集合
集合
集合就是由若干元素组合的整体,类似于容器,可以存储任何类型的数据,结合泛型可以做到存储某一种类的具体类型
由于集合相比较于数组在内部已经实现了长度可变的特点,所以更适用于现代开发需求
java目前的集合主要由两大体系,分别是Collection体系和Map体系
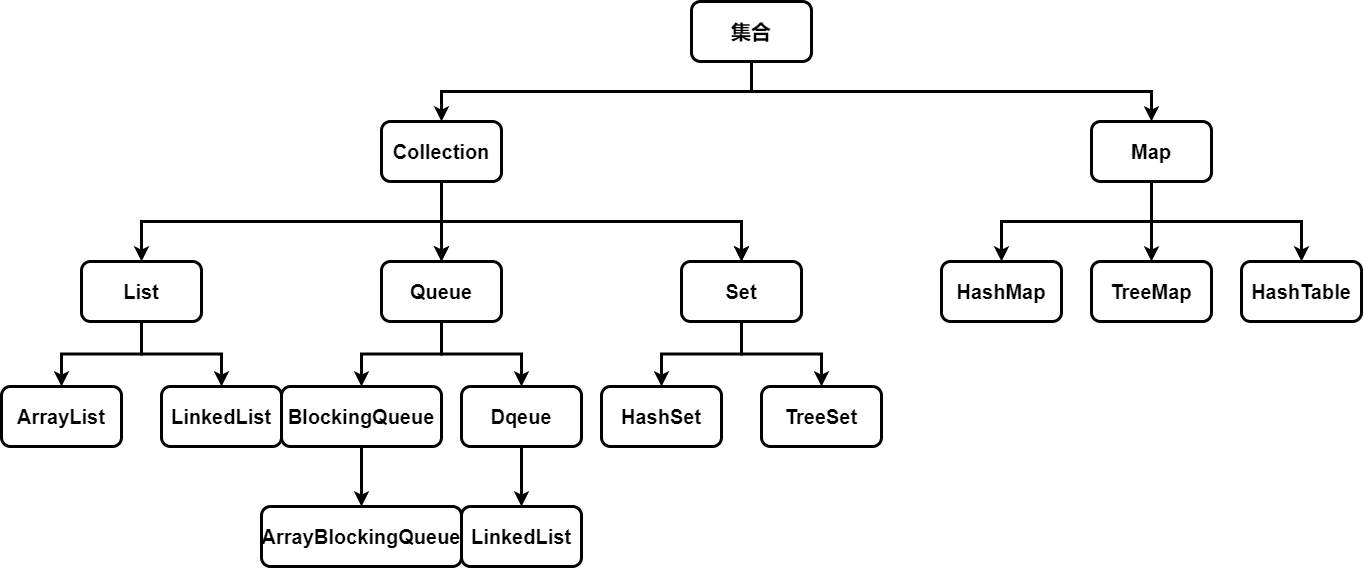
Collection
List [Interface]
在Collection 中,List 集合是最基础的集合,是一个有序列表,通过索引来操作元素,可以添加重复元素
常用方法
add(E e)add(int index, E e)get(int index)remove(E e)remove(int index)set(int index) 可以通过静态工厂方法 of() 创建一个只读的列表
没有索引,只能通过迭代器访问
ArrayList
ArrayList 继承于 AbstractList,实现了List, RandomAccess, Cloneable, Serializable接口
(1)ArrayList 实现List,得到了List集合框架基础功能;
- 作为一个数组结构的列表,具有以下特点
- 容量不固定(默认构造容量为10,随着数据增加而扩大)
- 有序集合(输入与输出的顺序一致)
- 插入的元素可以为null
- 改查效率更高(相比较于LinkedList)
- 线程不安全
LinkedList
LinkedList 继承于 AbstractList,实现了Lsit, Deque, Cloneable, Serializable接口
(1)LinkedList 实现List,可以使用List集合框架基础功能
(2)LinkedList 实现Deque, 可以在可以在头部和为部增删元素
- 作为一个链表结构的列表,具有以下特点
- 容量不固定(默认构造容量为10,随着数据增加而扩大)
- 有序集合(输入与输出的顺序一致)
- 增删效率更高
- 线程不安全
public class ArrayListComLinkedList {
// 比较ArrayList和LinkedList增加元素的效率,LinkedList更快。其他略
public static void main(String[] args) {
long time1 = System.currentTimeMillis();
arrayListAddLastEle();
long time2 = System.currentTimeMillis();
arrayListAddFirstEle();
long time3 = System.currentTimeMillis();
linkedListAddEle();
long time4 = System.currentTimeMillis();
System.out.printf("ArrayList在后面增加元素 %d ms\n", (time2 - time1));
System.out.printf("ArrayList在第一个位置面增加元素 %d ms\n", (time3 - time2));
System.out.printf("LinedList在后面增加元素 %d ms\n", (time4 - time3));
}
public static void arrayListAddLastEle(){
List<Integer> list = new ArrayList<>();
for (int i = 0; i < 10000; i++){
list.add(i);
}
}
public static void arrayListAddFirstEle(){
List<Integer> list = new ArrayList<>();
for (int i = 0; i < 10000; i++){
list.add(0, i);
}
}
public static void linkedListAddEle(){
List<Integer> list = new LinkedList<>();
for (int i = 0; i< 10000; i++){
list.add(i);
}
}
}
部分源码分析
1. ArrayList构造
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
private static final long serialVersionUID = 8683452581122892189L;
/**
* Default initial capacity.
*/
private static final int DEFAULT_CAPACITY = 10;
/**
* Shared empty array instance used for empty instances.
*/
private static final Object[] EMPTY_ELEMENTDATA = {};
/**
* Shared empty array instance used for default sized empty instances. We
* distinguish this from EMPTY_ELEMENTDATA to know how much to inflate when
* first element is added.
*/
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
/**
* The array buffer into which the elements of the ArrayList are stored.
* The capacity of the ArrayList is the length of this array buffer. Any
* empty ArrayList with elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA
* will be expanded to DEFAULT_CAPACITY when the first element is added.
*/
transient Object[] elementData; // non-private to simplify nested class access
/**
* The size of the ArrayList (the number of elements it contains).
*
* @serial
*/
private int size;
/**
* Constructs an empty list with the specified initial capacity.
*
* @param initialCapacity the initial capacity of the list
* @throws IllegalArgumentException if the specified initial capacity
* is negative
*/
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
/**
* Constructs an empty list with an initial capacity of ten.
*/
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
/**
