
背景铺垫
假设我们正在设计一个翻译程序,讲英语翻译成法语,需要用一棵BST存储文章中出现的单词及等价的法语。因为要频繁地查找这棵树,所以我们希望查找时间越短越好。当然我们可以考虑使用红黑树,或者可能更适用的伸展树,来实现这一操作。但是这仍然不能满足我们的需要:由于单词出现频率不同,如果mycophagist这种奇怪的单词出现在根节点,而the、a、is这些常用单词出现在叶节点,即使O(lgn)的查找速度也极大的浪费了时间。
因此我们需要这样一种BST:频繁出现的单词出现在离根节点较近的地方。假设我们知道每个单词的出现频率,应该如何组织BST使得总搜索访问的节点数目最小呢?
最优二叉查找树 Optimal Binary Search Tree
定义:对于给定的一组概率,构造一棵搜索期望代价最小的BST,称为最优二叉查找树。
介绍:形式地,给定一个由n个互异关键字组成的序列 K = <k1, k2, ..., kn>,且关键字有序,即 k1 < k2 < ... <kn。利用这些关键字构造一棵BST,对于每个关键字ki搜索的概率是pi。某些搜索的值可能不在K内,因此还有n+1个“虚拟键” <d0, d1, d2, ..., dn> 代表不在K内的值。具体地,d0代表所有小于k1的值,dn代表所有大于kn的值。对于 i = 1, 2, ..., n-1,虚拟键di代表所有位于ki和ki+1之间的值。对于每个虚拟键di搜索的概率是qi。每个关键字ki是一个内部结点,而di是叶节点。每次搜索或者成功(找到内部结点ki),或者失败(找到叶节点di)。因此有:
$\sum_{i=1}^{n}p_{i}+\sum_{i=0}^{n}q_{i}=1$
假设一次搜索的实际代价为检查的节点个数,亦即,在T内搜索所发现的节点的深度加上1。所以在T内一次搜索的期望代价为:
$\begin{align*} E[T]&=\sum_{i=1}^{n}(depth_{T}(k_{i})+1)\cdot{} p_{i}+\sum_{i=0}^{n}(depth_{T}(d_{i})+1)\cdot{} q_{i}\\ &=\sum_{i=1}^{n}depth_{T}(k_{i})\cdot{} p_{i}+\sum_{i=0}^{n}depth_{T}(d_{i})\cdot{} q_{i}+1 \end{align*}$
举个栗子:
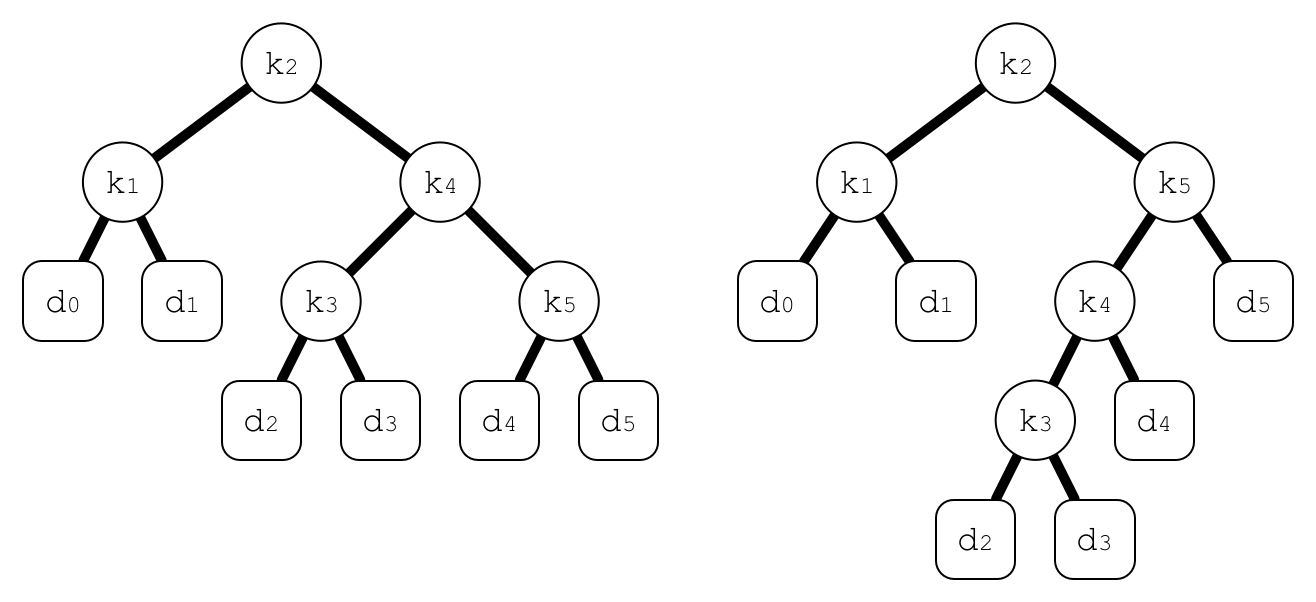
如图,根据相同关键字构造的BST,检索概率如下表
| i | 0 | 1 | 2 | 3 | 4 | 5 |
| pi | 0.15 | 0.10 | 0.05 | 0.10 | 0.20 | |
| qi | 0.05 | 0.10 | 0.05 | 0.05 | 0.05 | 0.10 |
因此容易得出左树搜索代价为2.80,右树搜索代价为2.75,因此这棵树是最优的。
这个例子说明:一棵最优BST不一定是一棵整体高度最小的树,也不一定总是把有最大概率的关键字放在根部。
步骤1:一棵最优二叉树的结构
首先找最优子结构:如果一棵最优二叉查找树T有一棵子树T',包含关键字<ki, ..., kj>和<di-1, ..., dj>,那么树T'的子树T''也必定是一棵最优二叉查找树。这样,我们可以根据最优子结构来构造一棵最优二叉查找树。
