

Java实现的二叉堆以及堆排序详解
一、前言
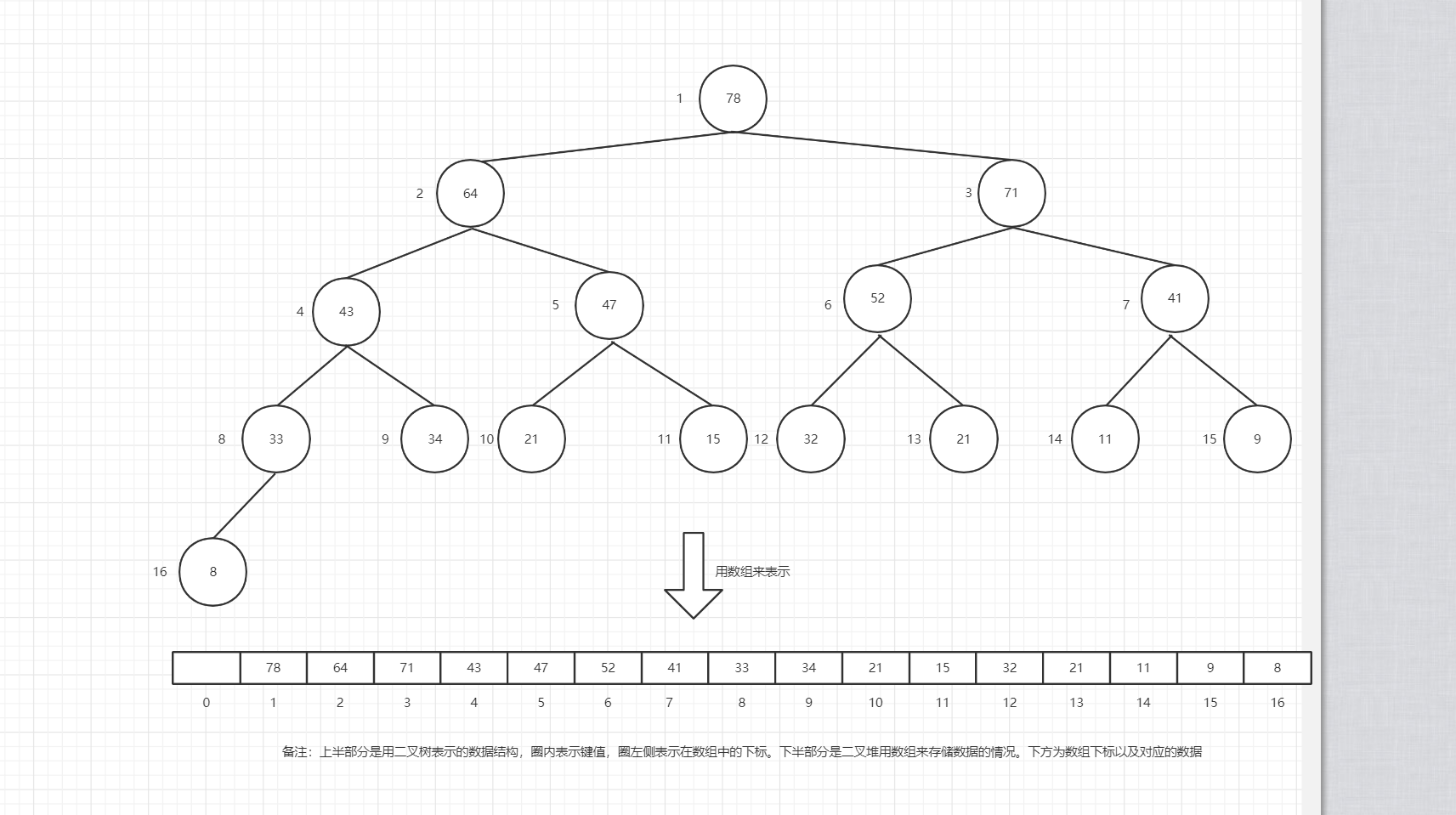
二叉堆是一个特殊的堆,其本质是一棵完全二叉树,可用数组来存储数据,如果根节点在数组的下标位置为1,那么当前节点n的左子节点为2n,有子节点在数组中的下标位置为2n+1。二叉堆类型分为最大堆(大顶堆)和最小堆(小顶堆),其分类是根据父节点和子节点的大小来决定的,在二叉堆中父节点总是大于或等于子节点,该二叉堆成为最大堆,相反地称之为最小堆。因此,最大堆父节点键值大于或等于子节点,最小堆父节点键值小于或等于子节点。根据二叉堆的特点,二叉堆可以用来实现排序、有限队列等。堆排序就是利用二叉堆的特性来实现的。二叉堆数据结构如下:
二、相关概念
(一)、树
树是一种重要的非线性数据结构,直观地看,它是数据元素(在树中称为结点)按分支关系组织起来的结构,很象自然界中的树那样。一棵树(tree)是由n(n>0)个元素组成的有限集合,其中:
(二)、二叉树
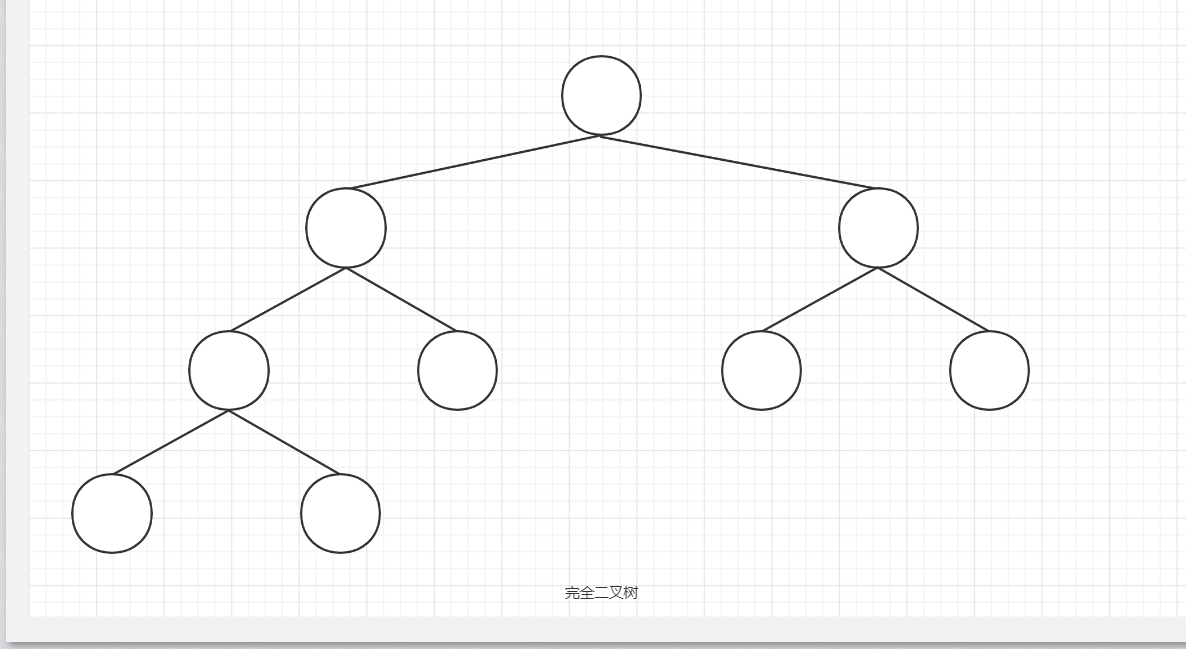
1、完全二叉树
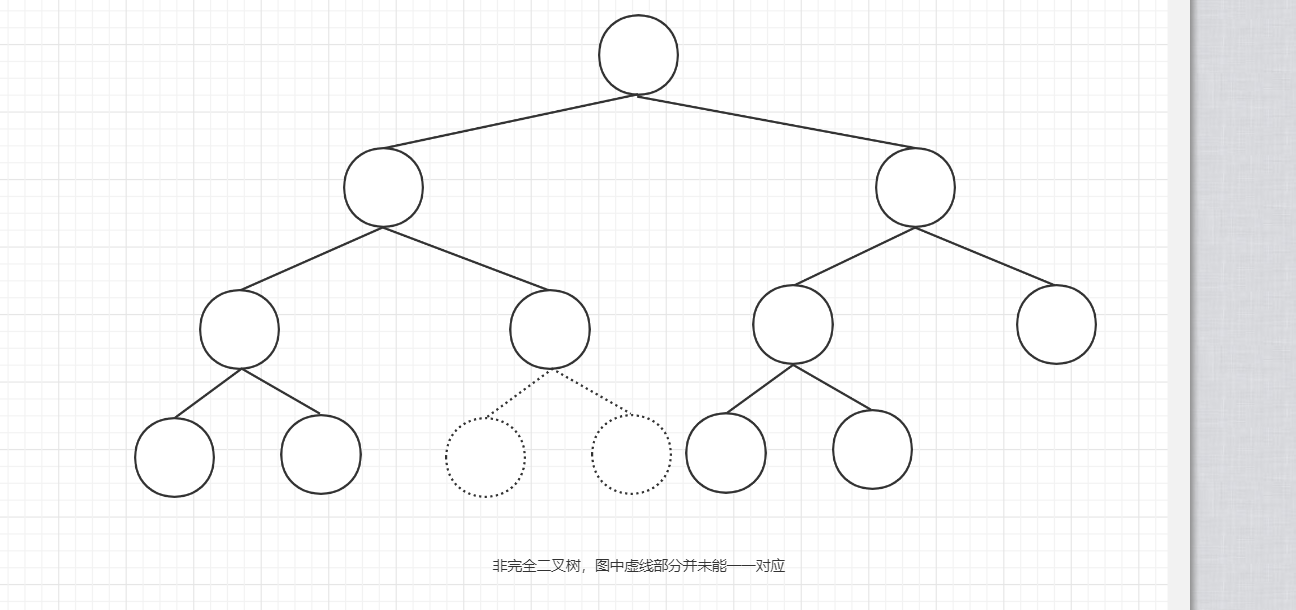
非完全二叉树
三、二叉堆插入节点和删除节点
(一)、插入节点
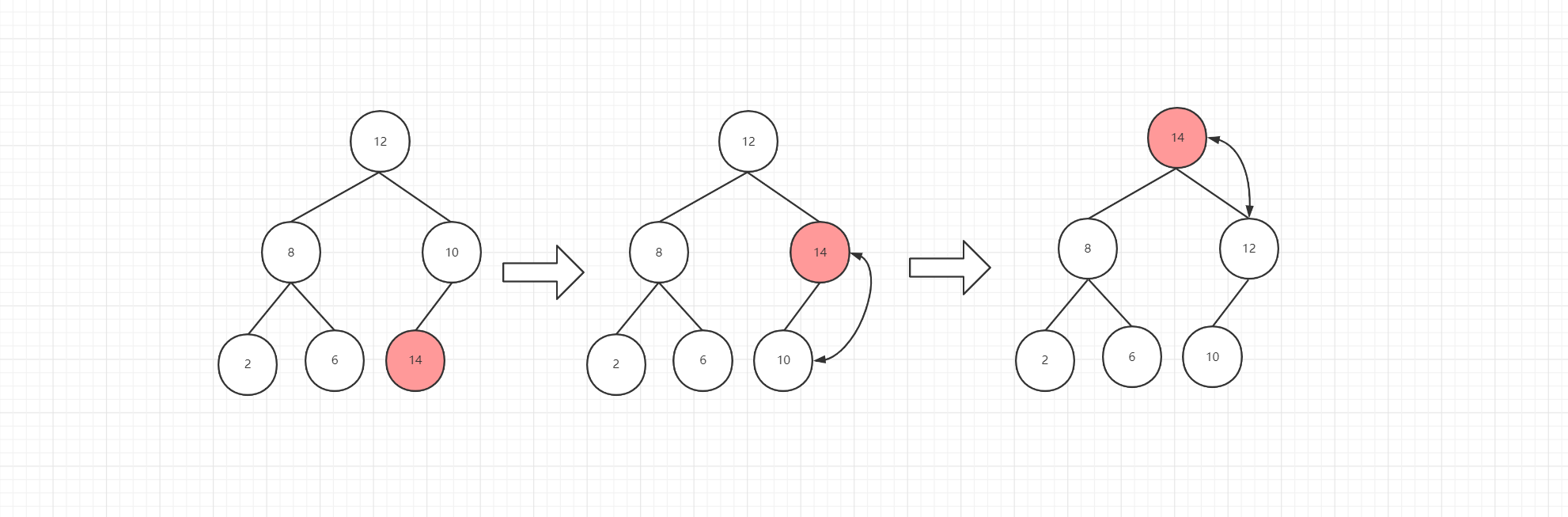
思路:因为二叉堆是用数组来存储数据的,所以每次插入节点时,实际是往数组数据尾部增加数据。但是,如果直接往尾部放数据,有可能破坏【父节点键值大于或等于子节点】的特性,因此,每次插入数据时都需要将二叉堆从新堆化的操作。堆化过程就是插入节点和父节的键值进行比较,如果父节点键值小于插入节点,则需要将两个节点进行交换,然后继续向上比较,直至父节点不小于插入节点或到达根节点。流程图如下:
