生产调优6 HDFS-故障排除
HDFS-故障排除
这里采用三台服务器即可,我们恢复到Yarn开始保存的服务器快照状态
NameNode故障处理
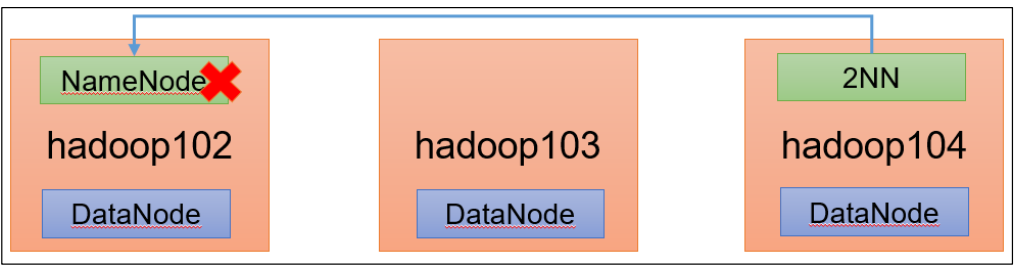
需求
NameNode 进程挂了并且存储的数据也丢失了,如何恢复 NameNode?
模拟故障
1.kill -9 NameNode进程
[ranan@hadoop102 ~]$ jpsall
=============== hadoop102 ===============
2165 NameNode #NameNode进程
2888 JobHistoryServer
2684 NodeManager
3021 Jps
2350 DataNode
=============== hadoop103 ===============
2177 DataNode
2408 ResourceManager
2569 NodeManager
2973 Jps
=============== hadoop104 ===============
2320 SecondaryNameNode
2177 DataNode
2633 Jps
2445 NodeManager
2.删除 NameNode 存储的数据(/opt/module/hadoop-3.1.3/data/tmp/dfs/name)
[ranan@hadoop102 ~]$ rm -rf /opt/module/hadoop-3.1.3/data/dfs/name/*
问题解决
1.假设不知道怎么引起的故障,我们先查看进程,发现NameNode没有启动
[ranan@hadoop102 name]$ jpsall
=============== hadoop102 ===============
2888 JobHistoryServer
2684 NodeManager
3340 Jps
2350 DataNode
=============== hadoop103 ===============
3264 Jps
2177 DataNode
2408 ResourceManager
2569 NodeManager
=============== hadoop104 ===============
2320 SecondaryNameNode
2177 DataNode
2913 Jps
2445 NodeManager
2.启动NameNode,启动失败了
[ranan@hadoop102 name]$ hdfs --daemon start namenode
[ranan@hadoop102 name]$ jpsall
=============== hadoop102 ===============
2888 JobHistoryServer
2684 NodeManager
2350 DataNode
