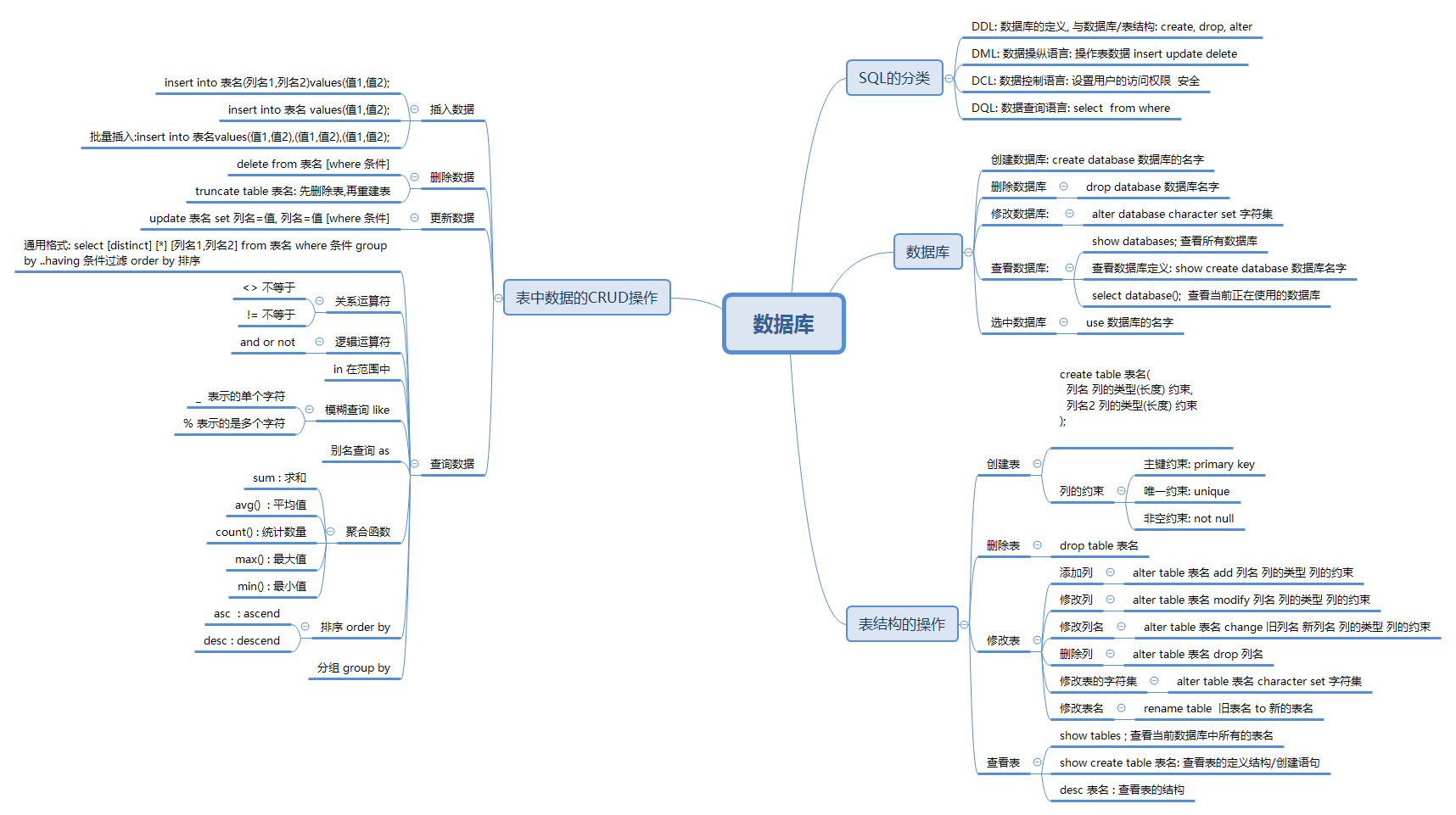
Mysql入门详解
数据库之Mysql
本篇文章为观看某教学视频后所作个人总结
一 、简单了解数据库
1.1常见关系型数据库
-
mysql:开源免费,中小型企业;sun公司被oracle收购后开始收费。
-
mariadb:由mysql创始人创建,由mysql延伸出来的分支,命令基本通用。
-
Oracle:商业收费,适用于大型电商网站。
-
db2:IBM公司,大多用于银行系统。
-
sqlserver:Windows专用,政府网站多采用此数据库,教学使用。
用于描述实体与实体之间的的关系
1.2非关系型数据库
Nosql 、mongodb、redis
键值对(key-value)
1.3 mysql语句的构成
- SQL:结构化查询语言
- DDL:数据定义语言,定义数据库、数据表的结构:create(创建)、drop(删除)、alter(修改)
- DML:数据操纵语言,用来操作数据,包括insert(插入)、update(修改)、delete(删除)
- DCL:数据控制语言,定义或取消访问权限,安全设置(grant)
- DQL:数据查询语言,select(查询) from子句 where子句等
二、Mysql的使用
2.1mysql数据库的创建、修改,查询
-
登录数据库服务器
mysql -uroot -p1234(我的密码是1234)通用格式为mysql -u[用户名] -p[用户的密码]
退出数据库使用exit
-
创建一个数据库
create database mybase character set utf8 collate utf8_bin/utf_general_ci;通用规则 :create database 数据库名 [设置字符集] [校验规则]
为了避免中文乱码问题建议在创建表的时候直接指定编码为utf8(国际通用编码)
如果还有中文乱码,则可能是dos下的编码问题chcp查看编码
chcp 935 表示gbk; chcp 65001表示utf8
-
查看所有创建的数据库
show databases;注意:1.不要漏掉databases后面的s。
2.三个数据库的原表不要动:information_schema;
performance_schema;mysql
-
查看数据库的定义
show create database 数据库名;mysql> show create database day02; +----------+------------------------------------------------------------------+ | Database | Create Database | +----------+------------------------------------------------------------------+ | day02 | CREATE DATABASE `day02` /*!40100 DEFAULT CHARACTER SET latin1 */ | +----------+------------------------------------------------------------------+ 1 row in set (0.00 sec) -
查看当前正在使用的数据库
mysql> select database(); +------------+ | database() | +------------+ | day02 | +------------+ 1 row in set (0.00 sec) -
选中数据库
use 数据库名; mysql> use day02; Database changed -
修改数据库
#修改数据库的字符集 alter database 数据库名 character set 字符集; -
删除数据库
drop database 数据库名; drop database test;
2.2数据库表的创建、修改,查询
2.2.1 数据类型
char varchar double float boolean
date: YYYY-MM-DD
time: hh:mm:ss
datetime: YYYY-MM-DD hh:mm:ss 默认值为none
timesstrap: YYYY-MM-DD hh:mm:ss 默认值是当前时间
text: 存放文本 blob: 存放二进制
对于单个字符,char的长度固定,varchar长度可变
2.2.2列的约束
主键约束:primary key
唯一约束:unique