* Constructs a list containing the elements of the specified
* collection, in the order they are returned by the collection's
* iterator.
*
* @param c the collection whose elements are to be placed into this list
* @throws NullPointerException if the specified collection is null
*/
public ArrayList(Collection<? extends E> c) {
elementData = c.toArray();
if ((size = elementData.length) != 0) {
// c.toArray might (incorrectly) not return Object[] (see 6260652)
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
// replace with empty array.
this.elementData = EMPTY_ELEMENTDATA;
}
}
-
可以看到在无参构造的时候,实际上只是创建了一个对象,并没有初始化容量
-
elementData 只是一个缓存储存的对象,当第一次增加元素的时候,就会扩容到DEFAULT_CAPACITY == 10;
2. 增删改查的实现
-
add()
/** * Appends the specified element to the end of this list. * * @param e element to be appended to this list * @return <tt>true</tt> (as specified by {@link Collection#add}) */ public boolean add(E e) { ensureCapacityInternal(size + 1); // Increments modCount!! elementData[size++] = e; return true; } /** * Inserts the specified element at the specified position in this * list. Shifts the element currently at that position (if any) and * any subsequent elements to the right (adds one to their indices). * * @param index index at which the specified element is to be inserted * @param element element to be inserted * @throws IndexOutOfBoundsException {@inheritDoc} */ public void add(int index, E element) { rangeCheckForAdd(index); ensureCapacityInternal(size + 1); // Increments modCount!! System.arraycopy(elementData, index, elementData, index + 1, size - index); elementData[index] = element; size++; } /** * A version of rangeCheck used by add and addAll. */ private void rangeCheckForAdd(int index) { if (index > size || index < 0) throw new IndexOutOfBoundsException(outOfBoundsMsg(index)); } /** * Increases the capacity of this <tt>ArrayList</tt> instance, if * necessary, to ensure that it can hold at least the number of elements * specified by the minimum capacity argument. * * @param minCapacity the desired minimum capacity */ public void ensureCapacity(int minCapacity) { int minExpand = (elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA) // any size if not default element table ? 0 // larger than default for default empty table. It's already // supposed to be at default size. : DEFAULT_CAPACITY; if (minCapacity > minExpand) { ensureExplicitCapacity(minCapacity); } } private void ensureCapacityInternal(int minCapacity) { if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) { minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity); } ensureExplicitCapacity(minCapacity); } private void ensureExplicitCapacity(int minCapacity) { modCount++; // overflow-conscious code if (minCapacity - elementData.length > 0) grow(minCapacity); } private void grow(int minCapacity) { // overflow-conscious code int oldCapacity = elementData.length; int newCapacity = oldCapacity + (oldCapacity >> 1); if (newCapacity - minCapacity < 0) newCapacity = minCapacity; if (newCapacity - MAX_ARRAY_SIZE > 0) newCapacity = hugeCapacity(minCapacity); // minCapacity is usually close to size, so this is a win: elementData = Arrays.copyOf(elementData, newCapacity); }- 调用add() 方法,需求的最小空间可以看出是 size+1 ,如果存储空间 elementData 没有初始化,那么就会返回默认容量十 不然就返回需求的容量, 检查需求的容量是否大于存储空间的大小,如果大于,那么就调用扩容方法。新容量按照 老容量+老容量>>1 增加,同时会检查是否1.5倍不够,那么就新容量直接等于需要的容量。检查容量大于 int最大数-8,那么直接会调用一个 hugeCapacity, 新容量确认完,调用Arrays.copy方法增加数组的容量(这一步也就是最影响ArrayList写入的性能)
