

MySQL优化整理
一、SQL优化
1、show status查看各种sql的执行频率
SHOW STATUS 可以根据需要显示 session 级别的统计结果和 global级别的统计结果。
显示当前session:show status like "Com_%";全局级别:show global status;
比如:show status like "Com_select"
2、定位低效的SQL语句
(1)、show processlist
进入mysql时可用show processlist;不在mysql提示符下使用时用mysql -uroot -e 'Show processlist' 或者 mysqladmin processlist

其中主要的参数是state,下面表列出了state常见的问题以及排查思路:
状态一:sending data
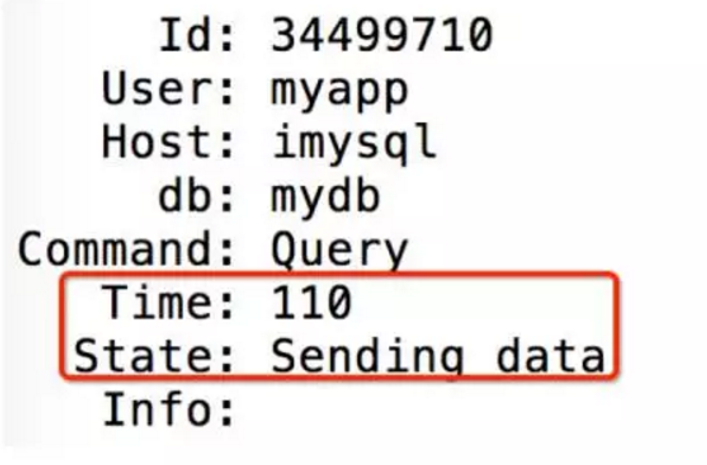
Sending data:表示从引擎层读取数据返回给Server端的状态
长时间存在原因
(1) 没适当的索引,查询效率低
(2) 读取大量数据,读取缓慢
(3) 系统负载高,读取缓慢
解决方法:
(1) 加上合适的索引
(2) 或者改写SQL,提高效率
(3) 增加LIMIT限制每次读取数据量
(4) 检查&升级I/O设备性能
状态二、Waiting for table metadata lock
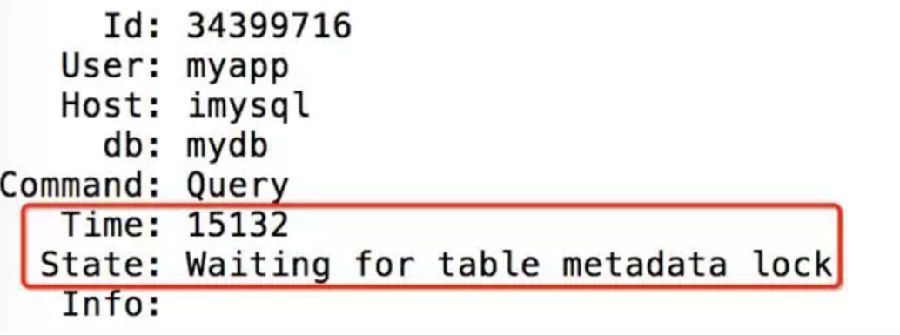
Waiting for table metadata lock:长时间等待MDL锁
原因:
(1) DDL被阻塞,进而阻塞他后续SQL
(2) DDL之前的SQL长时间未结束
解决方法:
(1) 提高每个SQL的效率
(2) 干掉长时间运行的SQL
(3) 把DDL放在半夜等低谷时段
(4) 采用pt-osc执行DDL
状态三、Sleep

危害:
(1) 占用连接数
(2) 消耗内存未释放
(3) 可能有行锁(甚至是表锁)未释放
解决方法:
(1) 适当调低timeout
(2) 主动Kill超时不活跃连接
(3) 定期检查锁、锁等待
(4) 可以利用pt-kill工具
状态四:Copy to tmp table
原因:
(1) 执行alter table 修改表结构,需要生成临时表
(2) 建议放在夜间低谷执行,或者用pt-osc
状态五:Creating tmp table
常见于group by 没有索引的情况,需要拷贝数据到临时表[内存/磁盘上],执行计划中会出现Using temporary关键字。建议创建合适的索引,消除临时表
状态六、Creating sort index
常见于order by 没有索引的情况,需要进行filesort排序,执行计划中会出现Using filesort关键字。建议创建排序索引。
(2)、通过慢查询日志定位
启动慢查询日志:set global slow_query_log=1;设置超时时间:set global long_query_time=4
3、用EXPLAIN分析低效SQL
mysql> explain select * from (select * from ( select * from t1 where id=2602) a) b; +----+-------------+------------+--------+-------------------+---------+---------+------+------+-------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+------------+--------+-------------------+---------+---------+------+------+-------+ | 1 | PRIMARY | <derived2> | system | NULL | NULL | NULL | NULL | 1 | | | 2 | DERIVED | <derived3> | system | NULL | NULL | NULL | NULL | 1 | | | 3 | DERIVED | t1 | const | PRIMARY,idx_t1_id | PRIMARY | 4 | | 1 | | +----+-------------+------------+--------+-------------------+---------+---------+------+------+-------+