代码实现如下:
/**
* 插入节点
* @param value 键值
* @return 成功或失败
*/
public boolean put(int value) {
/**
* 数组已满
*/
if (size > capacity) {
return false;
}
//直接将新节点插入到数据尾部
data[size] = value;
//插入节点后不满足二叉堆特性,需要重新堆化
maxHeapify(size++);
return true;
}
/**
* 大顶堆堆化
* @param pos 堆化的位置
*/
private void maxHeapify(int pos) {
/**
* parent 堆化位置的父节点;计算公式:父节点=子节点*2
* 向上堆化过程
*/
for (int parent = pos >> 1;parent > 0 && data[parent] < data[pos];pos = parent,parent = parent >> 1) {
swap(parent,pos);
}
}
/**
* 数组数据交换
* @param i 下标
* @param j 下标
*/
private void swap(int i,int j) {
int tmp = data[i];
data[i] = data[j];
data[j] = tmp;
}
测试结果如下: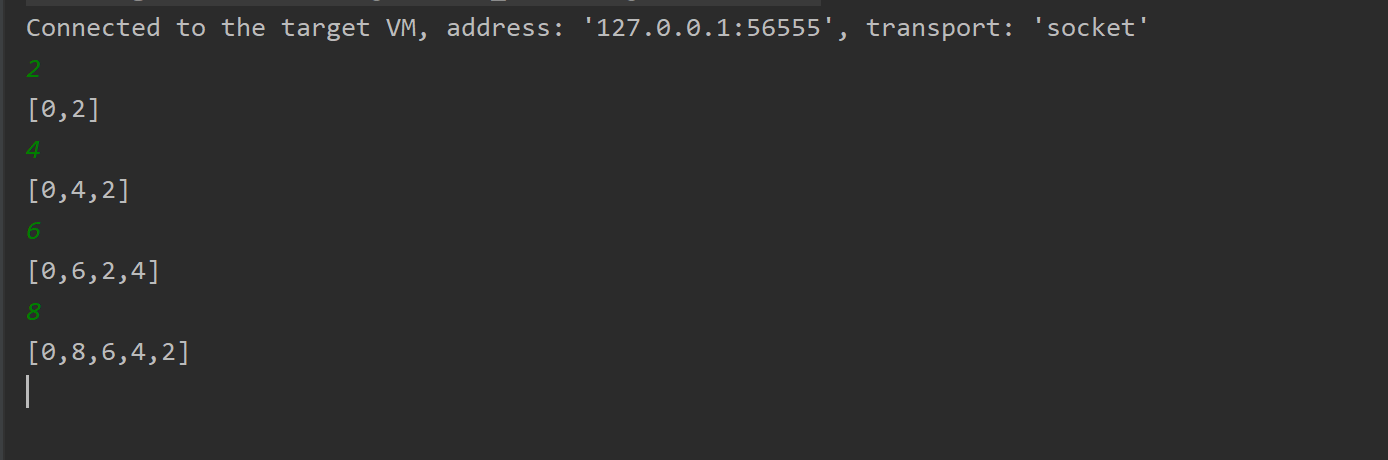
(二)、删除节点