-
remove()
public E remove(int index) { rangeCheck(index); modCount++; E oldValue = elementData(index); int numMoved = size - index - 1; if (numMoved > 0) System.arraycopy(elementData, index+1, elementData, index, numMoved); elementData[--size] = null; // clear to let GC do its work return oldValue; } /* * Private remove method that skips bounds checking and does not * return the value removed. */ private void fastRemove(int index) { modCount++; int numMoved = size - index - 1; if (numMoved > 0) System.arraycopy(elementData, index+1, elementData, index, numMoved); elementData[--size] = null; // clear to let GC do its work }- 可以看到,不管o是不是null,那么都会进行从头到尾的排查,找到这个元素,调用fastremove方法,然后使用System.arraycopy复制后面部分的元素都前进一位,并把最后一位元素置为null
-
set()
/** * Replaces the element at the specified position in this list with * the specified element. * * @param index index of the element to replace * @param element element to be stored at the specified position * @return the element previously at the specified position * @throws IndexOutOfBoundsException {@inheritDoc} */ public E set(int index, E element) { rangeCheck(index); E oldValue = elementData(index); elementData[index] = element; return oldValue; } /** * Checks if the given index is in range. If not, throws an appropriate * runtime exception. This method does *not* check if the index is * negative: It is always used immediately prior to an array access, * which throws an ArrayIndexOutOfBoundsException if index is negative. */ private void rangeCheck(int index) { if (index >= size) throw new IndexOutOfBoundsException(outOfBoundsMsg(index)); }- 首先进行范围判断,看是否越界,保存旧数据,设置新数据,抛出新数据
-
get()
public E get(int index) { rangeCheck(index); return elementData(index); }- 检查越界,返回数据
3. 迭代器-modCount
-
在增删和部分修改的地方,会发生 modCount++ ,那么modCount 可以是看做ArrayList的一个版本号
/** * The number of times this list has been <i>structurally modified</i>. * Structural modifications are those that change the size of the * list, or otherwise perturb it in such a fashion that iterations in * progress may yield incorrect results. * * <p>This field is used by the iterator and list iterator implementation * returned by the {@code iterator} and {@code listIterator} methods. * If the value of this field changes unexpectedly, the iterator (or list * iterator) will throw a {@code ConcurrentModificationException} in * response to the {@code next}, {@code remove}, {@code previous}, * {@code set} or {@code add} operations. This provides * <i>fail-fast</i> behavior, rather than non-deterministic behavior in * the face of concurrent modification during iteration. * * <p><b>Use of this field by subclasses is optional.</b> If a subclass * wishes to provide fail-fast iterators (and list iterators), then it * merely has to increment this field in its {@code add(int, E)} and * {@code remove(int)} methods (and any other methods that it overrides * that result in structural modifications to the list). A single call to * {@code add(int, E)} or {@code remove(int)} must add no more than * one to this field, or the iterators (and list iterators) will throw * bogus {@code ConcurrentModificationExceptions}. If an implementation * does not wish to provide fail-fast iterators, this field may be * ignored. */ protected transient int modCount = 0;- 这里写出了,这个字符用于检查列表的一些结构化的改变,而这些机构化的改变例如增删或者一些其他的操作可能会导致迭代器抛出一些不正确的结果
