MySQL 索引
Mysql 索引
索引是帮助MySQL高效获取数据的数据结构,,排好序的快速查找数据结构
目的:减少磁盘I/O的次数,加快查询速度
索引主要影响两个位置:
- 快速查找(提高数据查询效率):影响where后面的查找
- 排好序:order by
索引是在存储引擎中实现的
优点
1.提高数据检索的效率,降低数据库的IO成本
2.创建唯一索引,保证数据库表中每一行数据的唯一性
3.在使用分组和排序子句进行数据查询时,可以减少查询中分组和排序的时间,降低CPU的消耗
缺点
1.创建索引和维护索引要耗费时间,并且随着数据量增加,所耗费的时间也会增加。
2.索引需要磁盘空间,一般索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储在磁盘中。
3.降低更新表的速度,当对表中的数据进行增加、删除和修改时,索引也要动态维护,这样就降低了数据的维护速度
索引可以提高查询的速度,但是会影响插入记录的速度。这种情况下,最好的办法是先删除表中的索引,然后插入数据,插入完成后再创建索引。
InnoDB的索引模型
一个简单的设计方案
CREATE TABLE index_demo(
c1 INT,
c2 INT,
c3 CHAR(1),
PRIMARY KEY(c1)
)ROW_FORMAT = Compact # 行格式表示每个记录的格式ROW_FORMAT
Compact
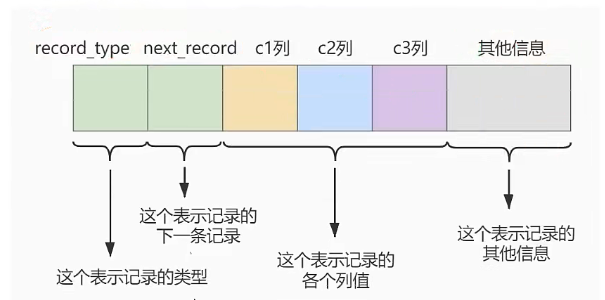
record_type:
0 普通记录
1 目录项记录
2 最小记录
3 最大记录
案例
假设每个数据页最多存放3条记录
INSER INTO index_demo VALUES(1,4,'u'),(5,3,'y'),(3,9,'d')
按主键从小到大的顺序排列
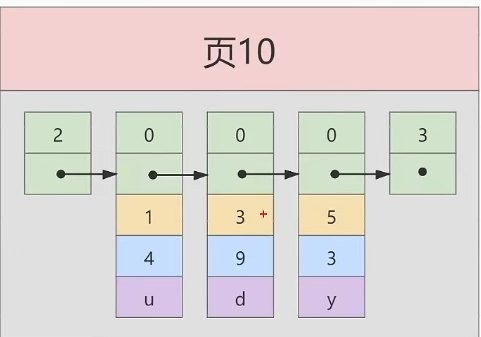