非空约束:not null
2.2.3创建表
#切换到指定的数据库
use 数据库名;
#开始创建表
create table 表名(
列名 类型[长度] 约束,
列名2 类型[长度] 约束
)
#具体例子:
mysql> use day02;
Database changed
mysql> create table student(
-> sid int primary key,
-> sname varchar(31),
-> sex int,
-> age int
-> );
Query OK, 0 rows affected (0.10 sec)
2.2.4删除表
use 数据库名;
drop table 表名;
2.2.4查看表
#确保已经切换到指定的数据库
#查看表的结构
mysql> desc student;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| sid | int(11) | NO | PRI | NULL |
| sname | varchar(31) | YES | | NULL |
| sex | int(11) | YES | | NULL |
| age | int(11) | YES | | NULL |
+-------+-------------+------+-----+---------+-------+
4 rows in set (0.03 sec)
#查看表的定义
show create table 表的名字;
show create table stuinfo;
2.2.5修改已经创建的表
包括的操作有:添加列(add)、删除列(drop)、修改列(modify)、修改列名(change)、修改表名(rename)、修改表的字符集
#添加列(add)
alter table 表名 add 列名 列的类型 列的约束
alter table student add hobby varchar(10);
#删除列(drop)
alter table student drop hobby ;
#修改列(modify)
alter table student modify sex varchar(2);
#修改列名(change)
alter table student change age year int(5);
#修改表名(rename)
rename table student to employeer;
#修改表的字符集
alter table employeer character set gbk;
开发时一般不会修改表名,影响较大。
2.3数据库表的CRUD(增删改查)
2.3.1插入数据
-- 单条插入
#标准格式
insert into 表名(key1,key2,key3...) values(value1,value2,value3...);
#举个栗子
insert into student(sid,sname,sex,age) values(1,'lusi',1,22);
#当插入的数据为全列时,可以省略"key"值,如下:
insert into student values(1,'lusi',1,22);
#若插入的数据不是全列,则需要写全"key"值,如下:
insert insto student (sid,sname) values(2,'ziyu');
-- 批量插入
#以逗号作为分隔符
insert into student values(3,'xm',1,21),(4,'xh',2,18),(5,'xg',1,23);
2.3.2删除数据
delete from 表名 [where条件];
#举个栗子
delete from student where sid=1;
#未指明条件,则删除全部数据记录
delete from student;
-- 比较delete与truncate的效率
delete:DML 一条一条删除表中的数据
truncate:DDL 先删除表再重建表
倘若表中数据较多,truncate效率更高,否则delete效率高
2.3.3更新数据
update 表名 set 列名1=value1,列名2=value2...;
update student set sname=yamgmi,age=30 where sid=4;
#倘若未指明where条件,则更新到所有数据项
2.2.4数据查询
语法格式:select [distinct] [ * ] [列名1,列名2.....] from 表名 [where 条件]
-- 为了方便实验,我们单独创建两张表