-
迭代器的实现
/** * Returns an iterator over the elements in this list in proper sequence. * * <p>The returned iterator is <a href="#fail-fast"><i>fail-fast</i></a>. * * @return an iterator over the elements in this list in proper sequence */ public Iterator<E> iterator() { return new Itr(); } /** * An optimized version of AbstractList.Itr */ private class Itr implements Iterator<E> { // 指向下一个返回的元素 int cursor; // index of next element to return // 指向最后返回的元素 int lastRet = -1; // index of last element returned; -1 if no such // 期望的迭代版本应该是某一个固定过的版本,在这个过程中不应该发生改变 int expectedModCount = modCount; // 判断指针是否已经到了最后一个元素后面 public boolean hasNext() { return cursor != size; } @SuppressWarnings("unchecked") public E next() { // 检查版本变化,如果变化了直接报并发修改异常,不继续执行下面了 checkForComodification(); // 将 i 指向cursor位置 int i = cursor; if (i >= size) // 检查是否已经超过了所有元素的索引 throw new NoSuchElementException(); Object[] elementData = ArrayList.this.elementData; if (i >= elementData.length) // 检查是否大于数组的长度 throw new ConcurrentModificationException(); // 指向下一个元素 cursor = i + 1; // 返回迭代的元素 return (E) elementData[lastRet = i]; } public void remove() { if (lastRet < 0) // 迭代器自己的remove方法先检查上一个返回的元素小于0的话报错 throw new IllegalStateException(); // 检查修改版本 checkForComodification(); try { // 自己的remove方法会修改指针全部 -1,并且更新修改版本 ArrayList.this.remove(lastRet); cursor = lastRet; lastRet = -1; expectedModCount = modCount; } catch (IndexOutOfBoundsException ex) { throw new ConcurrentModificationException(); } } @Override @SuppressWarnings("unchecked") public void forEachRemaining(Consumer<? super E> consumer) { Objects.requireNonNull(consumer); // 首先size指向列表的大小,不应该改变 final int size = ArrayList.this.size; // i指向当前元素 int i = cursor; if (i >= size) { // 大于的话直接返回不再执行,这个就是造成如果列表2元素并同时修改不会报错,大于2就会报错 return; } final Object[] elementData = ArrayList.this.elementData; if (i >= elementData.length) { // 检查是否大于数据的长度 throw new ConcurrentModificationException(); } while (i != size && modCount == expectedModCount) { // 如果不大于并且修改版本不变,那么就直接返回i值 consumer.accept((E) elementData[i++]); } // update once at end of iteration to reduce heap write traffic cursor = i; lastRet = i - 1; // 下面这个就会造成只有一个元素的时候会报错 checkForComodification(); } final void checkForComodification() { if (modCount != expectedModCount) // 检查修改的版本 throw new ConcurrentModificationException(); } }- 获取迭代器对象,检查版本变化,检查当前是否到达最后一个元素,是否超过数组长度,都ok就返回当前元素
- 迭代器自己的remove方法会指针自减,版本号更新,所以不会报错
4. Arrays.copy()
public static <T,U> T[] copyOf(U[] original, int newLength, Class<? extends T[]> newType) {
@SuppressWarnings("unchecked")
T[] copy = ((Object)newType == (Object)Object[].class)
? (T[]) new Object[newLength]
: (T[]) Array.newInstance(newType.getComponentType(), newLength);
System.arraycopy(original, 0, copy, 0,
Math.min(original.length, newLength));
return copy;
}
public static native void arraycopy(Object src, int srcPos,
Object dest, int destPos,
int length);
- 在内部创建了一个新长度的数组,调用System.arraycopy方法,返回copy后的新数组
5. LinkedList基础
/**
* Doubly-linked list implementation of the {@code List} and {@code Deque}
* interfaces. Implements all optional list operations, and permits all
* elements (including {@code null}).