主要有两个重要的参数:type和Extra
(1)type:表示MySQL在表中找到所需行的方式,又称“访问类型”。
常用的类型有: ALL, index, range, ref, eq_ref, const, system, NULL(从左到右,性能从差到好)
ALL:Full Table Scan, MySQL将遍历全表以找到匹配的行
index: Full Index Scan,index与ALL区别为index类型只遍历索引树。这种类型表示是mysql会对整个该索引进行扫描。要想用到这种类型的索引,对这个索引并无特别要求,只要是索引,或者某个复合索引的一部分,mysql都可能会采用index类型的方式扫描。但是呢,缺点是效率不高,mysql会从索引中的第一个数据一个个的查找到最后一个数据,直到找到符合判断条件的某个索引。
range: 只检索给定范围的行,使用一个索引来选择行。当使用=、<>、>、>=、<、<=、IS NULL、<=>、BETWEEN或者IN操作符,用常量比较关键字列时,可以使用range:
SELECT * FROM tbl_name WHERE key_column = 10;
SELECT * FROM tbl_name WHERE key_column BETWEEN 10 and 20;
SELECT * FROM tbl_name WHERE key_column IN (10,20,30);
SELECT * FROM tbl_name WHERE key_part1= 10 AND key_part2 IN (10,20,30);
ref: 对于每个来自于前面的表的行组合,所有有匹配索引值的行将从这张表中读取。如果联接只使用键的最左边的前缀,或如果键不是UNIQUE或PRIMARY KEY(换句话说,如果联接不能基于关键字选择单个行的话),则使用ref。如果使用的键仅仅匹配少量行,该联接类型是不错的。 ref可以用于使用=或<=>操作符的带索引的列。
SELECT * FROM ref_table WHERE key_column=expr; SELECT * FROM ref_table,other_table WHERE ref_table.key_column=other_table.column; SELECT * FROM ref_table,other_table WHERE ref_table.key_column_part1=other_table.column AND ref_table.key_column_part2=1;
eq_ref: 使用的索引是唯一索引,对于每个索引键值,表中只有一条记录匹配,即多表连接中使用primary key或者unique key作为关联条件
const: 表最多有一个匹配行,它将在查询开始时被读取。因为仅有一行,在这行的列值可被优化器剩余部分认为是常数。const用于用常数值比较PRIMARY KEY或UNIQUE索引的所有部分时。
比如查询:SELECT * from tbl_name WHERE primary_key=1;tbl_name可以用const表。
system: 表仅有一行(=系统表)。这是const联接类型的一个特例。
NULL: MySQL在优化过程中分解语句,执行时甚至不用访问表或索引,例如从一个索引列里选取最小值可以通过单独索引查找完成。
(2)Extra: 该列包含MySQL解决查询的详细信息,有以下几种情况:
Using where: 列数据是从仅仅使用了索引中的信息而没有读取实际的行动的表返回的,这发生在对表的全部的请求列都是同一个索引的部分的时候,表示mysql服务器将在存储引擎检索行后再进行过滤
Using temporary:表示MySQL需要使用临时表来存储结果集,常见于排序和分组查询
Using filesort:MySQL中无法利用索引完成的排序操作称为“文件排序”
Using join buffer:改值强调了在获取连接条件时没有使用索引,并且需要连接缓冲区来存储中间结果。如果出现了这个值,那应该注意,根据查询的具体情况可能需要添加索引来改进能。
