Solution -「CF 848D」Shake It!
Link.
初始有一个有向图 ,,,一次操作定义为取任意 ,设 为一个新结点,则令 ,。现进行 次操作,求最终有多少个本质不同的 ,满足 ,答案对 取模。
与 本质相同:存在一个 均为不动点的 ,使得 作用于 后有 。
。
灵性的 DP 神题。
我们称一次选取 边的操作为对 的扩展。
令 表示 次操作使原图的最大流为 的方案数,可见 为答案;同时令 为其第二维后缀和,即 。
然后不难发现完全转移不了。 再令 表示对于任意边 , 次操作,扩展且仅扩展 一次,使得 到 的最大流增加 (变为 )的方案数;同理定义 。注意 与 的区别,例如对于下图中的 <绿点, 红点>:
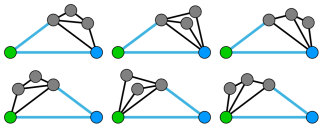
上图的方案都是 所包含的,而
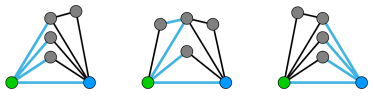
都不是 所包含的,因为它们都扩展了 <绿点, 蓝点> 这条边多于一次。
接着考虑 与 的关系,有
即,先用一次操作扩展初始的 ,此后 都成为 的子问题,只要使两者的最大流同时不小于 ,则 到 增加的流也不小于 。并且由于 在映射中不动,所有方案均本质不同。
难点在于对 的转移。我们要选取若干个 作用在初始的 ,形成最终的图 ,同时保证方案本质不同。即,找到 ,使得 且 ( 到 本身就有 的流)。那么,在转移过程中,仅需考虑在选择方案的末尾加入 个当前的 , 个 内部的方案用隔板法可知为 ,再乘上原有方案数即可。因为不同 之间钦定无序,相同 之间隔板法保证无序,故方案无序,即本质不同。
到此,复杂度 ,瓶颈在于枚举“ 个当前的 ”。
代码中 f[][] 对应 ,g[][] 对应 ,h[][] 对应稍作下标移动的 。
/* Clearink */
#include <cstdio>
#define rep( i, l, r ) for ( int i = l, repEnd##i = r; i <= repEnd##i; ++i )
#define per( i, r, l ) for ( int i = r, repEnd##i = l; i >= repEnd##i; --i )
const int MAXN = 50, MOD = 1e9 + 7;
int n, m, ifac[MAXN + 5];
inline int imin( const int a, const int b ) { return a < b ? a : b; }
inline int mul( const long long a, const int b ) { return a * b % MOD; }
inline int sub( int a, const int b ) { return ( a -= b ) < 0 ? a + MOD : a; }
inline void subeq( int& a, const int b ) { ( a -= b ) < 0 && ( a += MOD ); }
inline int add( int a, const int b ) { return ( a += b ) < MOD ? a : a - MOD; }
inline void addeq( int& a, const int b ) { ( a += b ) >= MOD && ( a -= MOD ); }
inline int mpow( int a, int b ) {
int ret = 1;
for ( ; b; a = mul( a, a ), b >>= 1 ) ret = mul( ret, b & 1 ? a : 1 );
return ret;
}
inline void init() {
int& t = ifac[MAXN] = 1;
rep ( i, 1, MAXN ) t = mul( t, i );
t = mpow( t, MOD - 2 );
per ( i, MAXN - 1, 0 ) ifac[i] = mul( ifac[i + 1], i + 1 );
}
int f[MAXN + 5][MAXN + 5], g[MAXN + 5][MAXN + 5], h[MAXN + 5][MAXN + 5];
int main() {
init();
scanf( "%d %d", &n, &m );
f[0][1] = h[0][0] = 1;
rep ( i, 1, n ) {
rep ( j, 1, i + 1 ) {
int& crg = g[i][j];
rep ( k, 0, i - 1 ) {
addeq( crg, mul( f[k][j], f[i - k - 1][j] ) );
}
}
rep ( j, 1, i + 1 ) {
int gv = sub( g[i][j], g[i][j + 1] );
per ( a, n, 0 ) per ( b, n + 1, 0 ) {
int crh = 0;
for ( int k = 0, si = 0, sj = 0, up = 1;
si <= a && sj <= b; ++k, si += i, sj += j ) {
addeq( crh, mul( h[a - si][b - sj], mul( up, ifac[k] ) ) );
up = mul( up, add( gv, k ) );
}
h[a][b] = crh;
}
}
per ( j, i + 1, 1 ) {
f[i][j] = add( h[i][j - 1], f[i][j + 1] );
}
}
printf( "%d\n", sub( f[n][m], f[n][m + 1] ) );
return 0;
}


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 25岁的心里话
· 按钮权限的设计及实现