create database goods character set utf8;
use goods;
#商品的分类:商品分类的ID、商品分类的名称、商品分类的描述
create table category(
cid int primary key auto_increment,
cname varchar(10),
cdesc varchar(31)
);
#所有的商品:商品ID、商品名称,价格,生产日期,分类ID
create table product (
pid int primary key auto_increment, #自增长
pname varchar(10),
price double,
pdate timestamp,
cno int
);
#插入数据
insert into category values(null,'休闲食品','瓜子,辣条'),
(null,'饮料','营养快线,安慕希'),
(null,'箱包','召唤师峡谷制造'),
(null,'烟酒','茅台,红南京,拉菲');
insert into product values(null,'瓜子',12,null,1),(null,'卫龙辣条',4,null,1),
(null,'哇哈哈',8,null,2),(null,'安慕希',68,null,2),
(null,'莫斯利安',58,null,2),(null,'京东大包',165,null,3),
(null,'阿迪王行李箱',256,null,3),(null,'茅台',1000,null,4),
(null,'小苏',100,null,4);
开始查询
1.简单查询
select * from product
别名 as、select运算查询(对结果运算,不改变数据库中的值)
select pname as "商品名称",price as "商品价格",price*0.8 as "折后价" from product;
as是mysql为列起别称的关键字,使用时可以省略
2.条件查询[where 关键字]
where后面的条件:> >= < <= = != <>
<>:不等于,标准sql !=:不等于,非标准sql
判断某一列是否为空:is null, is not null
逻辑运算and or not between..and..
select * from product where price between 10 and 100 and cno <> 4;
between..and..在使用时,前面的数必须要小于后面的数
3.模糊查询
_ 代表单个字符
% 代表多个字符
select * from product where pname like "_斯%";
in 设定范围
select * from product where price in (12,8,165);
4.排序查询:order by 关键字
asc: ascend 升序(默认)
desc: descend 降序
select * from product where cno=2 order by price asc;
5.聚合函数
-
常见聚合函数
函数名 描述 sum() 求和 avg 求平均值 count() 统计数量 min() 最小值 max 最大值 -
使用实例
-
获得所有商品价格总和
select sum(price) from product; -
获得所有商品平均价格
select avg(price) from product; -
获取商品个数
select count(*) from product;
-
where 条件后面不可以接聚合函数
6.子查询(嵌套查询)
查询商品价格大于平均价格的商品
select * from product where price > (select avg(price) from product);
子查询中的嵌套子句后面不需要分号
7.分组查询:group by
-
根据cno分组,统计分组后商品的个数
select cno,count(*) from product group by cno; -
根据cno分组,统计分组后商品的平均价格,并且平均价格大于100
select cno,avg(price) from product group by cno having avg(price)>100;
#总结一下
聚合函数常与分组搭配使用
where条件过滤的是分组之前,不可接聚合函数
having 条件过滤的是分组之后,可以接聚合函数
#编写顺序
select .. from where .. group by .. having .. order by ..