Impossible where:这个值强调了where语句会导致没有符合条件的行。
Select tables optimized away:这个值意味着仅通过使用索引,优化器可能仅从聚合函数结果中返回一行
二、索引优化
对哪些字段建立索引呢?一般说来,索引应建立在那些将用于JOIN, WHERE判断和ORDER BY排序的字段上。尽量不要对数据库中某个含有大量重复的值的字段建立索引。
1、查看索引使用情况
Handler_read_rnd_next 的值高则意味着查询运行低效,并且应该建立索引补救。这个值的含义是在数据文件中读下一行的请求数。如果你正进行大量的表扫描,如果该值较高。通常说明表索引不正确或写入的查询没有利用索引。
mysql> show status like 'Handler_read%';
2、order by优化
基于索引的排序
MySQL的弱点之一是它的排序。虽然MySQL可以在1秒中查询大约15,000条记录,但由于MySQL在查询时最多只能使用一个索引。因此,如果WHERE条件已经占用了索引,那么在排序中就不使用索引了,这将大大降低查询的速度。我们可以看看如下的SQL语句:
SELECT * FROM SALES WHERE NAME = “name” ORDER BY SALE_DATE DESC;
在以上的SQL的WHERE子句中已经使用了NAME字段上的索引,因此,在对SALE_DATE进行排序时将不再使用索引。为了解决这个问题,我们可以对SALES表建立复合索引:
ALTER TABLE SALES DROP INDEX NAME, ADD INDEX (NAME,SALE_DATE)
这样再使用上述的SELECT语句进行查询时速度就会大副提升。但要注意,在使用这个方法时,要确保WHERE子句中没有排序字段,在上例中就是不能用SALE_DATE进行查询,否则虽然排序快了,但是SALE_DATE字段上没有单独的索引,因此查询又会慢下来。
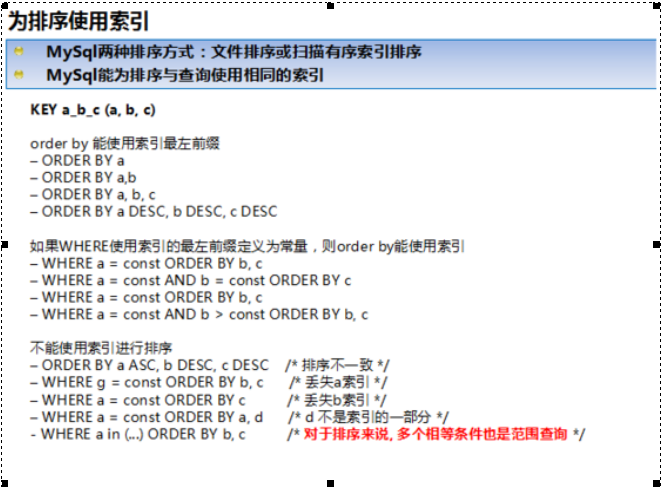
在某些情况中, MySQL可以使用一个索引来满足 ORDER BY子句,而不需要额外的排序。 where条件和order by使用相同的索引,并且order by 的顺序和索引顺序相 同,并且order by的字段都是升序或者都是降序。
下列sql可以使用索引。
SELECT * FROM t1 ORDER BY key_part1,key_part2,... ; SELECT * FROM t1 WHERE key_part1=1 ORDER BY key_part1 DESC, key_part2 DESC; SELECT * FROM t1 ORDER BY key_part1 DESC, key_part2 DESC;
但是以下情况不使用索引:
SELECT * FROM t1 ORDER BY key_part1 DESC, key_part2 ASC ; --order by 的字段混合 ASC 和 DESC SELECT * FROM t1 WHERE key2=constant ORDER BY key1 ; -- 用于查询行的关键字与 ORDER BY 中所使用的不相同 SELECT * FROM t1 ORDER BY key1, key2 ; -- 对不同的关键字使用 ORDER BY :
3、Group by优化
默认情况下, MySQL 排序所有 GROUP BY col1 , col2 , .... 。查询的方法如同在查询中指定 ORDER BY col1 , col2 , ... 。如果显式包括一个包含相同的列的 ORDER BY子句, MySQL 可以毫不减速地对它进行优化,尽管仍然进行排序。如果查询包括 GROUP BY 但你想要避免排序结果的消耗,你可以指定 ORDER BY NULL禁止排序。
例如 :
INSERT INTO foo SELECT a, COUNT(*) FROM bar GROUP BY a ORDER BY NULL;
4、OR优化
(1)、所有的or条件都必须是独立索引
(2)、使用union来替换or
比如:select id from t where num=10 or num=20
可改为:select id from t where num=10 union all select id from t where num=20
