计算机体系结构 - 课前展示 - 多核时代与墙与墙与墙
多核时代与超级计算机
随着计算机技术的发展,毫无疑问现代计算机的处理速度和计算能力也越来越强。
然而从2005年起,单核的 CPU 性能就没有显著的提升了(见下图)。
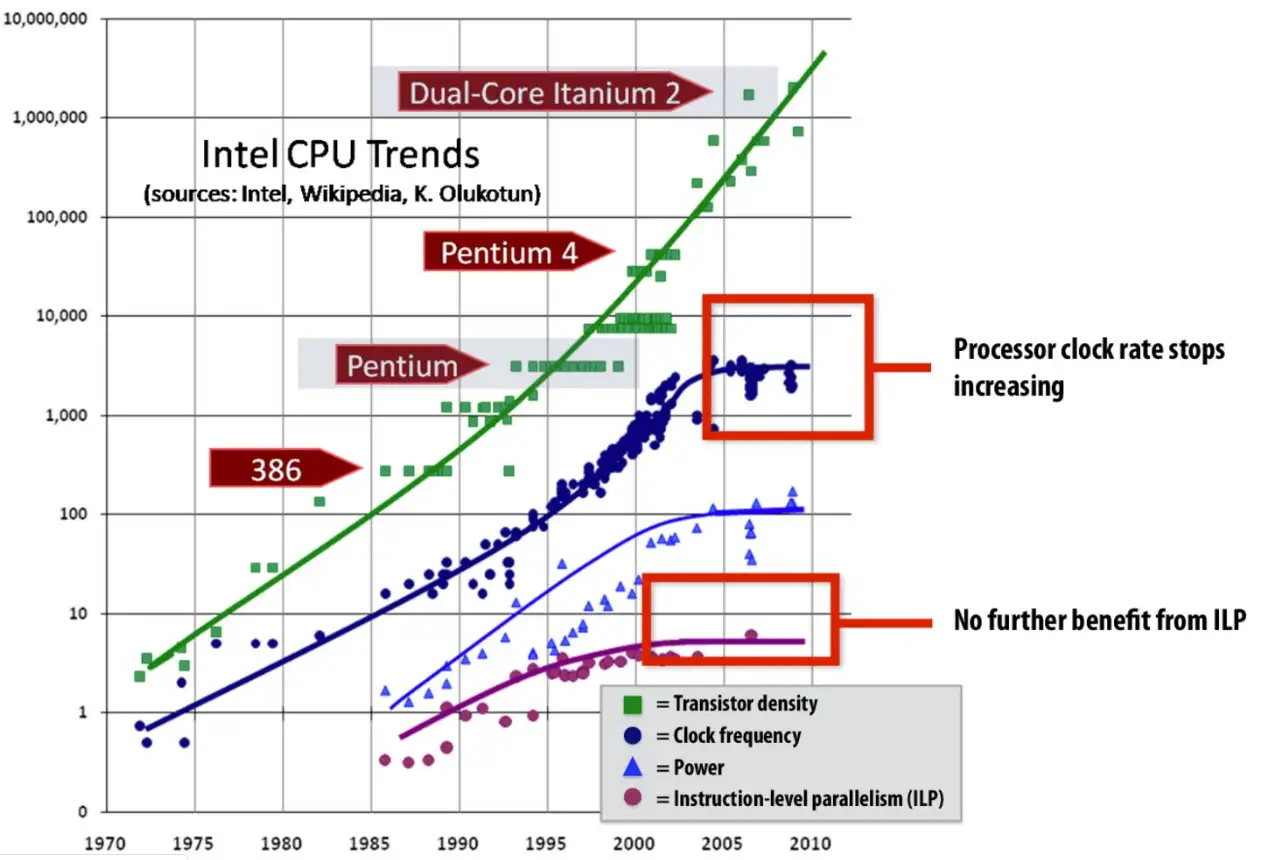
人们发现单纯的提高单核 CPU 的性能无论从潜力上还是功耗上都是不合算的。
并行硬件的发展,多年以前要用许多台电脑才能并行处理的“大数据”问题,现在大多都可以用一台多核电脑解决了。超级计算机则将大量的处理器集中构成机群,计算峰值速度可达每秒百亿亿次级。
相比于单个 CPU 的性能,并行处理体系结构设计才是最重要的关键技术,单纯堆砌 CPU 数量,反而会降低整机效率,无法提升整机性能。困扰机群大规模扩展主要存在如下关键问题:
内存墙(Memory Wall)
系统结构的失衡问题,存储器性能与处理器性能差距越来越大,本地带宽及延迟和全局带宽及延迟发展不一致所造成的差距形成了阻碍性能提升的"内存墙"(Memory Wall);
是冯诺伊曼结构的固有问题。冯诺伊曼结构是个 cpu 和主存储器的通信结构,一个通信过程时延可分为处理时延,传播时延,排队时延,三者共同构筑了内存墙。
- 处理时延:内存墙最主要的构成部分。cpu cache 采用双稳态触发器构建,速度快容量小成本高;主存采用电容存储器构建,速度慢成本低容量大;了不同的工艺。两者性能差距过大,造成读主存时产生较大处理时延。
- 传播时延:向 cpu 传输数据的速度依赖于内存总线带宽,而总线宽度和引脚数量直接关联,受工艺影响,内存总线带宽难以快速增长。
- 排队时延:多核 cpu 场景下对任务调度的拥塞控制。

大容量意味着廉价和共享;构建多核心架构的分层存储体系,大大提升了性价比;共享资源,就一定会出现拥塞,而拥塞控制的代价还是时间;只是随着 CPU 核心的增多,拥塞控制的的成本越来越高,分层储存体系的收益也随之越来越低。
AI训练的计算量每年都在大幅增长,最近有研究指出,AI训练未来的瓶颈不是算力,而是GPU内存。如下图所示,Transformer模型中的参数数量(红色)呈现出2年240倍的超指数增长,而单个GPU内存(绿色)仅以每2年2倍的速度扩大。
不能仅依靠将训练扩展到多个AI加速器,使用分布式内存以提高有限内存容量和带宽。神经网络加速器之间移动数据的通信瓶颈,甚至比芯片上的数据移动还慢且低效。仅在很少的通信和数据传输的情况下,横向扩展才适用于计算密集型问题。
利用高速缓存技术和并行处理技术来尽量降低“内存墙”的影响目前仍然是有效的方法。
- 内存等待时间屏蔽技术:将处理器可能访问的数据和程序代码预先保存到高速缓存中,尽可能地减少处理器对内存的直接访问,而是从高速的缓存中获取数据,就是一种典型的内存等待时间屏蔽(Latency Hiding)技术。这种基于缓存机制的技术一直是降低“内存墙”影响的常规方法。
- 硬件支持的并行处理技术:虽然由硬件支持的多线程、乱序执行等并行处理技术并不能直接解决“内存墙”问题,但多线程和乱序执行的并行处理机制,能够更有效地减少在处理任务过程中处理器资源被闲置的情况,当处理器处理大量任务时其“资源不被闲置”所产生的累积效应,就能使吞吐量明显增加,因此整体的处理效率就相应地有所提升,从而在一定程度上屏蔽了“内存墙”的影响。
不过最根本的解决方案是放弃冯·诺依曼的“存算分离”结构,采用“存算一体”的体系结构,直接在存储单元中读写并处理数据。并在此过程中采用延时更低的新存储方式,已有大量实验性的芯片诞生,是破解内存墙的关键。
可靠性墙(Availability Wall)