删除节点主要用于堆排序的功能,因为每次删除节点时都是删除堆顶节点(即最大值或最小值),当整个二叉堆删除完成就可以得到一个有序的数组或列表。堆删除节点一般都是删除根节点,根节点被删除后该树就不满足二叉堆的特性,所以需要重新调整堆,使之成为一个真正的二叉堆。调整堆结构有多种方式,我这里说的是一种比较简便,高效的方式。大致的思路:将堆顶节点和最后一个节点交换,然后删除最后一个节点。交换节点键值后就不满足二叉堆的特性了,所以需要重新调整。根节点为父节点,与两个子节点键值进行比较,找到键值最大的节点后交换父节点和该节点的位置。位置交换后以最大值所在节点看作父节点,继续与子节点比较。当父节点均大于子节点或到达叶子节点时,即完成堆化过程。流程图如下: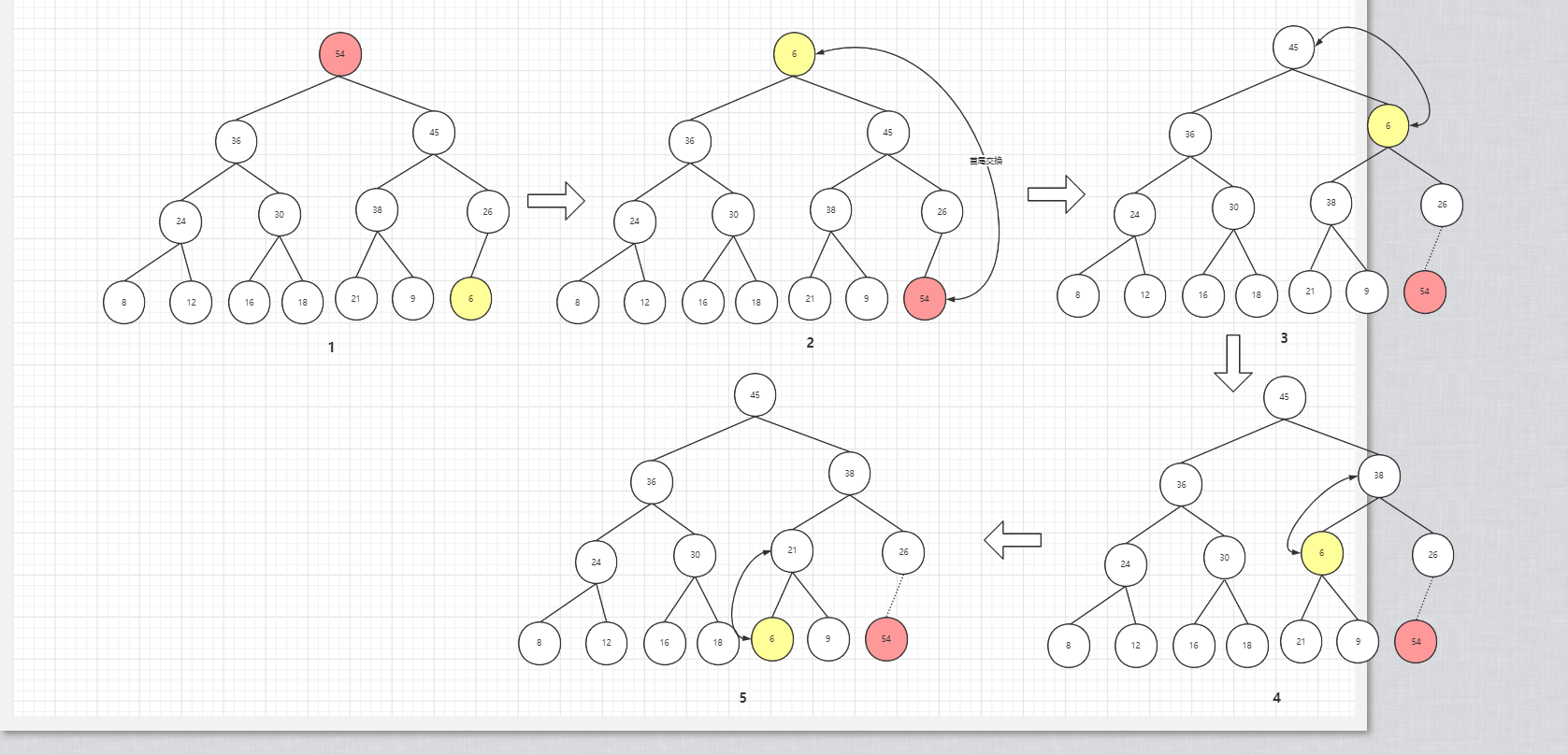
通过上面的4个步骤后就可以将堆顶元删除掉。具体代码实现如下:
/**
* 删除元素
* @return
*/
public int remove() {
int max = data[1];
if (size < 1) {
return -1;
}
swap(1,size);
size--;
shiftDown(1);
return max;
}
/**
* 自上而下重新调整二叉堆
* @param pos 开始调整位置
*/
private void shiftDown(int pos) {
int left = pos << 1;
int right = left + 1;
int maxPos = pos;
if (left <= size && data[left] > data[maxPos]) {
maxPos = left;
}
if (right <= size && data[right] > data[maxPos]) {
maxPos = right;
}
if (pos == maxPos) {
return;
}
swap(pos,maxPos);
shiftDown(maxPos);
}
测试结果:
public static void main(String[] args) {
Heap heap = new Heap(5);
Scanner scanner = new Scanner(System.in);
while (scanner.hasNext()) {
String next = scanner.next();
if (next.equalsIgnoreCase("r")) {
heap.remove();
}else {
heap.put(Integer.parseInt(next));
}
System.out.println(heap.toString());
}
}
//打印结果
1
[1]
2
[2,1]
3
[3,1,2]
4
[4,3,2,1]
5
[5,4,2,1,3]
r
[4,3,2,1]
r
[3,1,2]
r
[2,1]
r
[1]
r
[]
完成代码:
/**
* @className: Heap
* @description: 堆
* @author: rainple
* @create: 2020-09-01 15:39
**/
public class Heap {
/**
* 数组容量
*/
private int capacity;
/**
* 数据大小
*/
private int size;
/**
* 数据
*/
private int[] data;
public Heap(int capacity) {
if (capacity <= 0) {
throw new IllegalArgumentException("参数非法");
}
this.capacity = capacity;
data = new int[capacity + 1];
}
/**
* 插入节点
* @param value 键值
* @return 成功或失败
*/
public boolean put(int value) {
/**
* 数组已满
*/
if (size + 1 > capacity) {
return false;
}
//直接将新节点插入到数据尾部
data[++size] = value;
//插入节点后不满足二叉堆特性,需要重新堆化
maxHeapify(size);
return true;
}
/**
* 大顶堆堆化
* @param pos 堆化的位置
*/
private void maxHeapify(int pos) {
/**
* parent 堆化位置的父节点;计算公式:父节点=子节点*2
* 向上堆化过程
*/
for (int parent = pos >> 1;parent > 0 && data[parent] < data[pos];pos = parent,parent = parent >> 1) {
swap(parent,pos);
}
}
/**
* 删除元素
* @return
*/
public int remove() {
int max = data[1];
if (size < 1) {
return -1;
}
swap(1,size);
size--;
shiftDown(1);
return max;
}
/**
* 自上而下重新调整二叉堆
* @param pos 开始调整位置
*/
private void shiftDown(int pos) {
int left = pos << 1;
int right = left + 1;
int maxPos = pos;
if (left <= size && data[left] > data[maxPos]) {
maxPos = left;
}