3503 Jps
=============== hadoop103 ===============
2177 DataNode
2408 ResourceManager
2569 NodeManager
3354 Jps
=============== hadoop104 ===============
2320 SecondaryNameNode
2177 DataNode
2986 Jps
2445 NodeManager
3.查看日志/opt/module/hadoop-3.1.3/logs,我们是NameNode挂掉,查看NameNode相关日志
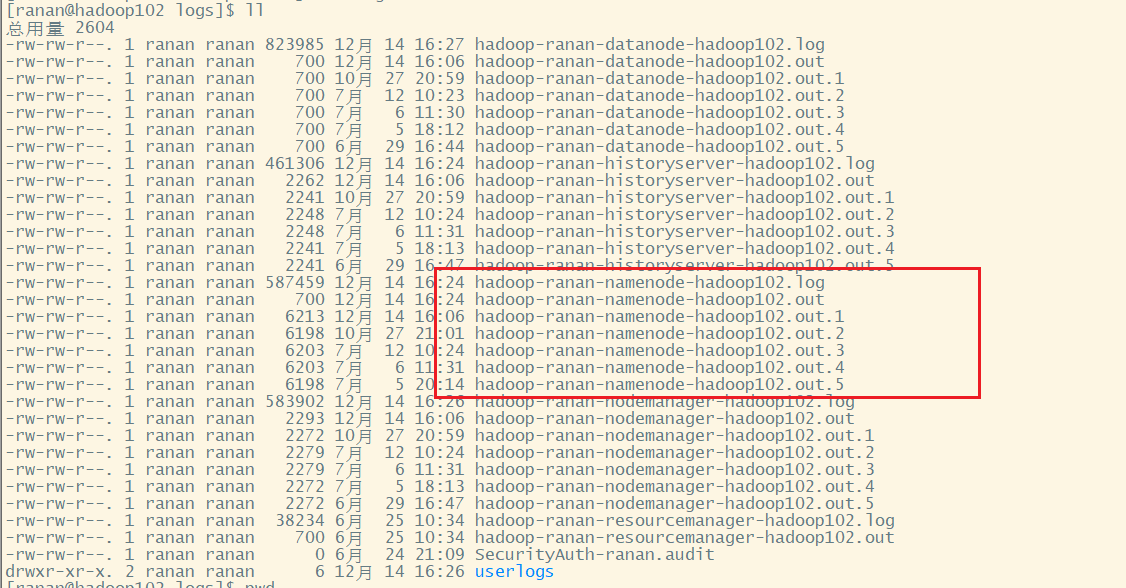
[ranan@hadoop102 logs]$ tail -n 100 hadoop-ranan-namenode-hadoop102.log
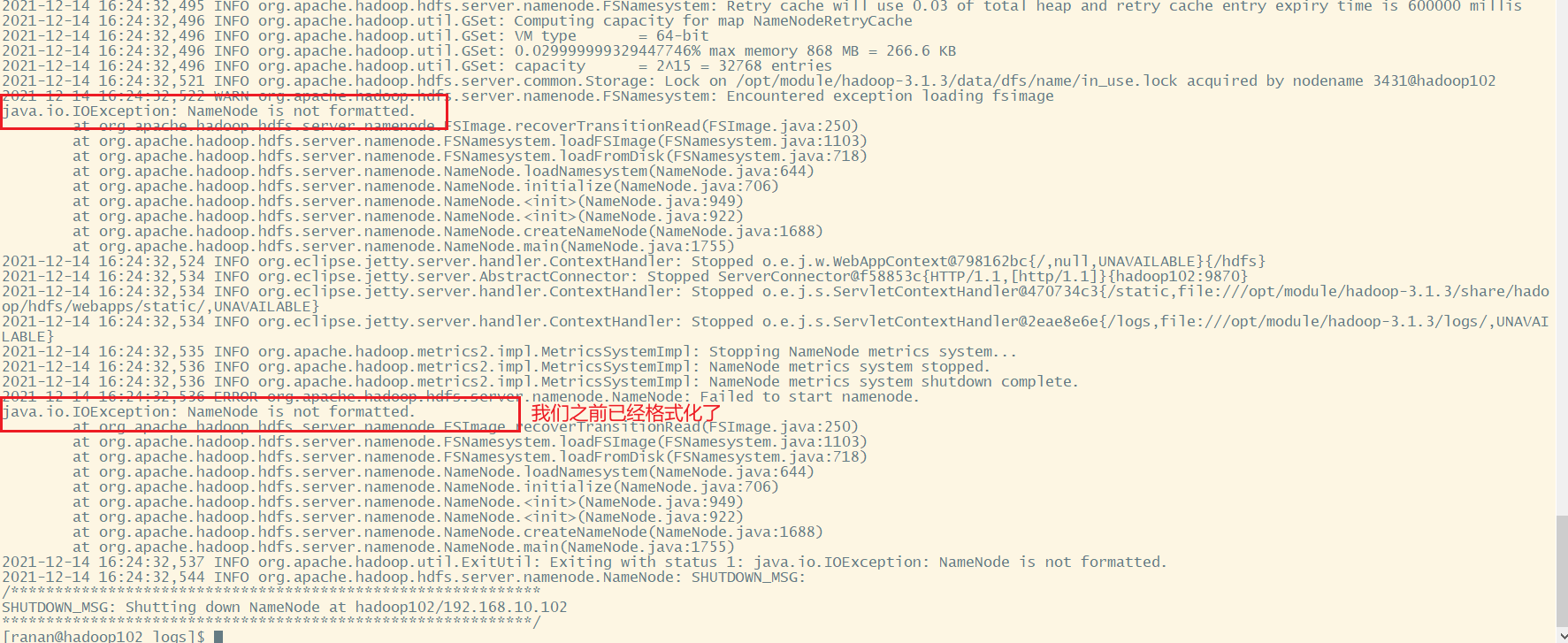
怀疑是NameNode不完整了
4.拷贝 SecondaryNameNode 中数据到原 NameNode 存储数据目录
SecondaryNameNode在hadoop104节点上/opt/module/hadoop-3.1.3/data/dfs/namesecondary
[ranan@hadoop102 name]$ scp -r ranan@hadoop104:/opt/module/hadoop-3.1.3/data/dfs/namesecondary/* ./
5.重新启动 NameNode
[ranan@hadoop102 name]$ hdfs --daemon start namenode
[ranan@hadoop102 name]$ jpsall
=============== hadoop102 ===============
2888 JobHistoryServer
3721 NameNode
2684 NodeManager
2350 DataNode
3807 Jps
=============== hadoop103 ===============
2177 DataNode
3495 Jps
2408 ResourceManager
2569 NodeManager
=============== hadoop104 ===============
2320 SecondaryNameNode
3216 Jps
2177 DataNode
2445 NodeManager
6.在集群上删除一个文件,测试是否正常运行
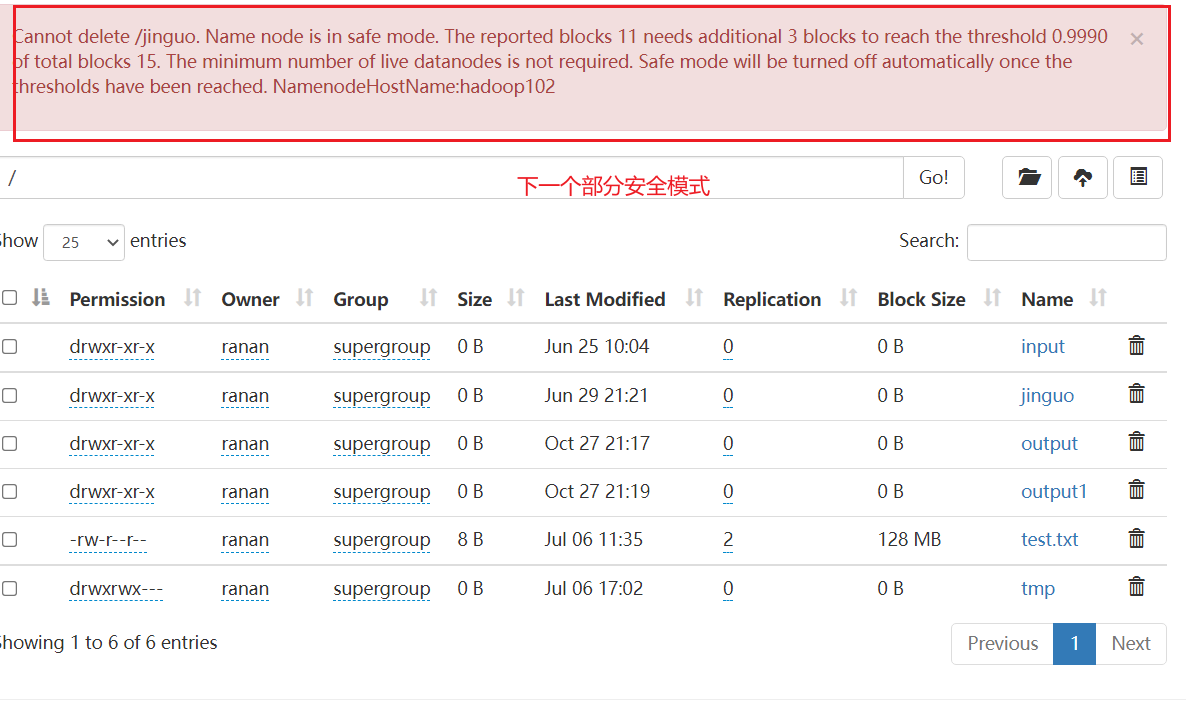
等待30s之后在删除,成功
总结
在生产环境中不会使用SecondaryNameNode,会使用HA(两个NameNode)
集群安全模式&磁盘修复(重要)
安全模式