指由于系统中硬件故障或软件错误导致系统不可靠的情况。对高性能计算机系统来说,可靠性也是其挑战之一,当其扩展到成万或十万颗之多 CPU 以及几百Terabytes内存时,我们如何保障硬件系统的可靠性,同时在这样大规模的系统运行中,软件错误也很难避免。
为了解决这个问题,需要有可靠的内存和处理器,并通过合理的策略与技术以加强软件与硬件的容错率。
软件方面,设置检查点:
- 第一种方法,系统级检查点,只需要用户指定检查点间隔,而无需额外的程序员工作。
- 第二种方法,应用程序级检查点,要求用户决定检查点的位置和内容。
硬件方面,主要是通过冗余或复制资源来实现的。
- 其中包括物理上(RAIDed disks and backup servers),还有信息智能方面(ECCmemory,parity memory 奇偶校验内存,data replication),都可以实现增大容错率。
- 在数据复制中,将数据从远程节点复制到本地节点,以便进行本地读取而不是远程读取,从而改善整个系统的性能。由于数据冗余,数据复制还可以提高通信的可靠性,但代价是额外的存储空间。
可编程性墙(Programmabilitywall)
是指在计算机体系结构的设计和开发中,随着硬件复杂性增加(如多核处理器、异构计算等),导致开发者难以充分利用硬件性能的瓶颈问题。
特别是多核、超大规模并行系统以及可重构架构(如 FPGA)的广泛应用,虽然硬件计算能力越来越强,但是开发能够充分利用这些硬件资源的高效并行软件变得越来越困难。
并行编程涉及复杂的线程管理、同步、锁机制,需要考虑合理的负载均衡和任务调度、解决数据争用与同步,开发难度和错误率都很高;虽然有一些并行编程框架(如 OpenMP、CUDA、OpenCL 等)和编译器优化技术,但它们并不能自动高效地利用所有硬件资源,开发者仍然需要手动进行大量优化。
以排序算法为例,如选择排序,冒泡排序是完全串行化的,无法被直接应用到多核并行计算中。
一个简单的并行排序算法为:Cube sort。若有 \(n\) 个数据项且有 \(p\) 个处理单元,考虑将待排序序列划分为 \(p\) 个长度为 \(\frac{n}{p}\) 子序列,并将对每个子序列的排序过程交付给对应的处理单元进行,再考虑对所有有序的子序列进行归并。若每个处理单元内使用 \(O(n\log n)\) 级别的排序算法,则并行下总时间复杂度为:
当有 \(n\) 个处理单元时,有理论上的最佳并行时间复杂度为:
实际情况:由于并行系统中的通信开销和负载不均衡(内存墙问题),实际性能通常不会达到理想上限,但在大规模并行系统中,Cube Sort 的并行时间复杂度仍然可以接近理论时间复杂度。
参考:
- 一文搞懂让你懵圈的超级计算机:真的不是堆CPU就行-CSDN博客
- 从存储器原理看 cpu 内存墙的本质 - 知乎
- 大算力,内存墙与功耗墙分析 - 知乎
- 多核时代与并行算法 - 知乎
- 后摩尔时代芯片发展的四堵墙,是噩梦还是机遇?!
- 打破内存墙 - 半导体行业观察
- AI训练的最大障碍不是算力,而是“内存墙” - 知乎
- 高性能计算 性能与效能孰重孰轻?-DOIT
- 杨学军:如何突破E级计算的五堵墙?-DOIT
- 并行算法科普向 系列之三:归并与归并排序,过滤与快速排序 - 知乎
- Robert Cypher, Jorge L.C Sanz,Cubesort: A parallel algorithm for sorting N data items with S-sorters,Journal of Algorithms,Volume 13, Issue 2,1992,Pages 211-234,ISSN 0196-6774