if (right <= size && data[right] > data[maxPos]) {
maxPos = right;
}
if (pos == maxPos) {
return;
}
swap(pos,maxPos);
shiftDown(maxPos);
}
/**
* 数组数据交换
* @param i 下标
* @param j 下标
*/
private void swap(int i,int j) {
int tmp = data[i];
data[i] = data[j];
data[j] = tmp;
}
@Override
public String toString() {
if (size == 0) {
return "[]";
}
StringBuilder builder = new StringBuilder("[");
for (int i = 1; i < size + 1; i++) {
builder.append(data[i]).append(",");
}
return builder.deleteCharAt(builder.length() - 1).append("]").toString();
}
}
四、堆排序
(一)、算法实现
堆排序是利用了堆这种数据结构的特性而设计出来的高效的排序算法。算法实现也并不是很难,排序的过程就是将堆顶元素与最后一个元素交换的过程,每次交换后都需要进行一次堆结构使之成为一颗新的二叉堆。其实,排序的过程类似与我们上面讲到的删除节点的过程,每进行一次删除操作,都会将根节点(最大值或最小值)放在当前堆对应的数组的最后一个位置,当所有节点都进行一次删除后即可得到一个有序的数组,如果大顶堆最后数组的正序排序,小顶堆则是倒叙排序。下面我使用图例来演示排序的过程,因为过程中涉及到堆化过程而且上面也演示过了,所以下面只演示初始和结束两个状态: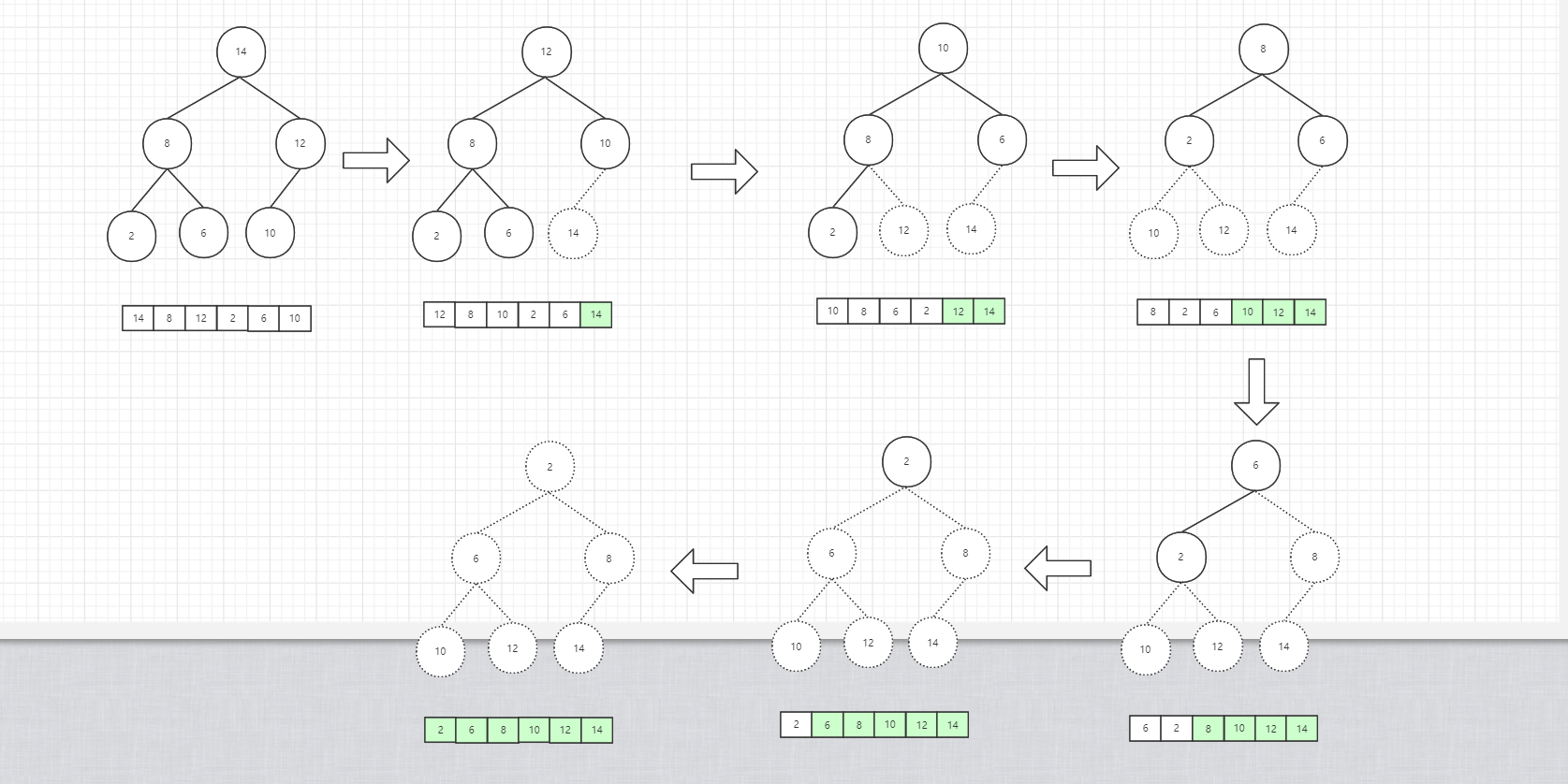