安全模式: 文件系统只接受读数据请求,而不接受删除、修改等变更请求
进入安全模式场景
1.NameNode在加载镜像文件和编辑日志期间(集群的启动过程中)处于安全模式
2.NameNode在接受DataNode注册时,处于安全模式
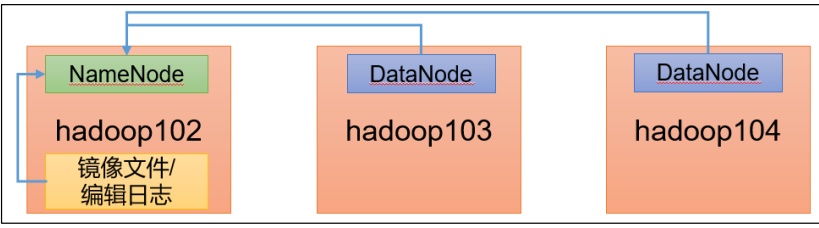
退出安全模式条件
dfs.namenode.safemode.min.datanodes:最小可用 datanode 数量,默认 0表示集群上至少有一个datanode,如果至少有2个,可以设置为1
dfs.namenode.safemode.threshold-pct:副本数达到最小要求的 block 占系统总 block 数的百分比,默认 0.999f。99%的块都启动了,只允许丢一个块。
dfs.namenode.safemode.extension:稳定时间,默认值 30000 毫秒,即 30 秒之后退出安全模式
基本语法
集群处于安全模式,不能执行重要操作(写操作) 。 集群启动完成后,自动退出安全模式。
查看安全模式状态
hdfs dfsadmin -safemode get
进入安全模式状态
hdfs dfsadmin -safemode enter
离开安全模式状态
hdfs dfsadmin -safemode leave
等待安全模式状态
hdfs dfsadmin -safemode wait
案例:磁盘修复
需求
两个数据块损坏,进入安全模式,如何处理?
具体操作
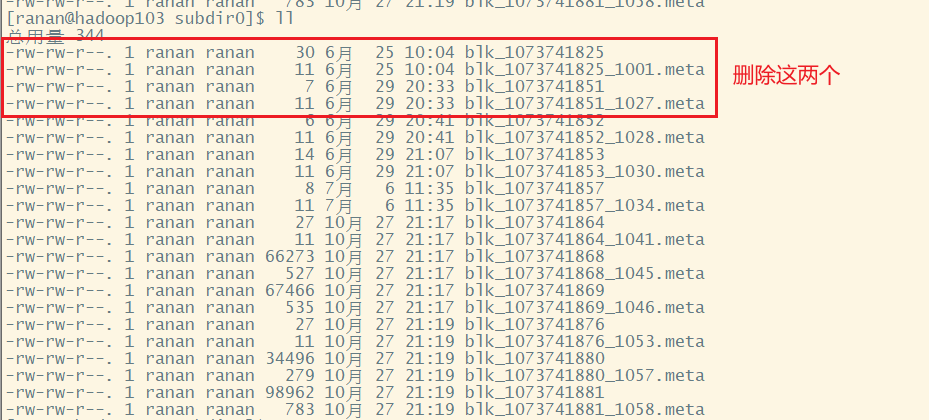
1.损坏2个数据块
分 别 进 入 hadoop102 、 hadoop103 、 hadoop104 的 /opt/module/hadoop-3.1.3/data/dfs/data/current/BP-352852630-192.168.10.102-1624540176574/current/finalized/subdir0/subdir0 目录,统一删除某 2 个块信息
# 以103为例子,102和104同样的操作
[ranan@hadoop103 ~]$ cd /opt/module/hadoop-3.1.3/data/dfs/data/current/BP-352852630-192.168.10.102-1624540176574/current/finalized/subdir0/subdir0
[ranan@hadoop104 subdir0]$rm -rf blk_1073741825 blk_1073741825_1001.meta blk_1073741851 blk_1073741851_1027.meta
2.重新启动集群
此时集群没有什么反应,因为NameNode不知道数据块损害了
在启动时DataNode主动向NameNode汇报,并周期性(默认6个小时)上报所有块消息(块是否完好)。
