1.0、本章导读
文章导读: 作为导读文章,本文首先分析音视频通信中的三种常见架构(Mesh、SFU、MCU)的特点以及应用场景;其次明确本书重点讲解的架构以及内容的安排。所以,本文阅读建议:理解。
正文开始。
在工作中,我们使用更多的学习方式是“结果导向式学习”,也就是为了实现某些需求,先快速找开源代码或从博客粘贴代码组建起一个可运行demo的过程。如就拿咱们的这个音视频通信的来说,为了实现这个功能,在“结果导向”的理念下,通常的做法就是:搜索查阅相关的帖子、博客,找各种代码,可能是东平西凑,能找到一个完整的demo更好,先跑通demo,针对demo中的技术一点点的查阅资料。这种方法有什么问题吗?在很多紧急的情况下是可行的,比如项目临时有一个紧急的需求,需要加入音视频通信,因为是内网部署,不能使用互联网sdk,这种情况下去完整的读一本书不现实,最好先快速拼凑出一个demo出来,完整的知识体系并不是最重要的,“应付”完需求才是关键,这种博客式的学习方式带来的效果是:“见效”快、基础薄,知识不成体系。与之相对应的就是稳扎稳打的学习,虽然耗时,但是付出与收获是正比,学习出来的效果相对牢固。本书推崇的学习方式属于“结果导向式学习”加“稳扎稳打式学习”的结合体,具体表现为凡是涉及实操的章节,必须得到结果,需要跑通的案例demo不能落下,本书不能成为一本由各种“废话+乱代码”拼凑的书籍,而是要成为读者在音视频通信技术学习路上的“指引宝典”。
本文首先要构建起整本书的技术目标,同时向读者明确本章的知识,最后把本章知识结合到本书的总体知识架构中。按照这种方式,每学完一章,读者的对应知识架构就充实一些,直到最后的完整;
本书所讲的内容是webrtc技术在实时音视频直播场景中的应用,如果你之前没有了解过webrtc也没有关系,在本篇文章中你只需要知道webrtc是谷歌的一个可以在web环境中(浏览器)以JavaScript实现高质量、高可靠音视频应用的技术即可, 接下来我们来了解下本书的技术目标。
在实际的应用场景中,音视频的通信场景大体可以分为这几种: ①、一对一的实时音视频互动,如微信电话,在webrtc技术规范中,通信方式推荐以P2P为主,即通信双方的音视频流数据直接点到点传输,无需经过服务端程序的中转,网络拓扑图如下图1.0.1。
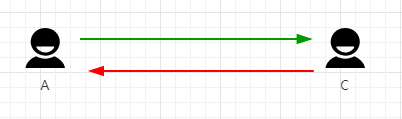
图 1.0.1( 两端p2p通信网络拓扑图)
这种p2p模式的有优点:无需服务端中转,服务器的开销低;传输质量好(传输质量依赖客户端自身的带宽情况);缺点是端结构简单。如果再有第三个人加入进来群聊,则拓扑图如下图1.0.2所示。
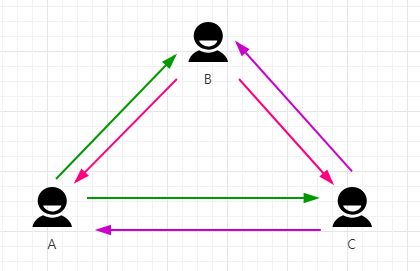
图 1.0.2 (三人p2p拓扑图)
两端通信,每端需要维护2个连接,一个上行一个下行(图1.0.1);当三端通信时, 每个端需要维护4个连接, 两个上行,两个下行(图1.0.2)。 以此类推,以这种完全P2P的模式下通信,在人数较少时比较不错,但是人数较多时就不太适合,每个端要维护的连接数剧增,带宽资源消耗大,而且每个连接产生的音视频数据都需要编解码,还得考虑编解码的CPU消耗,每个端的网络资源和CPU资源消耗较多。这种以P2P为主的通信模式我们称之为Mesh。优点够明显,缺点也不可忽略。在实际的场景应用中,该模式可以支持4到6人。
Mesh架构在人数较少的通信场景中表现良好,但应对多人的场景就比较吃力,为了支持多人的场景,如人数较多的视频群聊/视频会议,于是演化出新得架构——SFU,如下图1.0.3所示。

图 1.0.3(SFU 架构)
在SFU架构中,音视频发送方只需维护一个上行连接,由SFU服务器自行分发流数据到对应的接收端;如上图中,A向B和C发送数据,无需单独一个一个发,而是统一发到SFU服务器即可,较Mesh架构来说,在发送端节约了上行的资源。但是在接收端,即下行连接还是没有解决,有N个发送端就有N-1(不包含自己,自己看自己的视频无需网络传输)个下行连接,如下图1.0.4所示。
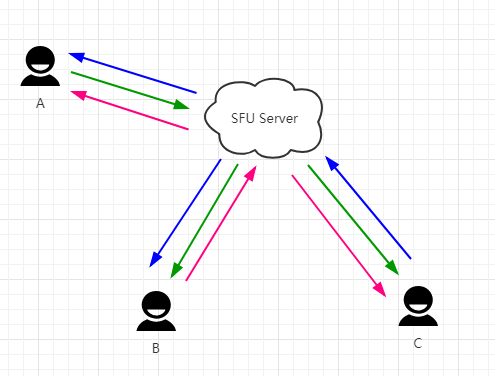
图 1.0.4 (SFU 架构)
总体来讲,SFU架构较Mesh来讲,节省了发送端的上行连接,带来的代价就是部署SFU服务,SFU服务只做转发,不涉及编解码,所以服务端的压力较小,在多人的同时通信中推荐使用 。架构在进一步演化,能否上行和下行都只有一个连接呢?有,这种架构称之为MCU架构,如下图1.0.5所示。
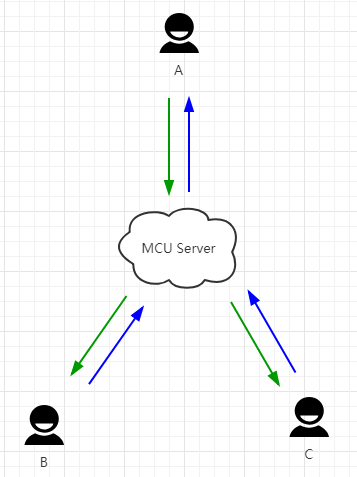
图 1.0.5 (MCU 模式)