此时数据页10已经有三条记录了,假设现在再插入一条记录,那么需要再分配一个数据页
INSERT INTO index_deomo VALUES(4,4,'a')
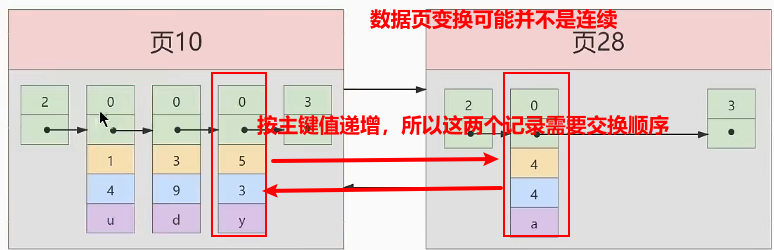
假设现在需要查询一条记录,由于数据页的编号可能是不连续的,所以查询的时候可能需要每个数据页都进去查看一遍,效率是非常低的。

给每个页建立一个目录项
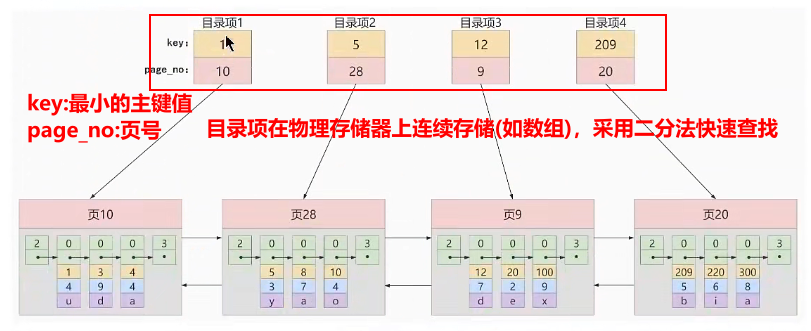
先在目录项上查找,然后再进入具体的数据页查找,这样可以提高查询效率
迭代1次:目录项记录的页(目录页)
上述目录项采用物理上连续的空间存储(如数组)
1.如果当目录项个数很多时,可能并没有足够多的连续空间
2.当发生增删改目录项时,为了维持key有序,是非常麻烦的
目录项也采用单项链表上连接,此时目录项也构成了一个页,称为目录页
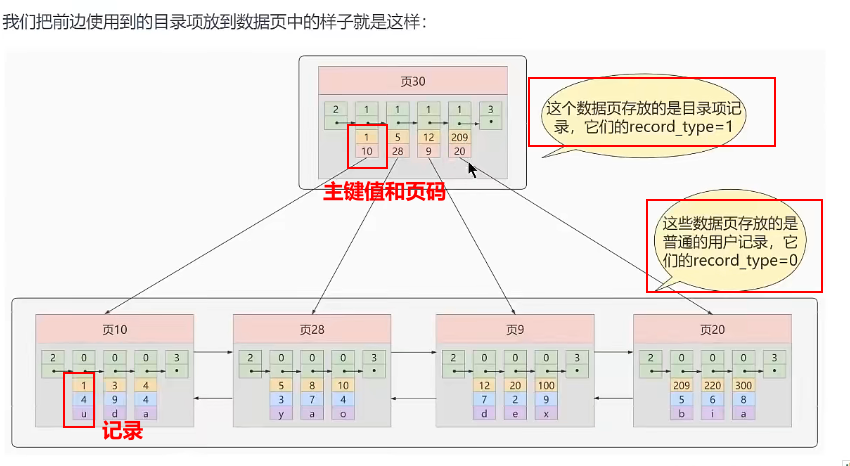
目录项记录和普通的用户记录的异同点
| 不同点 | 目录项记录 | 用户记录 |
|---|---|---|
| record_type | 1 | 0 |
| 存储的内容 | 只有主键值和页标号 | 用户自定义的 |
| min_rec_mask | 只有目录页中主键最小的目录项记录为1,其余都为0 | 0 |
相同点
都会为主键值生成Page Directory页目录,目的是为了使用二分法来加快查询速度。因为页中的是通过链表链接,删除和添加很快,但是查询很慢
假设要查询主键为20的记录
1.先再目录页通过二分法查找页目录,12<20<209,定位到记录在页9
2.到页9的页目录中采用二分法快速找到主键值为20的用户记录
只有2次IO操作
迭代2次:目录项记录的多个页
假设一个目录页已经记录完了,就需要再分配一个新的存储目录项记录的页