#执行顺序
from .. where .. group by .. having .. select .. order by ..
三、多表查询
这一部分很重要,所以单独分出来,尽量细节化。
3.1 简单了解与分析
多表查询中,多张表靠什么来维持多表之间的关系? 外键约束。
引入科学百科对外键的定义:如果公共关键字在一个关系中是主关键字,那么这个公共关键字被称为另一个关系的外键。由此可见,外键表示了两个关系之间的相关联系。以另一个关系的外键作主关键字的表被称为主表,具有此外键的表被称为主表的从表。外键又称作外关键字。
分析:以上面的商品数据库(goods)为例,商品分类(category)的中的主键(cid)与所有商品表(product)的非主键(cno)之间可以建立联系,因为他们都表示商品分类的ID编号。故可以为从表product添加外键,如下:
alter table product add foreign key(cno) references category(cid);
注意:1.在添加外键之前须确保,从表中外键的值必须在主表中存在,否则无法建立外键。上面category表中我们的cid有1、2、3、4四个值(自增长),如果我们事先执行如下操作insert into product values(null,"洋娃娃",20,null,5);则会因为主表中没有cid=5这个值而无法添加外键。2. 在添加外键之后,如果想要删除某个分类,需要先删除对应分类号的所有商品。(即若要删除主表中某行的值,必须先删除从表中对应外键值的所有条目)
3.2 建表的种类
-
一对多 : 商品和分类
- 建表原则: 在多的一方添加一个外键,指向一少的一方的主键
-
多对多: 老师和学生, 学生和课程
建表原则: 建立一张中间表,将多对多的关系,拆分成一对多的关系,中间表至少要有两个外键,分别指向原来的那两张表
-
一对一: 班级和班长, 公民和身份证, 国家和国旗
-
建表原则:
- 将一对一的情况,当作是一对多情况处理,在任意一张表添加一个外键,并且这个外键要唯一,指向另外一张表
- 直接将两张表合并成一张表
- 将两张表的主键建立起连接,让两张表里面主键相等
-
实际用途: 用的不是很多. (拆表操作 )
- 相亲网站:
- 个人信息 : 姓名,性别,年龄,身高,体重,三围,兴趣爱好,(年收入, 特长,学历, 职业, 择偶目标,要求)
- 拆表操作 : 将个人的常用信息和不常用信息,减少表的臃肿。
- 相亲网站:
-
建表约束问题:
主键约束: 默认就是不能为空, 唯一
- 外键都是指向另外一张表的主键
- 主键一张表只能有一个
唯一约束: 列面的内容, 必须是唯一, 不能出现重复情况, 为空
- 唯一约束不可以作为其它表的外键
- 可以有多个唯一约束
3.3 商品表进阶设计(多表)【本实例引自黑马教程】
假设以上面的商品数据库为基础,设计一个简单的网上商城数据库,应该怎么做?或者说我们还缺哪些数据库,数据库之间的关系又如何约束。
分析:首先作为一个商城,我们得有用户表(user)吧,然后每个用户还得有自己的购物清单(orders)。一个用户可以有多个购物清单,而同一个购物清单只能属于同一个用户(毕竟购物清单的id编号是固定的),所以用户与清单的关系是一对多(1:n);同一个分类可以有多个商品,同一个商品只属于一个分类(别钻牛角尖,说猪既是肉类又是宠物类,开个玩笑),所以商品与商品分类的关系是一对多;一个清单中可以包含多件商品,而同一件商品也可以存在于不同的购物清单中,所以是多对多关系,多对多这种互相包含的关系会使得数据库很难管理,因此引入一张中间表(orderitem),专门负责管理他们之间的关系,具体如下:
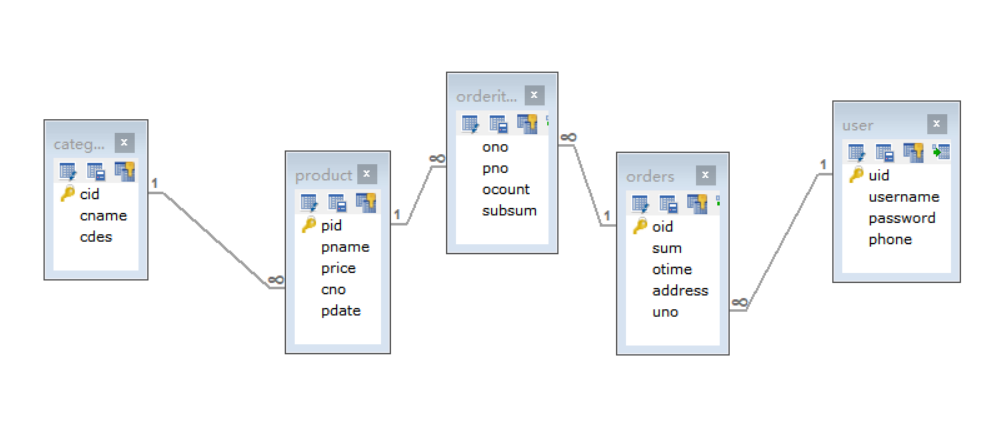
给出相关表的创建
-
用户表 (用户的ID,用户名,密码,手机)
create table user( uid int primary key auto_increment, username varchar(31), password varchar(31), phone varchar(11) ); insert into user values(1,'lisi','123','18811118888'); -
订单表 (订单编号,总价,订单时间 ,地址,外键用户的ID)