给定关键字<ki, ..., kj>,假设根节点为kr (i <= r <= j),则:
左子树包含关键字<ki, ..., kr-1>和<di-1, ..., dr-1>;
右子树包含关键字<kr+1, ..., kj>和<dr, ..., dj>。
只要我们检查所有候选根节点kr (i <= r <= j),并且确定左右子树的最优子树,就保证能得到一棵最优二叉查找树。
注意一点是空子树的处理。如果一棵子树包含关键字<ki, ..., ki-1>,则其不含有任何关键字,但是却含有虚拟键di-1。同样的,对于子树<kj+1, ..., kj>,不含有任何关键字,但含有虚拟键dj。
步骤2:一个递归解
选取子问题域为寻找包含关键字<ki, ..., kj>的最优二叉查找树,其中 i >= 1 且 i-1 <= j <= n(当 j = i-1 时只有虚拟键di-1)。定义e[i, j]为该问题的期望代价,显然,e[1, n]就是原问题的解。
当 j = i-1 时出现简单情况。因为只有一个虚拟键di-1,所以搜索期望代价是e[i, i-1] = qi-1。
当 j >= i 时需要遍历结点<ki, ..., ki-1>选择一个合适的根kr (i <= r <= j),然后分别构造左右子树。同时,当一棵树成为另一棵树的子树时,子树所有结点深度加1。
对一颗有关键字<ki, ..., kj>的子树,定义概率的总和为:
$w(i,j) = \sum_{j=i}^{j}pi+\sum_{j=i-1}^{j}ql$
因此,如果kr是一棵包含关键字<ki, ..., ki-1>的最优子树的根,则有
$e[i,j]=p_{r}+((e[i,r-1]+w(i,r-1))+(e[r+1,j])+w(r+1,j))$
注意
$w(i,j)=w(i,r-1)+p_{r}+w(r+1,j)$
将e[i,j]重写为
$e[i,j]=e[i,r-1]+e[r+1,j]+w(i,j)$
于是我们就能得出递归式。在这里假设我们已知结点kr,我们选择有最低期望搜索代价的结点作为根:
$e[i,j]=\begin{cases} q_{i-1}&j=i-1\\\textrm{min}_{i\leq r\leq j}{e[i,r-1]+e[r+1,j]+w(i,j)}&i\leq j\end{cases}$
我们还定义root[i,j]为根kr的下标r。
步骤3:计算一棵最优二叉查找树的期望搜索代价
其实我们能发现最优二叉查找树和矩阵链乘法之间有些相似,比如子问题都是由连续下标子范围组成。
正如我们之前所做的,为了储存子问题的结果,我们需要把e[i,j]保存在表e[1..n+1, 0..n]中,其中:
第一维下标需要达到n+1而不是n,原因是为了有一个只包含虚拟键dn的子树,我们需要计算和保存e[n+1,n];
第二纬下标需要从0开始,是为了保存e[1,0]。
使用 j >= i-1 的表项 e[i,j] 和表 root[i,j] 来记录包含关键字<ki, ..., kj>的子树的根,这个表只用 1 <= i <= j <= n的表项。