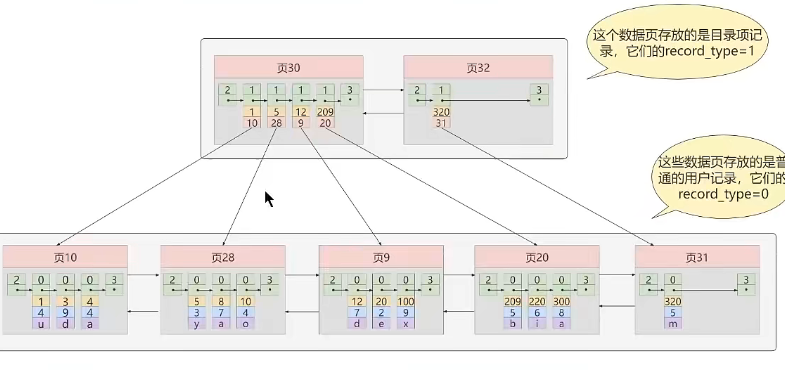
如果要查找某个记录,就需要先使用二分法在页30的页目录查找,如果没找到需要去页32的页目录查找
迭代3次:目录项记录页的目录页
如果需要查找的记录在目录页的很后面,那需要多次的IO访问
由于页是不连续的,为了快速定位,我们需要在套一层目录。这样可以稳定IO访问次数
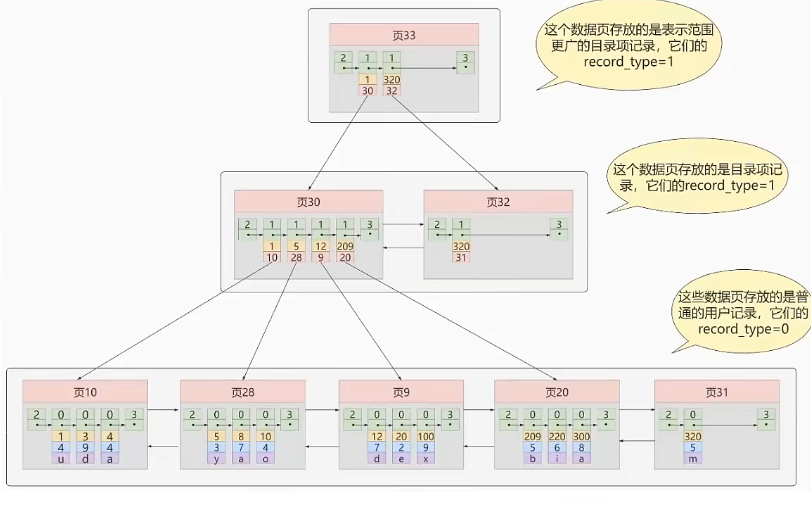
B+ 树能够很好地配合磁盘的读写特性,减少的磁盘I/O操作的次数。
这个数据结构就是B+树
1.只有叶子节点存储数据
2.每一个父节点的元素都出现在子元素中,是子节点的最大(小)元素
3.叶子节点之间通过链表连接,
假设一个数据页可以存放100条用户记录,一个目录页可以存放1000条目录项记录
B+树有一层,可以存放100条记录
B+树有两层,可以存放1000*100 = 10,0000条数据
B+树有三层,可以存放1000*1000*100=1,0000,0000条数据
....
一般情况下,用到的B+树都不会超过4层
1.已经可以存储相当多的数据了
2.层数越低,访问IO的次数越少
聚簇索引
索引分为:
- 聚簇索引:由主键构建,聚簇表示记录和目录存储在一起
- 非聚簇索引/二级索引/辅助索引:由非主键构建,非聚簇是不存储真正的数据的
所有完整的用户记录(包括隐藏列)都存放在聚簇索引的叶子节点处。InnoDB中不需要显示的使用INDEX语句去创建聚簇索引,InnoDB存储引擎会自动为我们创建聚簇索引
优点
1.访问速度更快
2.聚簇索引对主键的排序查找和范围查找速度非常快
3.按照聚簇索引排列顺序,查询一定范围数据的时候,由于数据都是紧密相连的,数据库不用从多个数据块中提取数据,所以节省了IO操作
缺点
1.插入速度严重依赖插入顺序,对于InnoDB表,我们一般会定义自增的ID列为主键
2.更新主键的代价很高,因为会导致主键被更新后行移动,对于InnoDB,我们一般定义主键不可更新