所以我们需要重新启动集群,让NameNode知道数据块损坏了。
[ranan@hadoop102 subdir0]$ myhadoop.sh stop
[ranan@hadoop102 subdir0]$ myhadoop.sh start
观察 http://hadoop102:9870/dfshealth.html#tab-overview
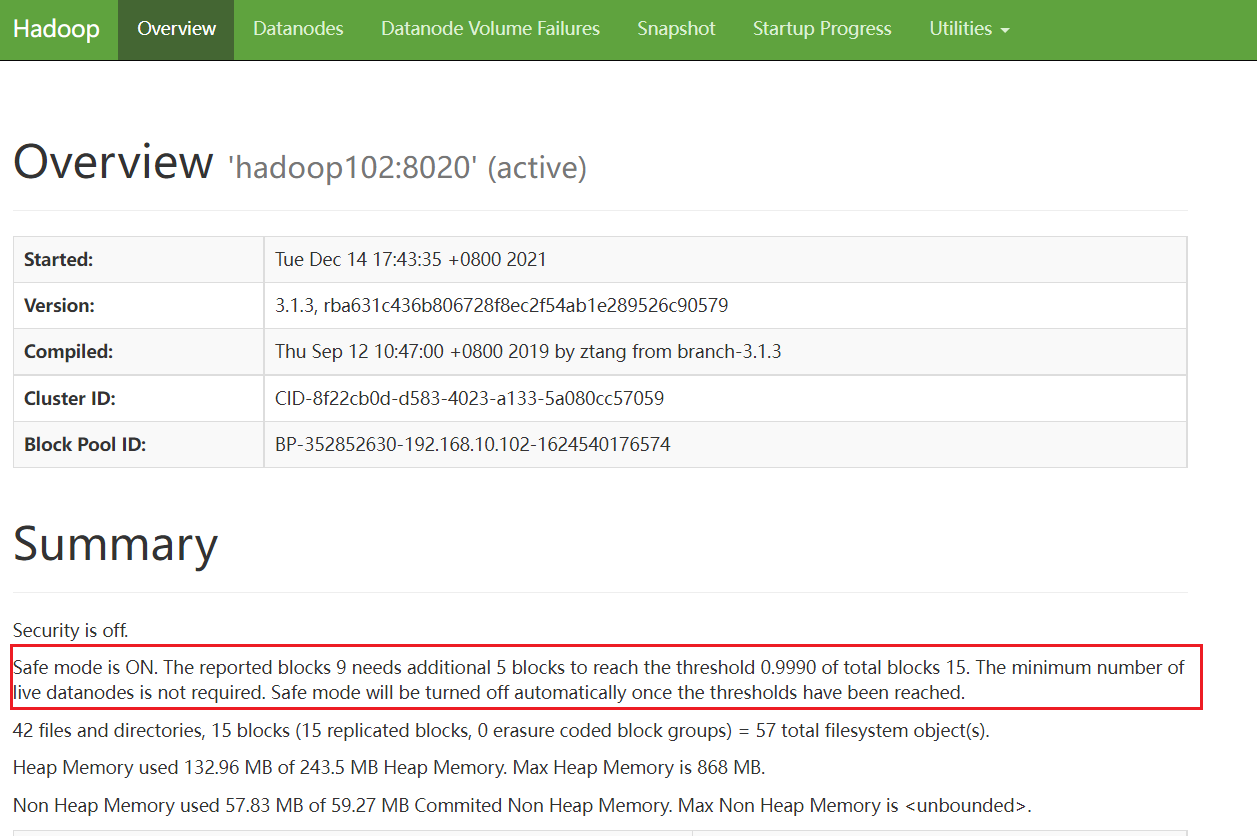
安全模式打开了,块的数量没有达到要求
3.离开安全模式
# 先查看是否在安全模式
[ranan@hadoop102 ~]$ hdfs dfsadmin -safemode get
Safe mode is ON
# 离开安全模式
[ranan@hadoop102 ~]$ hdfs dfsadmin -safemode leave
Safe mode is OFF
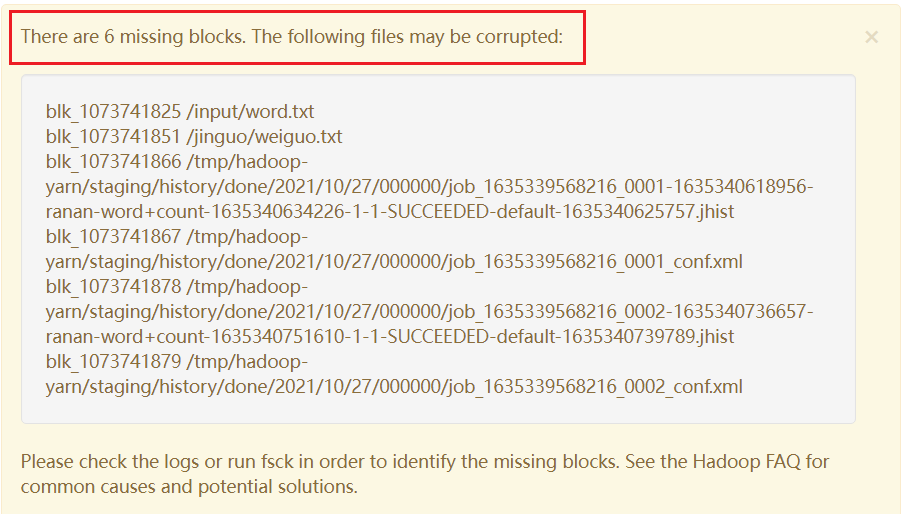
虽然此时可以对集群进行操作了,但是下次重新启动集群(或6个小时得知数据开缺失),又会进入安全模式
有两种办法撤离解决
1.把缺失的数据修复
2.将元数据删除
案例:模拟等待安全模式
类似于银行12.30对账,此时不能存钱不能取钱。希望以对完账,就可以存钱、取钱或其他操作。
# 查看当前模式
[ranan@hadoop102 ~]$ hdfs dfsadmin -safemode get
Safe mode is OFF
# 进入安全模式
[ranan@hadoop102 ~]$ hdfs dfsadmin -safemode enter
Safe mode is ON
创建并执行下面脚本
在/opt/module/hadoop-3.1.3 路径上, 编辑一个脚本 safemode.sh
[ranan@hadoop102 hadoop-3.1.3]$ vim safemode.sh
#!/bin/bash
hdfs dfsadmin -safemode wait # 处于安全模式时,相当于阻塞状态,当安全模式退出,这条命令执行完毕,直接执行下一条
hdfs dfs -put /opt/module/hadoop-3.1.3/README.txt /
[ranan@hadoop102 hadoop-3.1.3]$ chmod 777 safemode.sh
[ranan@hadoop102 hadoop-3.1.3]$ ./safemode.sh

在打开一个窗口,退出安全模式
[ranan@hadoop102 ~]$ hdfs dfsadmin -safemode leave
Safe mode is OFF

慢磁盘监控
“慢磁盘” 指的时写入数据非常慢的一类磁盘。
其实慢性磁盘并不少见,当机器运行时间长了,上面跑的任务多了,磁盘的读写性能自然会退化,严重时就会出现写入数据延时的问题。
如何发现慢磁盘?