*
* <p>All of the operations perform as could be expected for a doubly-linked
* list. Operations that index into the list will traverse the list from
* the beginning or the end, whichever is closer to the specified index.
*
* <p><strong>Note that this implementation is not synchronized.</strong>
* If multiple threads access a linked list concurrently, and at least
* one of the threads modifies the list structurally, it <i>must</i> be
* synchronized externally. (A structural modification is any operation
* that adds or deletes one or more elements; merely setting the value of
* an element is not a structural modification.) This is typically
* accomplished by synchronizing on some object that naturally
* encapsulates the list.
*
* If no such object exists, the list should be "wrapped" using the
* {@link Collections#synchronizedList Collections.synchronizedList}
* method. This is best done at creation time, to prevent accidental
* unsynchronized access to the list:<pre>
* List list = Collections.synchronizedList(new LinkedList(...));</pre>
*
* <p>The iterators returned by this class's {@code iterator} and
* {@code listIterator} methods are <i>fail-fast</i>: if the list is
* structurally modified at any time after the iterator is created, in
* any way except through the Iterator's own {@code remove} or
* {@code add} methods, the iterator will throw a {@link
* ConcurrentModificationException}. Thus, in the face of concurrent
* modification, the iterator fails quickly and cleanly, rather than
* risking arbitrary, non-deterministic behavior at an undetermined
* time in the future.
*
* <p>Note that the fail-fast behavior of an iterator cannot be guaranteed
* as it is, generally speaking, impossible to make any hard guarantees in the
* presence of unsynchronized concurrent modification. Fail-fast iterators
* throw {@code ConcurrentModificationException} on a best-effort basis.
* Therefore, it would be wrong to write a program that depended on this
* exception for its correctness: <i>the fail-fast behavior of iterators
* should be used only to detect bugs.</i>
- 可以看到在jdk 1.8中,LinkedList是一个双向队列,并且对于特定index的操作会遍历集合,入口是哪个更近
- 不是线程安全的
6. 增删改查
-
add()
/** * Appends the specified element to the end of this list. * * <p>This method is equivalent to {@link #addLast}. * * @param e element to be appended to this list * @return {@code true} (as specified by {@link Collection#add}) */ public boolean add(E e) { linkLast(e); return true; } /** * Inserts the specified element at the specified position in this list. * Shifts the element currently at that position (if any) and any * subsequent elements to the right (adds one to their indices). * * @param index index at which the specified element is to be inserted * @param element element to be inserted * @throws IndexOutOfBoundsException {@inheritDoc} */ public void add(int index, E element) { checkPositionIndex(index); if (index == size) linkLast(element); else linkBefore(element, node(index)); } private void checkPositionIndex(int index) { if (!isPositionIndex(index)) throw new IndexOutOfBoundsException(outOfBoundsMsg(index)); } private boolean isPositionIndex(int index) { return index >= 0 && index <= size; } /** * Links e as last element. */ void linkLast(E e) { final Node<E> l = last; final Node<E> newNode = new Node<>(l, e, null); last = newNode; if (l == null) first = newNode; else l.next = newNode; size++; modCount++; } /** * Inserts element e before non-null Node succ. */ void linkBefore(E e, Node<E> succ) { // assert succ != null; final Node<E> pred = succ.prev; final Node<E> newNode = new Node<>(pred, e, succ); succ.prev = newNode; if (pred == null) first = newNode; else pred.next = newNode; size++; modCount++; }- 可以看到增加元素,先检查index是否满足规范(0 - size之间(等于size是指可以用最后null))