3.二级索引访问需要两次索引查找,第一次查找主键值,第二次根据主键值查找行数据
尽量使用自增主键
NOT NULL PRIMARY KEY AUTO_INCREMENT
每次插入一条新记录,都是追加操作,都不涉及到挪动其他记录,也不会触发叶子节点的分裂。
如果使用业务逻辑的字段做主键,则往往不容易保证有序插入,这样写数据成本相对较高。
限制
1.MySQL数据库中只有InnoDB数据引擎支持聚簇索引,而MyISAM并不支持聚簇索引
2.由于数据物理存储方式只有一种,所以每个MySQL的表只能有一个聚簇索引
3.如果没有定义主键,Innodb会选择非空的唯一索引代替,如果没有,Innodb会隐式定义一个索引来作为聚簇索引
二级索引(辅助索引、非聚簇索引)
假设c2列为索引,则叶子节点记录c2的值和对应的主键值
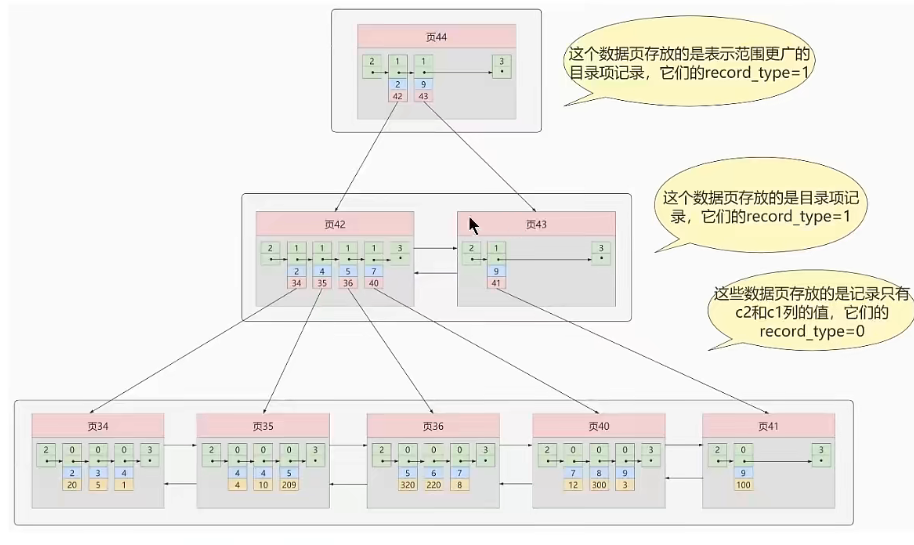
每个索引对应一个B+树
假设需要找c2=4的记录,先在这颗B+树上找到对应的主键为1,在去主键B+树去找主键为1的记录,这个过程称为回表。
联合索引
联合索引同时为多个列建立索引,假设我们想让B+树按照c2和c3列的大小排序。会先按照c2进行排序,如果c2相同会按照c3列进行排序
InnoDB的B+树索引的注意事项
- 1 跟页面位置万年不动
- 2 内节点中目录项记录的唯一性
- 3 一个页面最少存储2条记录
1 跟页面位置万年不动
为某个表创建一个B+树索引(聚簇索引不是人为创建的,默认就有)的流程
1.为这个索引创建一个根节点页面。最开始表中没有数据的时候,每个B+树索引对应的根节点中既没有用户记录,也没有目录项记录
2.向表中插入用户记录时,先把用户记录存储到这个根节点中
3.当根节点中的空间用完时,继续插入记录,会将根节点的所有记录复制到一个新分配的页a,然后对新页面进行页分裂操作,得到一个新页b。新记录根据键值的大小会分配到页a或页b中,而根节点便升为目录页