正常在 HDFS 上创建一个目录,只需要不到 1s 的时间。如果你发现创建目录超过 1 分
钟及以上,而且这个现象并不是每次都有。只是偶尔慢了一下(比如某一个节点慢),就很有可能存在慢磁盘。
如何找出慢磁盘
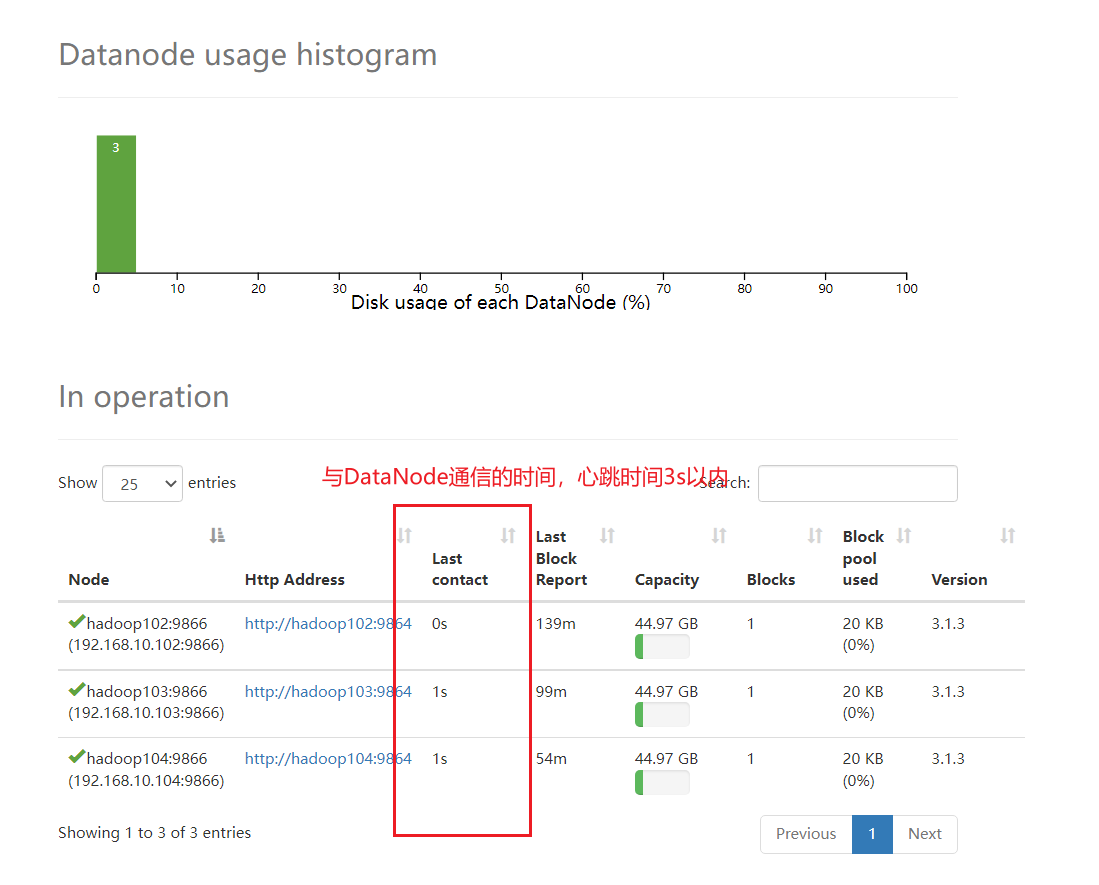
通过心跳时间
一般出现慢磁盘现象,会影响到 DataNode 与 NameNode 之间的心跳。正常情况心跳时
间间隔是 3s。超过 3s 说明有异常。
fio 命令,测试磁盘的读写性能
顺序读测试
1.安装fio测试工具
[ranan@hadoop102 hadoop-3.1.3]$ sudo yum install -y fio
2.执行测试
知道下一次读的位置在哪里,所以速度很快
[ranan@hadoop102 hadoop-3.1.3]$ sudo fio -filename=/home/ranan/test.log -direct=1 -iodepth 1 -thread -rw=read -ioengine=psync -bs=16k -size=2G -numjobs=10 -runtime=60 -group_reporting -name=test_r
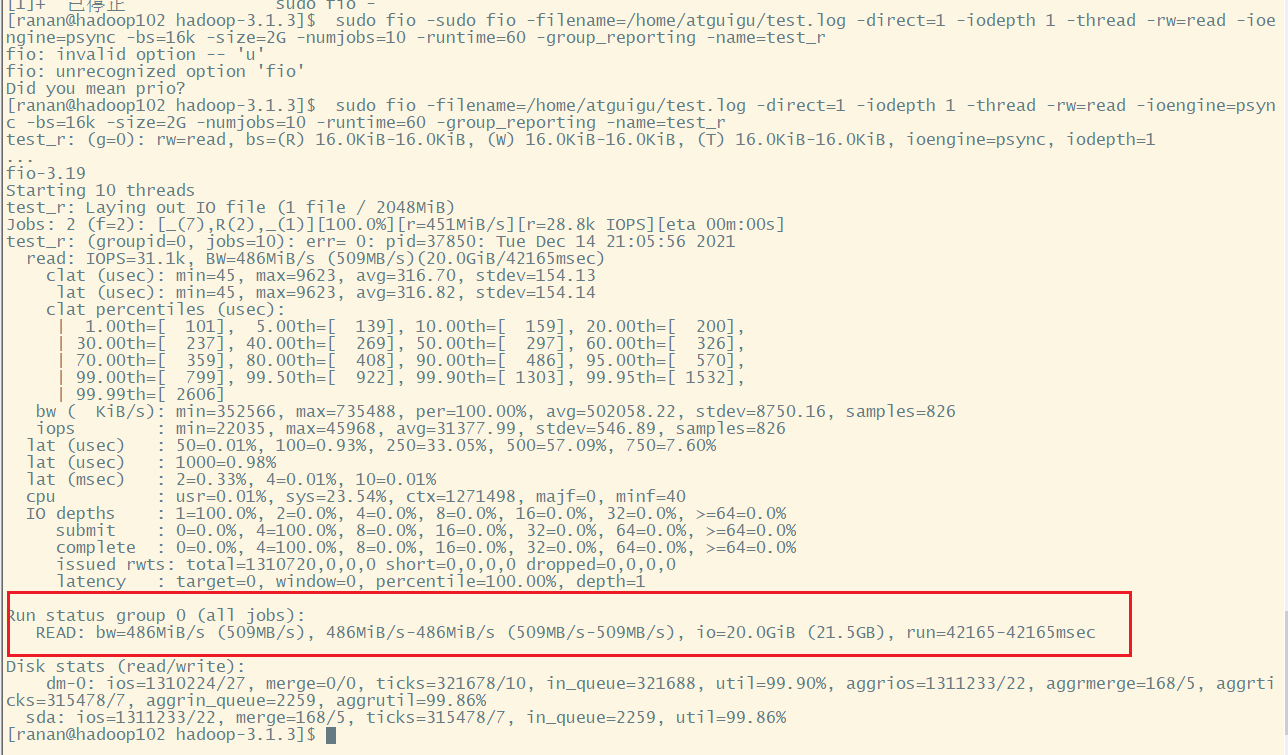
磁盘的总体顺序读速度为486MiB/s
顺序写测试
知道下一次写的位置在哪里,所以速度很快
[ranan@hadoop102 hadoop-3.1.3]$ sudo fio -filename=/home/ranan/test.log -direct=1 -iodepth 1 -thread -rw=write -ioengine=psync -bs=16k -size=2G -numjobs=10 -runtime=60 -group_reporting -name=test_w
