MapReduce06 MapReduce工作机制
目录
5 MapReduce工作机制(重点)
5.1 MapTask工作机制
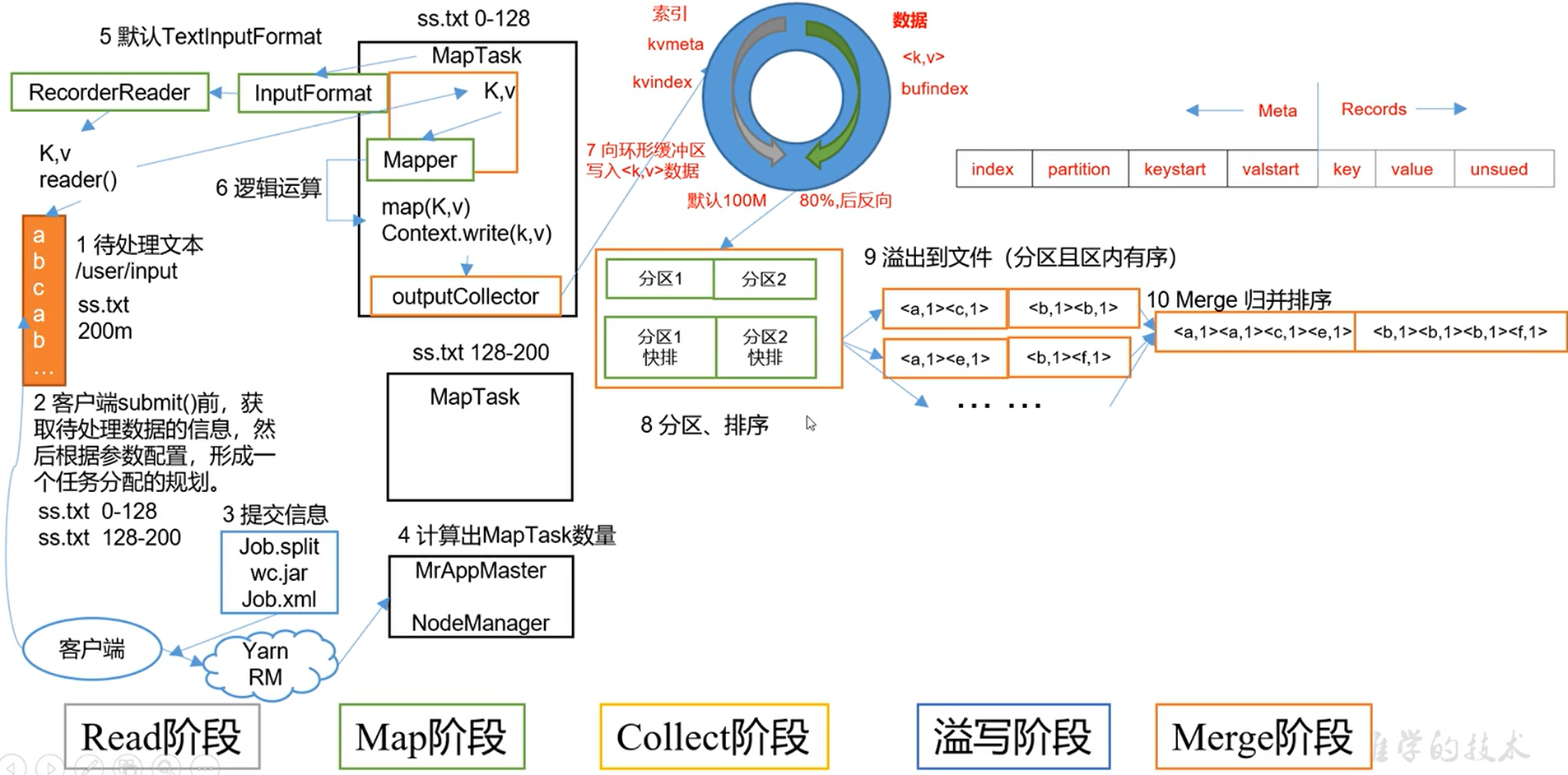
Read阶段
主要是Job的提交流程
1.切片划分
2.提交给Yarn
Job.split 切片信息
wc.jar 集群模式会提交,本地模式不会提交
Job.xml 配置信息
3.Yarn开启NodeManager(单个节点服务器资源老大) AppMaster(单个任务运行的老大) AppMaster开启对应的MapTask进入Map阶段
4.由InputFormat读取数据,默认TextInputFormat,读完之后返回给map,进入用户自己写的Mapper。一个MapTask产生一个文件
5.2 ReduceTask工作机制
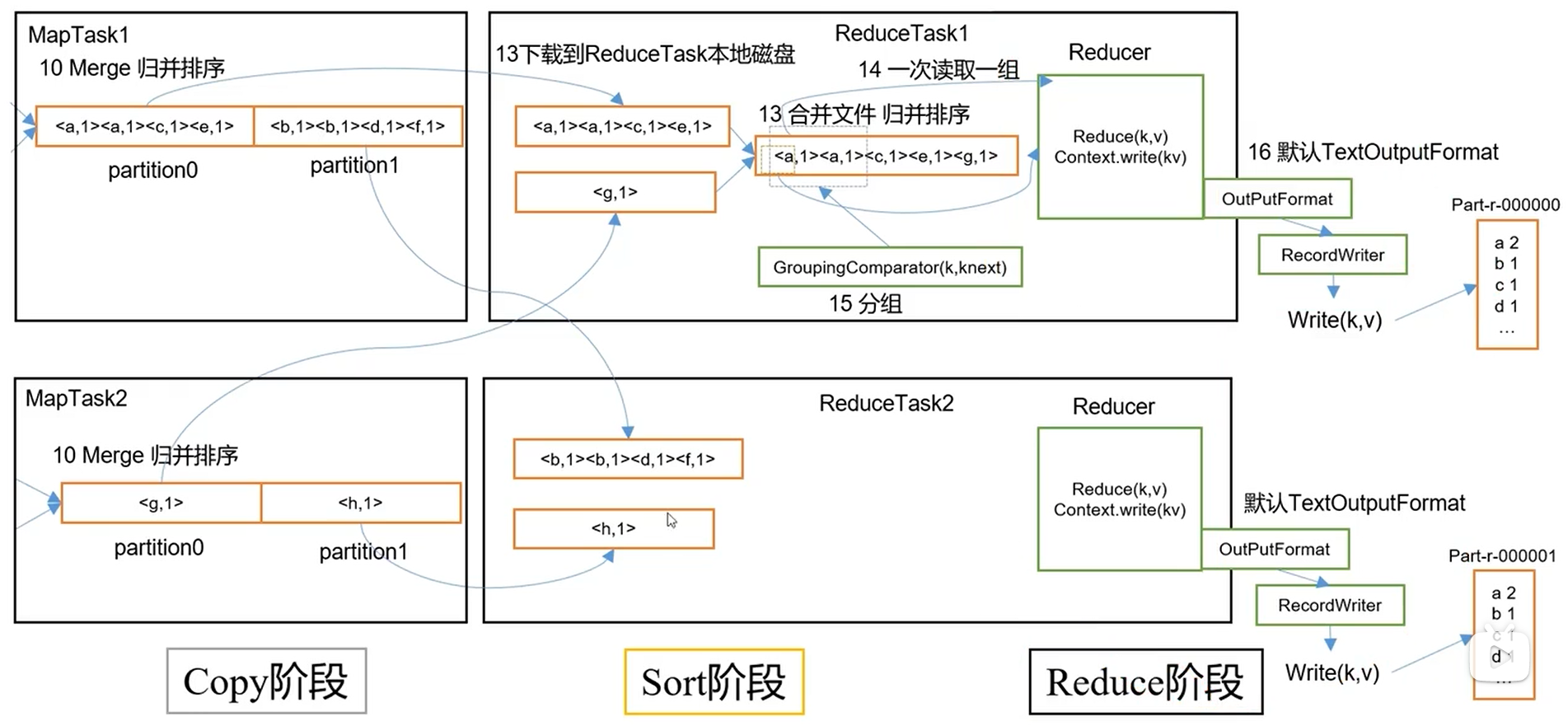
ReduceTask主动去抓取数据
5.3 ReduceTask并行度决定机制
MapTask并行度由切片个数决定,切片个数由输入文件和切片规则决定。
computeSplitSize(Math.max(minSize,Math.min(maxSize,blocksize)))