4.当跟节点空间用完时,继续插入记录,会将跟节点的所有记录复制到一个新分配的页C,然后对新页面进行页分裂操作,得到一个新页d,根节点便升为目录页的目录页
2 内节点中目录项记录的唯一性
主要针对二级索引
B+树中目录项记录的内容是索引列+列号,对于二级索引来说不严谨。假设表中的数据是
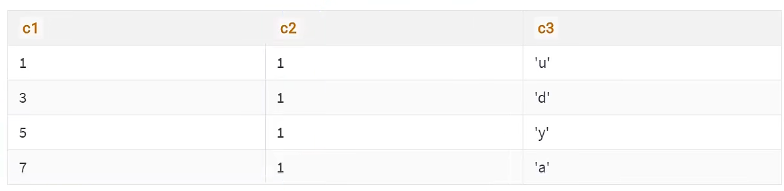
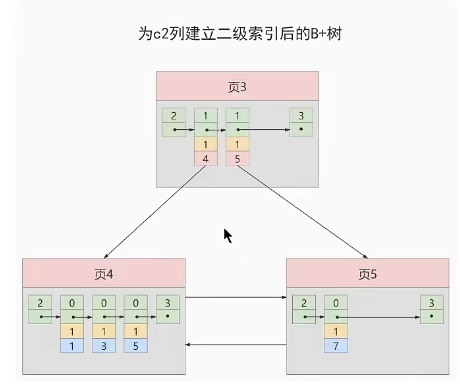
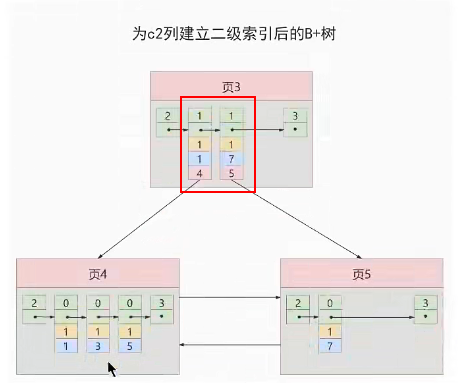
保证B+树的同一层内节点的目录项记录(除页号,页号肯定是不一样的)是唯一的
所以对于二级索引的内节点的目录项记录的内容是由三个部分构成
- 索引列的值
- 主键值,保证唯一性
- 页号
二级索引的内节点的目录项也保留了主键值
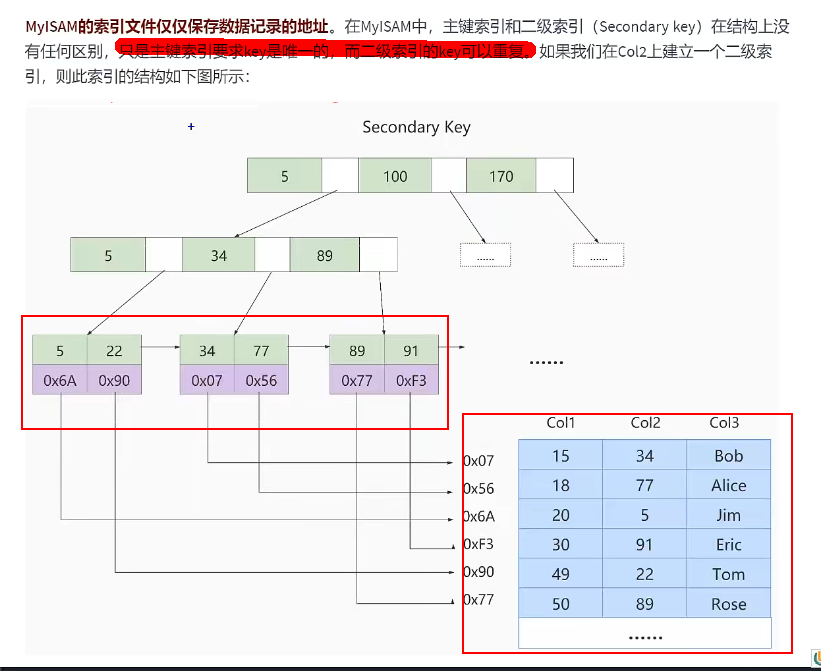
MyISAM与InnoDB的对比
主键索引和二级索引的结构都一样
| 类型 | MyISAM | InnoDB |
|---|---|---|
| 索引方式 | 非聚簇,无聚簇索引 | 包含1个聚簇索引,可以包含非聚簇索引 |
| 主键值查找 | 相当于都是二级索引,所以会进行一次回表操作 主键的树叶子节点没有存储记录,存储的是记录的地址,去地址值找也算一次回表 |
主键值对聚簇索引进行一次查找就能找到对应的记录 |
| 数据文件 | 索引文件和数据文件分离 索引文件仅存储数据记录的地址 数据文件按照添加顺序,不需要排序 |
数据文件本身就是索引文件 |
| 回表操作 | 非常的快速,直接根据偏移量去文件中取数据 | 速度慢一点 |
| 非聚簇索引data值 | 记录的是地址 | 引用主键作为data域 |
| 主键 | 可以没有 | 一定有 |
为什么不适用Hash结构?