create table orders( oid int primary key auto_increment, sum int not null, otime timestamp, address varchar(100), uno int, foreign key(uno) references user(uid) ); insert into orders values(1,200,null,'江宁大学城旁边小黑屋',1); insert into orders values(2,250,null,'江宁大学城旁边最豪华房子',1); -
订单项: 中间表(订单ID,商品ID,商品数量,订单项总价)
create table orderitem( ono int, pno int, foreign key(ono) references orders(oid), foreign key(pno) references product(pid), ocount int, subsum double ); --给1号订单添加商品 200块钱的商品 insert into orderitem values(1,7,100,100); insert into orderitem values(1,8,101,100); --给2号订单添加商品 250块钱的商品 () insert into orderitem values(2,5,1,35); insert into orderitem values(2,3,3,99);
分类表(category)与商品表(product)延用之前的,不再列出。
3.4 商品表查询实例(多表)
- 交叉连接查询 笛卡尔积
SELECT * FROM product;
SELECT * FROM category;
笛卡尔积 ,查出来是两张表的乘积 ,查出来的结果没有意义
SELECT * FROM product,category;
--过滤出有意义的数据
SELECT * FROM product,category WHERE cno=cid;
SELECT * FROM product AS p,category AS c WHERE p.cno=c.cid;
SELECT * FROM product p,category c WHERE p.cno=c.cid;
--数据准备
INSERT INTO product VALUES(NULL,'耐克帝',10,NULL);
-
内连接查询
-- 隐式内链接
SELECT * FROM product p,category c WHERE p.cno=c.cid;
-- 显示内链接
SELECT * FROM product p INNER JOIN category c ON p.cno=c.cid;
-- 区别:
隐式内链接: 在查询出结果的基础上去做的WHERE条件过滤
显示内链接: 带着条件去查询结果, 执行效率要高 -
左外连接
左外连接,会将左表中的所有数据都查询出来, 如果右表中没有对应的数据,用NULL代替
SELECT * FROM product p LEFT OUTER JOIN category c ON p.cno=c.cid; -
准备工作
INSERT INTO category VALUES(100,'电脑办公','电脑叉叉差'); -
右外连接: 会将右表所有数据都查询出来, 如果左表没有对应数据的话, 用NULL代替
SELECT * FROM product p RIGHT OUTER JOIN category c ON p.cno=c.cid;
-- 查询分类名称为手机数码的所有商品
1.查询分类名为手机数码的ID
SELECT cid FROM category WHERE cname='手机数码';
2.得出ID为1的结果
SELECT * FROM product WHERE cno = (SELECT cid FROM category WHERE cname='手机数码');
-- 查询出(商品名称,商品分类名称)信息
--左连接
SELECT p.pname,c.cname FROM product p LEFT OUTER JOIN category c ON p.cno = c.cid;
--子查询
SELECT pname ,(SELECT cname FROM category c WHERE p.cno=c.cid ) AS 商品分类名称 FROM product p;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号