
book_obj = models.Book.objects.filter(pk=pk, is_delete=False).first()
# 判断
if not book_obj:
return APIResponse(status=1, msg='get error', http_status=400)
# 返回数据
book_data = BookSerializers(book_obj).data
return APIResponse(results=book_data)
else:
# 群查
book_obj = models.Book.objects.filter(is_delete=False).all()
book_list_data = BookSerializers(book_obj, many=True).data
return APIResponse(0, "ok", results=book_list_data)
总结:
- 子序列化都是提供给外键(正向方向)完成深度查询的,外键数据是唯一:many=False;不唯一:many=True
- 只能参与序列化,且反序列化不能写(反序列化外键字段会抛异常)
- 如果只有查需求的接口,自定义深度还可以用子序列化方式完成
总结
- get: 单查,群查
- post: 单增,群增
- delete: 单删,群山(都是自己实现)
- put:单整体改,群整体改
- patch: 单局部改,群局部改
在当下的阶段,必将由程序员来主导,甚至比以往更甚。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号