1.Hash索引仅满足(=<>IN)查询,进行范围查询的速度很慢,因为数据的存储是无序的,如果在ORDER BY的情况下,还需要对数据重新排序
2.对应联合索引,Hash值是将联合索引键合并一起来计算,无法对单独的一个键或几个键进行查询
3.对于等值查询,通常Hash索引效率更高,但是查询的Hash冲突的值过多时,效率回下降。
InnoDB本身不支持Hash索引,但是提供自适应Hash索引,如果某个数据经常被访问,就会将这个数据页的地址放到Hash表中,下次查询时就可以直接找到这个页面的所在位置。
采用自适应Hash索引可以根据SQL的查询条件快速定位到叶子节点,尤其当B+树比较深的时候,通过自适应Hash索引可以明显提高数据的检索效率。
通过innodb_adaptive_hash_index变量查询是否开启自适应Hashshow variables like'%adaptive_hash_index',默认时开启的
索引的创建与设计原则
索引的分类
普通索引
1.不加任何限制条件,只是用于提高查询效率
2.可以创建在任何数据类型中,其值是否唯一和非空,要由字段本身的完整性约束条件决定。
唯一性索引
1.凡是什么的UNIQUE的字段,都会自动创建唯一性索引
2.该索引的值必须是唯一的,但允许有空值。
3.在一张数据表里可以有多个唯一索引
4.删除唯一性约束是通过删除唯一性索引实现的
主键索引
1.主键索引是特殊的唯一性索引,主键索引 = NOT NULL + UNIQUE
2.一个表最多只有一个主键索引
单列索引
在表中的单个字段上创建索引。
多列(组合)索引
1.多列索引是在表的多个字段创建一个索引。
2.该索引指向创建时对应的多个字段,但是只有查询条件中使用了这些字段中的第一个字段时才会被使用。
3.使用组合索引时遵循最左前缀原则
创建索引
1.在创建表的定义语句CREATE TABLE中指定索引列
2.使用ALTER TABLE语句在存在的表上创建索引
3.CREATE INDEX语句在已存在的表上添加索引
# 隐式的方式创建索引。在声明有主键约束、唯一性约束、外键约束的字段上会是自动添加对应的索引
# 显式的方式创建
CREATE TABLE table_name [col_name data_type]
[UNIQUE|FULLTEXT|SPATIAL] [INDEX|KEY] [index_name](col_name[length]) [VISIBLE(默认)|INVISIBLE] [ASC(默认)|DESC]
CREATE TABLE book(
book_id INT PRIMARY KEY AUTO_INCREMENT,# 3.主键索引只能通过定义主键约束的方式
book_name VARCHAR(100),
info CHAR(100),
# 1.声明普通索引idx_bname索引名字,book_name索引的字段
INDEX idx_bname(book_name),
# 2.声明唯一性索引,添加数据时,不能重复可以添加null
UNIQUE uq_index_info(info)
)
# 通过命令查看索引
SHOW CREATE TABLE book;
SHOW INDEX FROM book;
# 性能分析工具:EXPLAIN 会分析本条查询语句可能使用的索引与实际使用的索引
EXPLAN SELECT * FROM book WHERE book_name = 'MySQL';
# ALTER TABLE ... ADD INDEX ...
ALTER TABLE book ADD INDEX idx_bname(book_name)
# CREATE INDEX ... ON ...
CREATE INDEX idx_bname ON book(book_name)
UNIQUE、FULLTEXT、SPATIAL可选参数,分别指定唯一性索引、全文索引、空间索引
创建索引时,可以用INDEX(推荐)也可以用KEY
index_name指定索引的名称,如果不指定MySQL默认是col_name
col_name为需要创建索引的字段列,该列必须从表中定义的列中选择
只有字符串的字段才可以指定索引长度length
删除索引
使用场景:进行大量数据的增删改之前可以先把索引删掉
# ALTER TABLE ... DROP INDEX ...
ALTER TABLE book DROP INDEX idx_bname;