三、索引失效
下面操作会导致索引失效,引起全表扫描
1、应尽量避免在 where 子句中对字段进行 null 、not null值判断
不能用null作索引,任何包含null值的列都将不会被包含在索引中。即使索引有多列这样的情况下,只要这些列中有一列含有null,该列 就会从索引中排除。也就是说如果某列存在空值,即使对该列建索引也不会提高性能。 任何在where子句中使用is null或is not null的语句优化器是不允许使用索引的。
2、应尽量避免在 where 子句中使用不等于(!=或<>)操作符
3、应尽量避免在 where 子句中使用 or 来连接条件
在某些情况下,or条件可以避免全表扫描的。
(1).where 语句里面如果带有or条件, myisam表能用到索引, innodb不行。
(2).必须所有的or条件都必须是独立索引
4、in 和 not in 也要慎用,否则会导致全表扫描
如: select id from t where num in(1,2,3)
对于连续的数值,能用 between 就不要用 in 了:
Select id from t where num between 1 and 3
5、like以通配符开头('%abc...')
select id from t where name like '%abc%' 或者
select id from t where name like '%abc' 或者
若要提高效率,可以考虑全文检索。
而select id from t where name like 'abc%' 才用到索引
6、在索引上进行操作,比如计算、函数、参数等
select id from t where num=@num
可以改为强制查询使用索引: select id from t with(index(索引名)) where num=@num
select id from t where substring(name,1,3)='abc' --name
select id from t where datediff(day,createdate,'2005-11-30')=0--‘2005-11-30’
生成的id 应改为:
select id from t where name like 'abc%'
select id from t where createdate>='2005-11-30' and createdate<'2005-12-1'
7、字符串不加单引号
8、索引字段不是复合索引的前缀索引,不符合左前缀法则
如果索引了多列,就要遵从最左前缀法则,查询从索引的最左前列开始并不跳过索引中的列。在创建多列索引时,要根据业务需求,where子句中使用最频繁的一列放在最左边。
SELECT * FROM table WHERE a = 1 AND c = 3; // c不走索引
SELECT * FROM table WHERE a = 1 AND b < 2 AND c = 3; // c不走索引那么第一句的a=1 会走索引,c=3不走索引;
第二句的a=1 and b<2会走索引,c=3不走索引;
SELECT * FROM table WHERE a = 1 AND b = 2 AND c = 3;
或者
SELECT * FROM table WHERE a = 1 AND b = 2 AND c < 3;
的a、b、c都会走索引
四、参考:
- 《SQL优化大全》 地址:https://blog.csdn.net/hguisu/article/details/5731629
- 《MySQL优化大全》 地址:https://blog.csdn.net/hguisu/article/details/5713180
- 《MySQL高级-索引优化》 地址:https://www.cnblogs.com/zhaobingqing/p/7071331.html
- 《MySQL数据库慢–排查问题总结(整理自《抽丝剥茧之MySQL疑难杂症排查》叶金荣)》 地址:http://blog.51cto.com/corasql/190615
- 《MySQL Expalin详解》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号