

Go语言之闭包

认识闭包
首先来看一段代码:
1 package main
2
3 import (
4 "fmt"
5 )
6
7 func squares() func() int {
8 var x int
9 return func() int {
10 x++
11 return x * x
12 }
13 }
14
15 func main() {
16 f1 := squares()
17 f2 := squares()
18
19 fmt.Println("first call f1:", f1())
20 fmt.Println("second call f1:", f1())
21 fmt.Println("first call f2:", f2())
22 fmt.Println("second call f2:", f2())
23 }
调试结果是这样的:
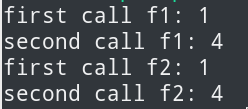
代码很简单,就是定义一个square函数,返回值类型是func() int,返回的这个函数就是一个闭包。
那么什么是闭包呢? 闭包是函数和它所引用的环境,也就是闭包=函数+引用环境。
匿名函数虽然没有定义x,但是它引用了他所在的环境(函数squares)中的变量x。f1跟f2引用的是不同的环境,在调用x++时修改的不是同一个x,因此两个函数的第一次输出都是1。函数squares每进入一次,就形成了一个新的环境,对应的闭包中,函数都是同一个函数,环境却是引用不同的环境。
我们在看一下上面的例子,发现变量x的生命周期不是由他的作用域所决定的,变量x在main函数中返回squares函数后依旧存在。变量x是函数squares中的局部变量,假设这个变量是在函数squares的栈中分配的,是不可以的。因为函数squares返回以后,对应的栈就失效了,squares返回的那个函数中变量i就引用一个失效的位置了。所以闭包的环境中引用的变量不能够在栈上分配。
在继续研究闭包的实现之前,先看一看Go的一个语言特性:
func f() *Cursor {
var c Cursor
c.X = 500
noinline()
return &c
}
Cursor是一个结构体,这种写法在C语言中是不允许的,因为变量c是在栈上分配的,当函数f返回后c的空间就失效了。但是,在Go语言规范中有说明,这种写法在Go语言中合法的。语言会自动地识别出这种情况并在堆上分配c的内存,而不是函数f的栈上。
为了验证这一点,可以观察函数f生成的汇编代码:
MOVQ $type."".Cursor+0(SB),(SP) // 取变量c的类型,也就是Cursor
PCDATA $0,$16
PCDATA $1,$0
CALL ,runtime.new(SB) // 调用new函数,相当于new(Cursor)
PCDATA $0,$-1
MOVQ 8(SP),AX // 取c.X的地址放到AX寄存器
MOVQ $500,(AX) // 将AX存放的内存地址的值赋为500
MOVQ AX,"".~r0+24(FP)
ADDQ $16,SP
识别出变量需要在堆上分配,是由编译器的一种叫escape analyze的技术实现的。如果输入命令:
go build --gcflags=-m main.go可以看到输出:
./main.go:20: moved to heap: c
./main.go:23: &c escapes to heap表示c逃逸了,被移到堆中。escape analyze可以分析出变量的作用范围,这是对垃圾回收很重要的一项技术。
其实,Go通过escape analyza识别出变量的作用域,在闭包环境中,引用的变量不是在栈上分配,而是在堆中分配。
返回闭包时并不是单纯的返回一个函数,而是返回一个结构体,记录下函数返回地址和引用的环境中的变量地址,即:
type Closure struct {
F func()()
i *int
}
闭包和普通函数调用的区别
看下面两段代码:
代码片段1:
package main
import (
"fmt"
)
func main() {
a := []int{1, 2, 3}
for _, value := range a {
fmt.Println(value)
defer p(value)
}
}
func p(value int) {
fmt.Println(value)
}
运行结果:
1 2 3 3 2 1
代码片段1就是普通的函数调用,每次调用func p时,完成 value的值复制,然后打印,此时 value值复制了3次,分别是1,2,3。由于defer是后进先出,所以执行变成3,2,1。
这里或许对输出结果感到有些意外,为什么正常输出123后,又输出321?搞清这点需要理解普通函数传参方式和defer
1、我们又知道,形参变量都是函数的局部变量,初始值由调用者提供的实参传递。而实参是按值传递的,即新辟内存拷贝变量值,函数接收到的是每个实参的副本(slice、map、函数、通道和指针是引用传递,注意区别 )。
2、下面是go官方关于defer的解释:
defer语句延迟执行一个函数,该函数被推迟到当包含它的程序返回时(包含它的函数 执行了return语句/运行到函数结尾自动返回/对应的goroutine panic)执行。
每次defer语句执行时,defer修饰的函数的返回值和参数取值会照常进行计算和保存,但是该函数不会执行。等到上一级函数返回前,会按照defer的声明顺序倒序执行全部defer的函数。defer的函数的任何返回值都会被丢弃。
基于以上两点解释,我们就比较清楚了,defer修饰的函数会将传入它的参数拷贝保存在自己的内存区域,等到函数返回时,才开始执行。又由于defer是先进后出的,所以最终打印结果是3,2,1。
代码片段2:
package main
import (
"fmt"
)
func main() {
a := []int{1, 2, 3}
for _, value := range a {
fmt.Println(value)
defer func() {
fmt.Println(value)
}()
}
}
运行结果:
1 2 3 3 3 3
再来理解代码片段2。由上面我们对defer的理解,函数返回时才开始执行func(),但为什么输出都是3呢?要搞清楚这个问题,还得理解for...range用法和闭包函数参数传递。
1、在Go的for…range循环中,Go始终使用值拷贝的方式代替被遍历的元素本身,简单来说,就是for…range中那个value,是一个值拷贝,而不是元素本身。也是说value是个局部变量,只是把元素赋值给该变量而已。
2、闭包里的非传递参数外部变量值是传引用的,也就是闭包是地址引用。在闭包函数里那个value就是外部非闭包函数自己的参数,所以是相当于引用了外部的变量。
有了以上两点的理解,再来理解代码2的结果就容易多了。闭包是通过地址引用来引用环境中的变量value,因此每次只是把value的地址拷贝了一份儿,就这样拷贝了三次。而执行到最后时value值为3,所以打印了3次value地址指向的值,所以是3,3,3。
参考
《闭包的实现》:https://tiancaiamao.gitbooks.io/go-internals/content/zh/03.6.html
《golang的闭包和普通函数调用区别》:https://studygolang.com/articles/356

 浙公网安备 33010602011771号
浙公网安备 33010602011771号