# DROP INDEX ... ON ...
DROP INDEX idx_bname ON book;
# 删除表中的某字段,联合索引里面的对应字段也会删除
添加AUTO_INCREMENT约束字段的唯一索引不能被删除
降序索引与隐藏索引
仅innoDB引擎支持
CREATE TABLE ts(
a INT,
b INT,
INDEX idx_a_b(a ASC,b DESC) # a相同时,按b降序排列
)
隐藏索引使用场景
1.如果删除索引后,发现出错需要将索引重新创建,如果数据量本身很大,这种操作会消耗系统过多的资源,操作成本非常高
将需要删除的索引设置成隐藏索引,查询器不再使用这个索引,确认没有影响后,就可以彻底删除索引。
先将索引设置为隐藏索引再删除索引的方式叫做软删除
2.如果想知道某个索引删除之后的查询性能影响,可以先隐藏该索引
注意
1.主键不能设置为隐藏索引,因为当表中没有显示主键时,表中第一个唯一非空索引会成为隐式主键
2.当索引被隐藏时,它的内容仍然是和正常索引一样实时更新,如果一个索引长期被隐藏,可以删除,因为索引的存在会影响插入、更新、删除的性能
# 增加直接在创建索引时 后面添加invisible
ALTER TABLE book ADD INDEX idx_bname(book_name)
ALTER TABLE book DROP INDEX idx_bname;
ALTER TABLE book ALTER INDEX idx_bname invisible; #修改
索引的设计原则
适合创建索引的情况
- 字段的数值有唯一性的限制
业务上具有唯一特性的字段,即使是组合字段,也必须建立唯一索引 - 频繁作为WHERE查询条件的字段
- 经常GROUP BY 和 ORDER BY 的列
索引就是让数据按照某种顺序进行存储或检索,而GROUP BY和ORDER BY都需要对数据进行排序,如果同时有GROUP BY和ORDER BY的查询语句,可以设置联合索引。因为GROUP BY比ORDER BY先执行,所以在联合索引中GROUP BY的列在前面。 - UPDATA、DELETE的WHERE条件列 ( 2,4可以结合在一起看 )
如果进行更新的时候,更新的字段是非索引字段,提升的效率会更明显,这是因为非索引字段更新不需要对索引进行维护 - DISTINCT字段需要创建索引
索引会对数据按照某种顺序进行排序,所以去重的时候会快很多 - 多表JOIN连接操作时,创建索引注意事项
连接表的数据尽量不超过3张,对WHERE条件创建索引,对用于连接的字段创建索引(类型要一致,不然自动使用函数转换后,索引会失效) - 使用字符串前缀创建索引
B+树索引中的记录需要把该列的完整字符串存储起来,字符串越大,在索引中占用的空间越大,越费事。在做字符串比较时会占用更多的空间。
问题是截取多少更合适?区分度公式count(distinct left(列名,索引长度))/count(*)结构越接近1越好
假设把adderss的钱12个字符放入二级索引中,因为二级索引中不包含完整的信息,无法对前12个字符相同,后面字符不同的记录进行排序,使用索引前缀的方无法支支持使用索引排序
在varchar字段建立索引时,必须指定索引长度,没必要对全字段建立索引,根据文本区分度决定索引长度
- 区分度高(散列性高)的列适合作为索引
可以使用select count(distinct a)/count(*) from xx来计算区分度,一般33%算时比较高效的索引 - 使用最频繁的列放到联合索引的左侧
补充:在多个字段都要创建索引的情况下,联合索引优于单值索引
不要定义冗余索引:index(a,b,c) 相当于 index(a)、index(a,b)、index(a,b,c)
限制索引的数目
一般单张表索引数量不超过6个
1.每个索引都需要占用磁盘空间,索引越多,需要的磁盘空间就越大
2.索引会影响INSET、DELETE、UPDATE等语句的性能,因为表中的数据更新的同时,索引也会进行调整和更新,会造成负担
3.优化器在选择如何优化查询时,会根据统一的信息,对每一个可以用到的索引进行评估,以生成最好的执行计划,如果同时很多个索引都可以用来查询,会增加MySQL优化器生成执行计划时间,降低查询性能
索引失效的情况
1.联合索引,查询时跳过某个索引
2.计算、函数、类型转换(自动或手动)导致索引失效
# name有索引
SELECT * FROM student WHERE name like 'abc%';
SELECT * FROM student WHERE LEFT(name,3) = 'abc';# 索引失效
3.组合索引中,在使用了范围条件右边的列索引失效
创建联合索引时,可以把范围涉及到的字段写在后面
#索引(age,classId,name) 此时只用上了前两个,第三个没用上
SELECT * FROM student WHERE age = 30 AND classId>20 AND name='abc';
4.不等于(!=或者<>)索引失效/is null可以使用索引,is not null不可以使用索引
5.like以通配符%开头的索引失效
6.or前后存在非索引的列,索引失效

 浙公网安备 33010602011771号
浙公网安备 33010602011771号