为了提高效率,还需要一个表格。不是没当计算e[i,j]时都要从头开始计算w(i,j),而是把这些值保存在表w[1..n+1, 0..n]中。
计算基础情况 w[i,i-1] = qi-1,其中 1 <= i <= n;
计算 w[i,j] = w[i,j-1] + pj + qj,其中 i <= j;
因此,可以计算出O(n2)个w[i,j]的值,每一个值需要O(1)计算时间。
下面的代码中,以概率<p, ..., p>和<q, ..., q>以及结点数量n为参数,返回表e和root。运行时间为O(n3)。
OPTIMAL-BST(p, q, n) for i = (1 to n+1) // 1~3行: 循环初始化e[i, i-1]和w[i, i-1]的值 e[i, i-1] = q[i-1] // w[i, i-1] = q[i-1] // for l = (1 to n) // 4~13行: 循环利用递归式计算e[i, j]和w[i, j] for i = (1 to n-l+1) // 第一次迭代时, l=1, 计算e[i,i]和w[i,i], i = 1..n j = i+l-1 // 第二次迭代时, l=2, 计算e[i,i+1]和w[i,i+1], i = 1..n-1 e[i, j] = ∞ // 如此往复 w[i, j] = w[i, j-1] + p[j] + q[j] for r = (i to j) // 9~13行: 尝试每个下标r, 以确定根节点 t = e[i, r-1] + e[r+1, j] + w[i, j] // if t < e[i, j] // 发现更好的下标值则在root[i,j]中保存当前r e[i, j] = t // root[i, j] = r // return e and root
补充:优化OPTMAL-BST过程 (CLRS 15.5-4)
现已被证明,对于所有的 i <= i < j <= n,总存在最优子树的根使得 root[i, j-1] <= root[i, j] <= root[i+1, j]。
利用这个事实我们可以修改OPTMAL-BST过程,使其在O(n2)时间内执行。
将第九行改为:
for r = ( root[i, j-1] to root[i+1, j] )
证明:该算法运行时间为O(n2)。
这一结论可以通过证明每一个e[i, j]的运行时间都是O(n)而得出。我们定义 e[i, j] (其中 j - i = k) 的全部状态集合为第k层集合(显然集合中 n-k 个结点)。所以计算 e[i, j] 需要 root[i+1, j] - root[i, j-1] + 1 次循环。因此,对于所有第k层集合的元素而言,总共需要 root[k, 1] – root[1, k] + n – k 次循环。又因为 1 <= root[k, 1] 且 root[1, k] <= n,所以循环次数为O(n)。
因为 0 <= k <= n-1,所以总循环次数为O(n2)。
该解法由Rip's Infernal Majesty给出。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号