Python之爬虫-酷6视频
Python之爬虫-酷6视频
import re
import requests
"""
@author RansySun
@create 2019-07-20-19:00
"""
# 网站地址
response = requests.get('https://www.ku6.com/index')
data = response.text
"""
<div class="video-image-container">
<a class="video-image-warp" target="_blank" href="/video/detail?id=R24vWnh_XhAVchmEcqxVaElqM_o.">
<img src="https://rbv01.ku6.com/wifi/o_1dg1e86u616g42te1lhj13ncvptc"></a>
</div>
"""
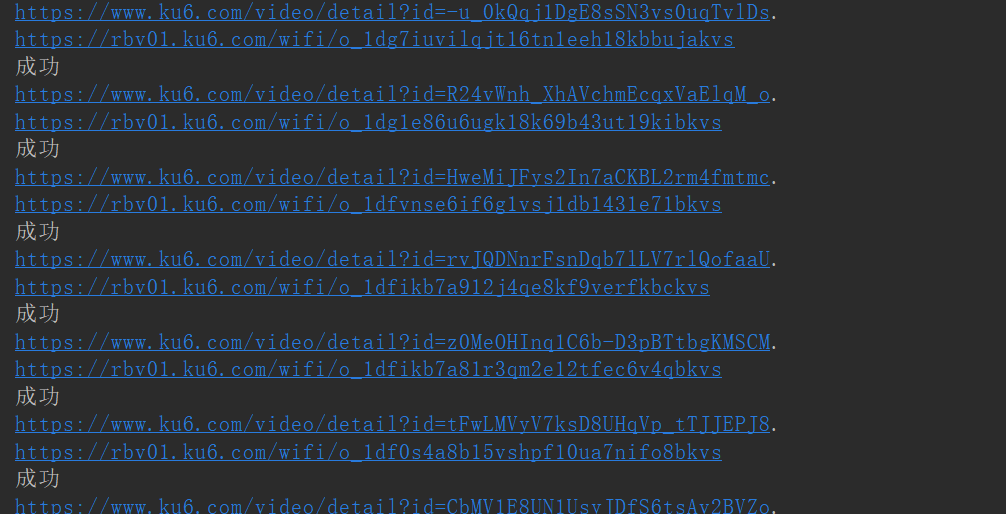
# 查找视频链接
result_list = re.findall('<a class="video-image-warp" target="_blank" href="(.*?)">', data)
count = 0
for result in result_list:
# result = result.split(" ")[-1].split('"')[-2] # 单个视频爬
# print(result)
if result.startswith('/video'):
result = f"https://www.ku6.com{result}"
print(result)
# 请求视频链接
result_data = requests.get(result)
video_data = result_data.text
# flvURL: "https://rbv01.ku6.com/wifi/o_1dg1e86u6ugk18k69b43ut19kibkvs"
# 查找视频播放链接
video_url = re.findall('flvURL: "(.*?)"', video_data)
for result_url in video_url:
# print(result_url)
# videl_res_url = result_url.split('"')[1] 单个视频
# print(videl_res_url)
# 请求视频播放链接
video_response = requests.get(result_url)
# 获取视频编码
video_data = video_response.content
# # print(video_data)
# 保存视频
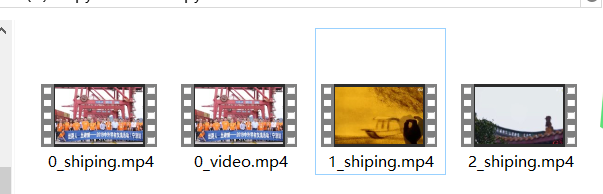
with open(f"{count}_video.mp4", "wb") as fw:
fw.write(video_data)
fw.flush()
count += 1
print("成功")
结果:
在当下的阶段,必将由程序员来主导,甚至比以往更甚。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号