
Hadoop入门 集群常用知识与常用脚本总结
目录
集群常用知识与常用脚本总结
集群启动/停止方式
1 各个模块分开启动/停止(常用)
配置ssh是前提
整体启动/停止HDFS
[ranan@hadoop102 hadoop-3.1.3]$ sbin/start-dfs.sh
[ranan@hadoop102 hadoop-3.1.3]$ sbin/stop-dfs.sh
整体启动/停止YARN
[ranan@hadoop102 hadoop-3.1.3]$ sbin/start-yarn.sh
[ranan@hadoop102 hadoop-3.1.3]$ sbin/stop-yarn.sh
2 各个服务组件逐一启动/停止
分别启动/停止HDFS
hdfs --daemon start datanode/namenode/secondarynamenode
hdfs --daemon stop datanode/namenode/secondarynamenode
分别启动/停止YARN
yarn --daemon start resourcemanager/nodemanager
yarn --daemon stop resourcemanager/nodemanager
编写Hadoop集群常用脚本
1 Hadoop集群启停脚本myhadoop.sh
当集群很多的时候,为了方便启停,自己编写脚本。
包含HDFS、YARN、Historyserver
先到存放全局环境变量的环境下/home/ranan/bin,编写脚本文件myhadoop.sh
注意:脚本中尽量写绝对路径
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== 启动 hadoop 集群 ==================="
echo " --------------- 启动 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh"
echo " --------------- 启动 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver"
;;
"stop")
echo " =================== 关闭 hadoop 集群 ==================="
echo " --------------- 关闭 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver"
echo " --------------- 关闭 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac
给脚本设置执行权限
[ranan@hadoop102 bin]$ chmod 777 myhadoop.sh

2 查看三台服务器Java进程脚本 jpsall
由于每次查看进程都得到每台服务器上输入jps查看,比较麻烦,且如果服务器较多,十分耗时,于是想到编写一个脚本,查看所有服务器的进程情况。
到存放全局环境变量的环境下/home/ranan/bin,编写脚本文件jpsall
#!/bin/bash
for host in hadoop102 hadoop103 hadoop104
do
echo =============== $host ===============
ssh $host jps
done
给脚本设置执行权限
[ranan@hadoop102 bin]$ chmod 777 jpsall
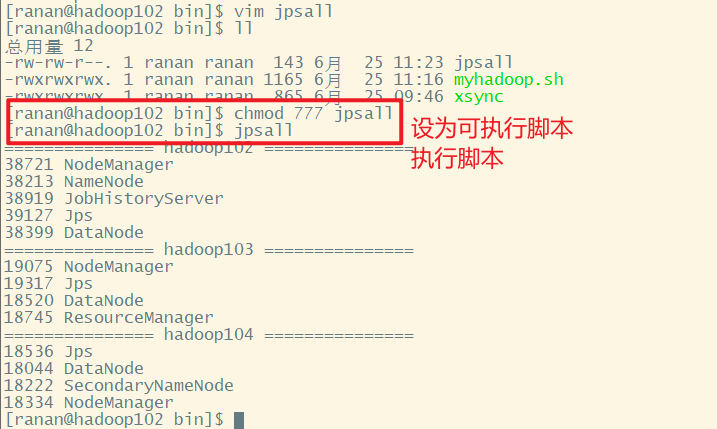
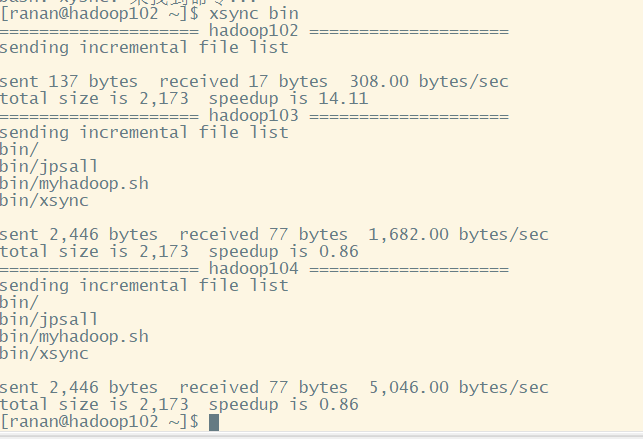
分发脚本
让三台服务器都可以使用脚本
[ranan@hadoop102 ~]$ xsync bin
常用端口说明(面试题)
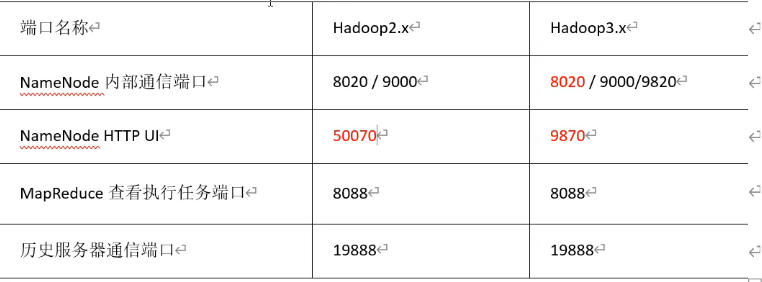
- hadoop3.x
- HDFS NameNode 内部通讯端口:8020/9000/9820
- HDFS NameNode 对用户的查询 端口:9870
- Yarn 查看任务运行情况端口:8088(没变)
- 历史服务器:19888(没变)
- hadoop2.x
- HDFS NameNode 内部通讯端口:8020/9000
- HDFS NameNode 对用户的查询 端口:50070
- Yarn 查看任务运行情况端口:8088
- 历史服务器:19888
常用的配置文件(面试题)
-
hadoop3.x
- core.site.xml
配置NameNode的内部通讯地址,hadoop数据存储在哪个目录下,配置HDFS网页登录使用的静态用户等。 - hdfs-site.xml
配置Namenode的Web访问地址,SecondaryNameNode的web访问地址等。 - yarn-site.xml
MR走什么协议,什么方式进行资源调度,指定ResourceManager部署在哪台节点服务器,日志的聚集等。 - mapred-site.xml
配置mapreduce运行在yarn,配置历史服务器等。 - workers
集群上有几个节点就配置几个主机名称,相当于连接。
- core.site.xml
-
hadoop2.x
- core.site.xml
- hdfs-site.xml
- yarn-site.xml
- mapred-site.xml
- slaves

 浙公网安备 33010602011771号
浙公网安备 33010602011771号