- 然后确定在前面增加还是后面增加
-
remove()
/** * Removes the element at the specified position in this list. Shifts any * subsequent elements to the left (subtracts one from their indices). * Returns the element that was removed from the list. * * @param index the index of the element to be removed * @return the element previously at the specified position * @throws IndexOutOfBoundsException {@inheritDoc} */ public E remove(int index) { checkElementIndex(index); return unlink(node(index)); } /** * Removes the first occurrence of the specified element from this list, * if it is present. If this list does not contain the element, it is * unchanged. More formally, removes the element with the lowest index * {@code i} such that * <tt>(o==null ? get(i)==null : o.equals(get(i)))</tt> * (if such an element exists). Returns {@code true} if this list * contained the specified element (or equivalently, if this list * changed as a result of the call). * * @param o element to be removed from this list, if present * @return {@code true} if this list contained the specified element */ public boolean remove(Object o) { if (o == null) { for (Node<E> x = first; x != null; x = x.next) { if (x.item == null) { unlink(x); return true; } } } else { for (Node<E> x = first; x != null; x = x.next) { if (o.equals(x.item)) { unlink(x); return true; } } } return false; } /** * Unlinks non-null node x. */ E unlink(Node<E> x) { // assert x != null; final E element = x.item; final Node<E> next = x.next; final Node<E> prev = x.prev; if (prev == null) { first = next; } else { prev.next = next; x.prev = null; } if (next == null) { last = prev; } else { next.prev = prev; x.next = null; } x.item = null; size--; modCount++; return element; }- 可以看到提供两种remove()方法,最后都是调用unlink()方法
-
set()
/** * Replaces the element at the specified position in this list with the * specified element. * * @param index index of the element to replace * @param element element to be stored at the specified position * @return the element previously at the specified position * @throws IndexOutOfBoundsException {@inheritDoc} */ public E set(int index, E element) { checkElementIndex(index); Node<E> x = node(index); E oldVal = x.item; x.item = element; return oldVal; } /** * Returns the (non-null) Node at the specified element index. */ Node<E> node(int index) { // assert isElementIndex(index); if (index < (size >> 1)) { Node<E> x = first; for (int i = 0; i < index; i++) x = x.next; return x; } else { Node<E> x = last; for (int i = size - 1; i > index; i--) x = x.prev; return x; } }- 检查越界问题,存储旧值,设置新值,返回旧值
- 需要注意的是node方法,通过角标返回Node节点,判断中值,然后遍历半个集合
-
get()
public E get(int index) { checkElementIndex(index); return node(index).item; }- 返回旧值
Queue [Interface]
Queue 实现的是 Collection 接口
LinkedList 实现了 Collection 接口
Deque 是一个双端队列,LinkedList 也实现了该接口,所以基本上队列的操作和List是差不多的,只是对于方法名有区别,但是方法内部实现的还是Colletion操作
Set [Interface]
Set继承于Collection接口,是一个不允许出现重复元素的单列集合,并且无序,主要由HashSet和TreeSet两大实现类
注意事项: Set集合元素没有索引,只能使用迭代器遍历,Set集合没有特殊的方法,只有Collection的方法
HashSet
HashSet 是哈希表结构,底层实现是一个HashMap,主要是利用计算key的HashCode来获取元素在集合中的位置,value是一个固定的Object
-
具有如下特点
- 不允许出现重复元素
- 允许null值
- 元素(存储顺序不一致)
- 线程不安全
-
检验HashSet添加元素时的情况
public class SetDemo { public static void main(String[] args) { // 对于没有重写hashcode方法的对象 Set<TestDemoFirst> set1 = new HashSet<>(); set1.add(new TestDemoFirst(1)); set1.add(new TestDemoFirst(1)); System.out.println(set1.size()); // 2 // 对于重写了hashcode方法的对象 Set<TestDemoSecond> set2 = new HashSet<>(); set2.add(new TestDemoSecond(1)); set2.add(new TestDemoSecond(1)); System.out.println(set2.size()); // 1 } } class TestDemoFirst{ int value; public TestDemoFirst(int value){ this.value = value; } } class TestDemoSecond{ int value; public TestDemoSecond(int value){ this.value = value; } @Override public boolean equals(Object o) { if (this == o) return true; if (!(o instanceof TestDemoSecond)) return false; TestDemoSecond that = (TestDemoSecond) o; return value == that.value; } @Override public int hashCode() { return Objects.hash(value); } }- 可见,对于实现了equals和hashcode方法的类,set可以进行对象之间的比较,排除重复项