代码实现如下:
public static void sort(int[] data) {
int len = data.length - 1;
//将数组构建成一颗二叉堆
build(data,len);
while (len > 0) {
//数组第一个元素和二叉堆中最后一个元素交换位置
swap(data,0,len);
//堆化
heapify(data,0,--len);
}
}
/**
* 建堆
* @param data 数据
* @param len 长度
*/
private static void build(int[] data,int len){
for (int i = len >> 1;i >= 0;i--) {
heapify(data,i,len);
}
}
/**
* 堆化
* @param data 数据
* @param start 开始位置
* @param end 结束位置
*/
private static void heapify(int[] data,int start,int end){
while (true){
int max = start;
int left = max << 1;
int right = left + 1;
if (left <= end && data[max] < data[left]) {
max = left;
}
if (right <= end && data[max] < data[right]){
max = right;
}
if (max == start) {
break;
}
swap(data,start,max);
start = max;
}
}
/**
* 将data数组中i和j的数据互换
* @param data 数据
* @param i 下标
* @param j 下标
*/
private static void swap(int[] data,int i,int j){
int tmp = data[i];
data[i] = data[j];
data[j] = tmp;
}
(二)、堆排序时间复杂度
堆排序时间复杂度需要计算初始化堆和重建堆的时间复杂度。
初始化堆的复杂度:假如有N个节点,那么高度为H=logN,最后一层每个父节点最多只需要下调1次,倒数第二层最多只需要下调2次,顶点最多需要下调H次,而最后一层父节点共有2^(H-1)个,倒数第二层公有2^(H-2),顶点只有1(2^0)个,所以总共的时间复杂度为s = 1 * 2^(H-1) + 2 * 2^(H-2) + ... + (H-1) * 2^1 + H * 2^0;将H代入后s= 2N - 2 - log2(N),近似的时间复杂度就是O(N)。
重建堆时间复杂度:循环 n -1 次,每次都是从根节点往下循环查找,所以每一次时间是 logn,总时间:logn(n-1) = nlogn - logn
综上所述,堆排序的时间复杂度为 O(nlogn)
(三)、堆排序时间测试
生成100万个随机数进行排序,排序总花费时间为:280毫秒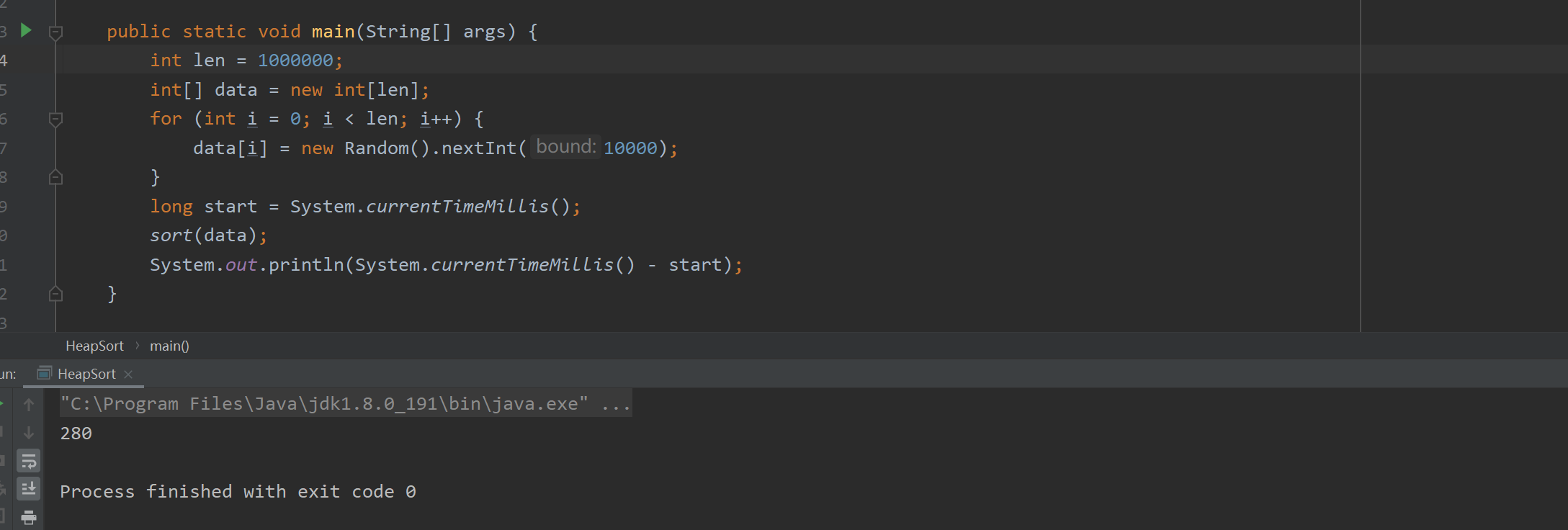
1000万随机数排序平均花费时间大概是3s多。
喜欢我写的博客的同学可以关注订阅号【Java解忧杂货铺】,里面不定期发布一些技术干活,也可以免费获取大量最新最流行的技术教学视频


 浙公网安备 33010602011771号
浙公网安备 33010602011771号