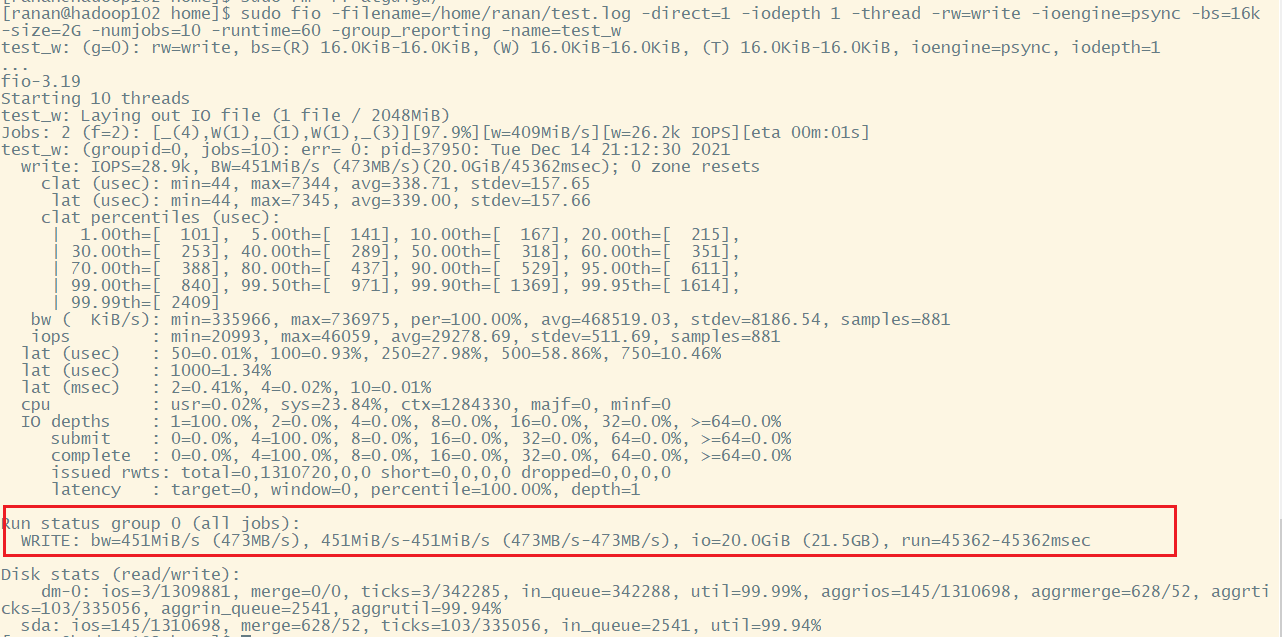
磁盘的总体顺序写速度为 451MiB/s
随机写测试
[ranan@hadoop102 hadoop-3.1.3]$ sudo fio -filename=/home/ranan/test.log -direct=1 -iodepth 1 -thread -rw=randwrite -ioengine=psync -bs=16k -size=2G -numjobs=10 -runtime=60 -group_reporting -name=test_randw
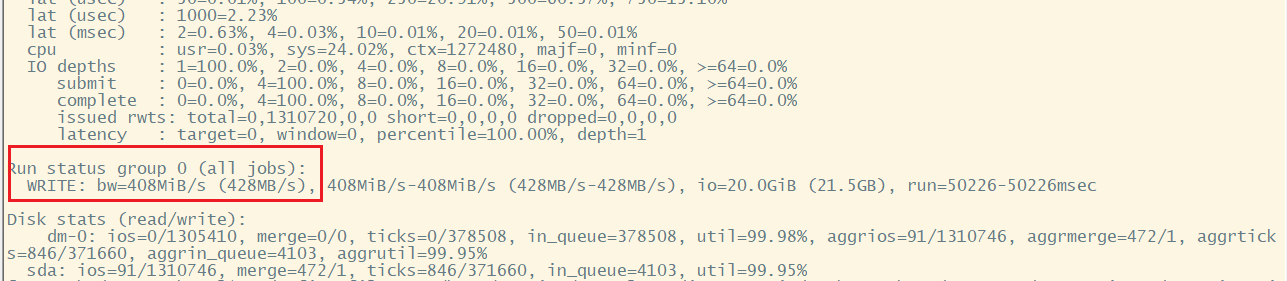
磁盘的总体随机写速度为 408MiB/s
混合随机读写测试
[ranan@hadoop102 hadoop-3.1.3]$sudo fio -filename=/home/atguigu/test.log -direct=1 -iodepth 1 -thread -rw=randrw -rwmixread=70 -ioengine=psync -bs=16k -size=2G -numjobs=10 -runtime=60 -group_reporting -name=test_r_w -ioscheduler=noop
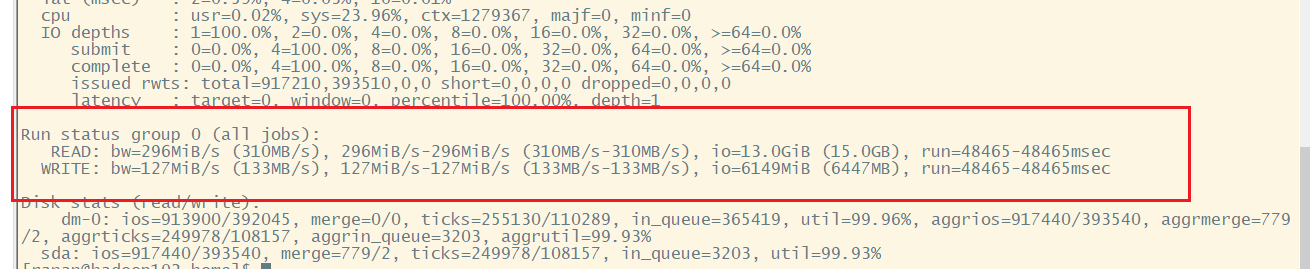
磁盘的总体混合随机读写,读速度为 296iB/s,写速度 127MiB/s。
满磁盘可以作为归档磁盘。
小文件归档
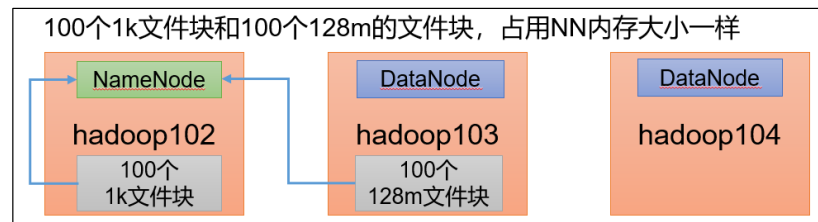
每个文件块大概占用NameNode的150byte,无关数据块大小,因为NameNode相当于是目录