TreeSet
TreeSet 与树结构有关,基于Map的实现,具体底层结构位红黑树
与HashSet不同,TreeSet具有排序功能,分为自然排序和自定义排序两种
-
特殊方法
-
ceiling(E e)返回给定元素以上最小的元素,可以是自身 -
floor(E e)返回给定元素以下最大的元素,可以是自身 -
lower(E e)返回给定元素以下最大的元素,不可以是自己 -
descendingIterator()创建倒叙迭代器for (Iterator<Integer> it = treeSet.descendingIterator(); it.hasNext(); ){ System.out.println(it.next()); } -
iterator()创建正向迭代器 -
first()返回第一个元素 -
last()返回最后一个元素 -
还有返回两个元素之间的元素……
-
-
对Tree里面的元素进行排序操作
class TreeSetDemo{ public static void main(String[] args) { Set<Integer> set1 = new TreeSet<>(); set1.add(1); set1.add(2); set1.add(3); set1.add(4); set1.add(5); System.out.println(set1); // [1, 2, 3, 4, 5] } } // 可以看到按照默认排序方式进行了排序 class TreeSetDemo{ public static void main(String[] args) { Set<Person> set = new TreeSet<>(); set.add(new Person("张三", 68)); set.add(new Person("李四", 28)); set.add(new Person("王五", 38)); set.add(new Person("赵六", 18)); System.out.println(set); } } class Person implements Comparable<Person>{ String name; int age; public Person(String name, int age){ this.name = name; this.age = age; } @Override public int compareTo(Person p) { if (this.age == p.age) return 0; return this.age < p.age ? -1 : 1; } @Override public String toString(){ return this.name + " : " + this.age; } } // 可以看到在实现了 Comparable接口后,元素实现了从低到高排序,并且可以尝试,在添加相同年纪的人,可以看到无法添加,这是因为compareTo方法内将age相等的情况视为两种对象是一样的,所以可以不用重写equals和hashcode方法 // 但是如果这样写未免代码有点多余,因为并不能保证每一个类都要实现Comparable接口覆写compareTo方法 class TreeSetDemo { public static void main(String[] args) { Set<Person> set = new TreeSet<>((Person p1, Person P2) -> { if (p1.age == P2.age) return 0; return p1.age < P2.age ? -1 : 1; }); set.add(new Person("张三", 68)); set.add(new Person("李四", 28)); set.add(new Person("王五", 38)); set.add(new Person("赵六", 18)); System.out.println(set); } } class Person { String name; int age; public Person(String name, int age) { this.name = name; this.age = age; } @Override public String toString() { return this.name + " : " + this.age; } } // 在创建set集合的时候指定排序算法,可以保证同样的效果,减少代码耦合程度
部分源码分析
1. HashSet
/**
* Constructs a new, empty set; the backing <tt>HashMap</tt> instance has
* default initial capacity (16) and load factor (0.75).
*/
public HashSet() {
// 创建了一个空的hashMap
map = new HashMap<>();
}
/**
* Adds the specified element to this set if it is not already present.
* More formally, adds the specified element <tt>e</tt> to this set if
* this set contains no element <tt>e2</tt> such that
* <tt>(e==null ? e2==null : e.equals(e2))</tt>.
* If this set already contains the element, the call leaves the set
* unchanged and returns <tt>false</tt>.
*
* @param e element to be added to this set
* @return <tt>true</tt> if this set did not already contain the specified
* element
*/
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
private static final Object PRESENT = new Object();
// 可见在增加元素的方法里面,使用的时HashMap里面的put方法,并且value传入的是同一个对象
// 返回的是该位置是否位空
/**
* Removes the specified element from this set if it is present.
* More formally, removes an element <tt>e</tt> such that
* <tt>(o==null ? e==null : o.equals(e))</tt>,
* if this set contains such an element. Returns <tt>true</tt> if
* this set contained the element (or equivalently, if this set
* changed as a result of the call). (This set will not contain the
* element once the call returns.)