ReduceTask并行度由谁决定?
手动设置ReduceTask数量
//设置ReduceTasks的个数
job.setNumReduceTasks(5);
测试ReduceTask多少合适
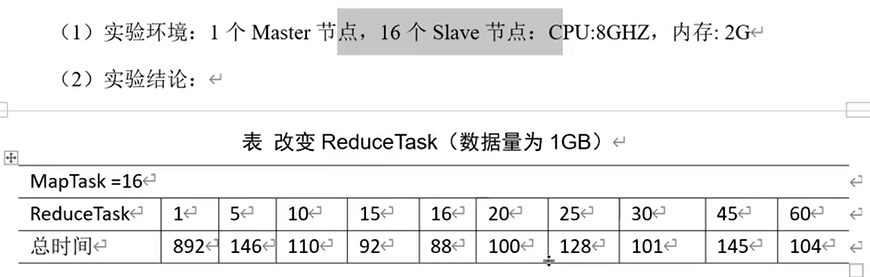
注意事项
1.ReduceTask=0,表示没有Reduce阶段,输出文件个数和Map个数一致。
2.ReduceTask默认值就是1,所以输出文件个数为一个。
3.如果数据分布不均匀,就有可能在Reduce阶段产生数据倾斜(如136 1亿个,其他1个)
4.ReduceTask数量并不是任意设置,还要考虑业务逻辑需求,有些情况下,需要计算全局汇总结果,就只能有1个ReduceTask。
5.具体多少个ReduceTask,需要根据集群性能而定。
6.如果分区数不是1,但是ReduceTask为1,是否执行分区过程。答案是:不执行分区过程。因为在MapTask的源码中,执行分区的前提是先判断ReduceNum个数是否大于1。不大于1肯定不执行。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号