每个文件均按块存储,每个块的元数据存储在 NameNode 的内存中,因此 HDFS 存储小文件会非常低效。因为大量的小文件会耗尽 NameNode 中的大部分内存。但注意,存储小文件所需要的磁盘容量和数据块的大小无关。例如,一个 1MB 的文件设置为 128MB 的块存储,实际使用的是 1MB 的磁盘空间,而不是 128MB。
HDFS存档文件或HAR文件
HDFS 存档文件或 HAR 文件,是一个更高效的文件存档工具, 它将文件存入 HDFS 块,在减少 NameNode 内存使用的同时,允许对文件进行透明的访问。
具体说来, HDFS 存档文件对内还是一个一个独立文件,对 NameNode 而言却是一个整体,减少了 NameNode 的内存

案例实操
1.将合并到一起其实走的MR,所以需要打开YARN
[ranan@hadoop102 hadoop-3.1.3]start-yarn.sh
2.把/input 目录里面的所有文件归档成一个叫 input.har 的归档文件,并把归档后文件存储到/output 路径下
input下面有三个文件
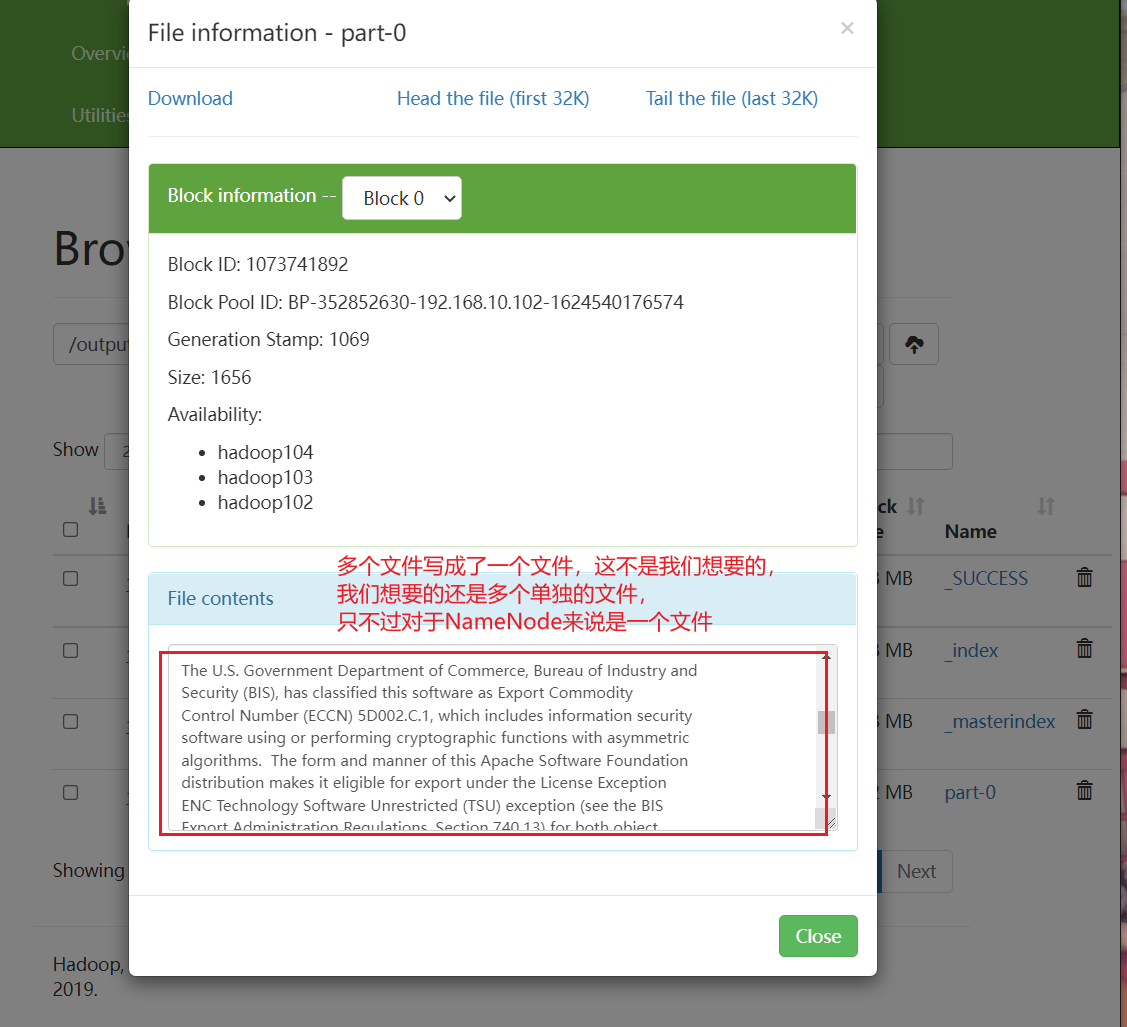
[ranan@hadoop102 hadoop-3.1.3]$ hadoop archive -archiveName input.har -p /input /output
这里查看的内容不是我们想要的
2.查看归档
使用har协议查看
# 这里查看的内容还是我们在网页上看见的
[ranan@hadoop102 hadoop-3.1.3]$ hadoop fs -ls /output/input.har
Found 4 items
-rw-r--r-- 3 ranan supergroup 0 2021-12-15 09:51 /output/input.har/_SUCCESS
-rw-r--r-- 3 ranan supergroup 279 2021-12-15 09:51 /output/input.har/_index
-rw-r--r-- 3 ranan supergroup 23 2021-12-15 09:51 /output/input.har/_masterindex
-rw-r--r-- 3 ranan supergroup 1656 2021-12-15 09:51 /output/input.har/part-0
# 使用har协议
[ranan@hadoop102 hadoop-3.1.3]$ hadoop fs -ls har:///output/input.har
2021-12-15 09:55:36,808 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
Found 3 items
-rw-r--r-- 3 ranan supergroup 1366 2021-12-14 20:45 har:///output/input.har/README.txt
-rw-r--r-- 3 ranan supergroup 47 2021-12-15 09:49 har:///output/input.har/b.txt
-rw-r--r-- 3 ranan supergroup 243 2021-12-15 09:48 har:///output/input.har/nline.txt
3.解归档文件
# 假设拷出b.txt
[ranan@hadoop102 hadoop-3.1.3]$ hadoop fs -cp har:///output/input.har/b.txt /
# 解归档文件
[ranan@hadoop102 hadoop-3.1.3]$ hadoop fs -cp har:///output/input.har/* /

 浙公网安备 33010602011771号
浙公网安备 33010602011771号