在MCU架构中,每个端只需要上行下行连接各一路流,编解码以及合流(因为每个端只有一个下行连接,但这个连接里含有多个发送端的流,所以需要合起来传输)由MCU Server来承担,虽然从带宽上解决了客户端问题,但是服务器的压力很大,这种模式也就是传统的视频会议的架构。
综合三种架构,我们最终推荐SFU+Mesh 为折中的方案,本书先要解决6人以内的音视频通信问题,再来解决我更多人的通信问题,在往后的内容中,均以Mesh架构为主,讲解并实战webrtc的各类API,为后续实战项目以及开发高并发音视频服务器打下基础基础(项目实战和高并发的内容在单独的书籍中,且会完整的讲到SFU架构,读者可以关注我的微信公众号“晨叔周刊”联系到我,获取相关书籍的资料),下图就是本书要实现的目标,如图1.0.6所示。

图 1.0.6 (通信效果图 )
上图1.0.6中,用户A和B要实现简单的“图文”通信,按照传统的C/S模式是非常简单的,在A、B中间,搭建一个服务器转发消息即可。但如果要能音视频通信,并且还是p2p通信(A和B直接通信),之间涉及的技术细节就复杂了,总体需要解决问题有这么几块:第一、 音视频处理(音视频流的采集,优化处理(图形增强,音频降噪),编解码,播放);第二、网络传输(流数据、文本数据、其他二进制数据)。本书的内容以实现A和B的通信为目标,循序渐进的展开内容。
首先来看音视频处理,处理音视频之前,首先考虑采集, 在web中(浏览器环境)如何采集音视频,采集到音视频数据后如何播放,如何存储,每个浏览器兼容性不一样,如何做好这些适配等一系列的问题,在第二章中重点讲解以及实战。采集完音视频数据之后,接下来,要考虑传输的问题,因为只考虑少数人的实时通信,所以传输架构采用Mesh,即以P2P通信为主,服务器中转为辅。p2p可以带来较好的通信质量,但是p2p穿越并不总是成功, 于是服务器中转是备选方法,那如何来实现一个完备的通信解决方案?从第三章到第十章,占据本书的了大部分的篇幅都在讲解通信相关的内容。第三章讲解计算机网络的基本内容,如网络拓扑、NAT、P2P穿越、STUN协议、TURN协议、ICE框架;系统的掌握这些网络知识之后,为后面的实战章节打下基础。第四章——Socket通信,如上图1.0.6所示,信令服务器是在音视频通信中占据不可缺少的位置,可以说缺少了信令服务器,音视频通信链路都无法建立起来,然而开发信令服务需要运用到Socket通信,本章旨在梳理好读者的socket通信基础,为后续实战信令服务器打下基础。第五章——抓包工具的使用,这章是工具介绍,在webrtc的通信中将会应用到很多的协议,如STUNS协议、TURN协议、SDP协议等,为了更好的理解和分析这些协议,我们要会抓取和分析数据包。第六章——媒体协商。所谓媒体协商就是通信通信双方“协商”并“创建”通信链路的过程,在图1.0.6中表现为line 1、line2、line3、line 5的部分, 本章重点内容有:媒体协商的重要方法、协商状态、重要事件等,学完本章之后,你将完整的理解webrtc的通信过程,如再配合信令服务器,整个webrtc的通信链路就可以打通,当然,本章暂时不会加入信令服务器的使用,因为还差一些重要的概念没有讲完,且看下一章。第七章、第八章、可以合为一部分内容来看,总的来讲就是图1.0.6总的STUN/TURN服务器部分,学完这两章,在第八章的案例中,我们加入信令服务,至此,如图1.0.6所示的通信架构就已经构建完毕,webrtc中的核心功能讲完。第九章——媒体控制,属于webrtc的进阶内容,如流量传输速率的控制,视频特效的实现:如视频滤镜等。第十章——非音视频数据传输,完整的通信应用不单只有音视频媒体数据,还有其他类型数据,如文本,图片、文件等,借助webrtc的传输通道,我们可以轻松实现这些功能。第十一章——WebRTC实时传输协议的讲解,属于进阶内容,读完本章内容,webrtc的知识体系基本构建完毕。第十二章是本书的总结,这里不再多讲。
考虑到一个循序渐进的学习过程,本书的定位就是讲解核心技术,所以整本书不涉及过多项目实战开发,特别是Android、IOS 端,为了给读者一个完整的学习体验,实战的内容放在下一本书来讲解——《搞定WebRTC实时音视频直播技术(项目实战篇)》,在这本书里,我们实战三端通信:PC(web)、Android(原生)、IOS(原生),希望获得实战经验、以及整合webrtc技术体系到实战场景的同学,我极力推荐关注这本书。
本文内容就到这里,祝学习愉快。
最后,附上本书指定交流微信公众号——“晨叔周刊”,一起讨论吧。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号