*
* @param o object to be removed from this set, if present
* @return <tt>true</tt> if the set contained the specified element
*/
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
// remove方法同理
// 具体put和remove方法后续在Map源代码里面讲解
2.TreeSet
/**
* Constructs a new, empty tree set, sorted according to the
* natural ordering of its elements. All elements inserted into
* the set must implement the {@link Comparable} interface.
* Furthermore, all such elements must be <i>mutually
* comparable</i>: {@code e1.compareTo(e2)} must not throw a
* {@code ClassCastException} for any elements {@code e1} and
* {@code e2} in the set. If the user attempts to add an element
* to the set that violates this constraint (for example, the user
* attempts to add a string element to a set whose elements are
* integers), the {@code add} call will throw a
* {@code ClassCastException}.
*/
public TreeSet() {
this(new TreeMap<E,Object>());
}
// 可以看到空参构造方法就是创建了一个 TreeMap
// 其他同理
Map
Map 集合在开发中应用非常广泛,其地位和 Collection 同级
提供了一个不一样的元素存储方式,通过 key——value 的方式存储,其中每一个 key 对应有一个 value 值,key 都是独一无二的
常用方法:
containesKey(Object key)containsValue(Object value)get(Object key)put(K key, V value)remove(Object key)Set<K> keySet()Collection<V> values()Set<java.util.Map.Entry<K, V>> entrySet()
HashMap
HashMap基于哈希表,底层结构由数组实现,添加到集合中的元素以
key——value形式存储到数组中,在数组中以一个对象来处理
-
在HashMap中,Entry[] 保存了中所有的键值对,当我们需要快速存储、获取、删除集合中的元素时,HashMap会根据 hash 算法来获取 ”键值对对象“ 在数组中的位置,实现对象的操作。当新增的元素hash值冲突(这种情况称为哈希碰撞或哈希冲突),那么会使用链表解决,当链表长度大于8并且哈希表总长大于64,该位置会转换为红黑树结构
-
数组结构的哈希表,具有以下特点
- 允许null键,null值
- 无序
- 容量不固定(默认容量16,负载因子0.75)
- 不存在重复元素
- 线程不安全
-
HashMap 容量为什么最好是2的N次方
- 当length为2的N次方的话,一定为偶数,这样length-1则一定为奇数,而奇数转换成二进制的话,最后一位定为1(可以自己测试下),这样当我们的hash值 与 奇数 进行与运算时候,得到的结果即可能为奇数,也可能为偶数(取决于hash值),此时的散列性更好,出现哈希冲突的情况就比较低,也就是说HashMap中形成链表的可能性更低;
- 而当length为奇数时,length-1为偶数,转换成二进制的话最后一位是0。根据上面的与运算实现来看,当用0来进行运算时,得到的结果均为0,既无论hash值是多少,最终都只能是偶数。相比于上面来说,length是奇数相当于浪费掉Entry数组一半的空间,更容易出现哈希冲突,形成链表,进而影响整个HashMap的性能。
- 所以,HashMap选择将length设置为2的N次方,既永远都是偶数;
LinkedHashMap
LinkedHashMap 继承于HashMap,底层结构由双向链表实现,添加到集合中的元素以
Entry数组来存储
部分源码分析
1. HashMap的底层数据结构
/**
* The table, initialized on first use, and resized as
* necessary. When allocated, length is always a power of two.
*/
// 可以看到,底层结构是一个数组,初始化是在第一次使用,容量总是2的次方
transient Node<K,V>[] table;
/**
* The default initial capacity - MUST be a power of two.
*/
// 默认长度16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
/**
* The maximum capacity, used if a higher value is implicitly specified
* by either of the constructors with arguments.
* MUST be a power of two <= 1<<30.
*/
// 最大容量必须是2的次方
static final int MAXIMUM_CAPACITY = 1 << 30;
/**
* The load factor used when none specified in constructor.
*/
// 默认负载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
* The bin count threshold for using a tree rather than list for a
* bin. Bins are converted to trees when adding an element to a
* bin with at least this many nodes. The value must be greater
* than 2 and should be at least 8 to mesh with assumptions in
* tree removal about conversion back to plain bins upon
* shrinkage.
*/
// 节点树形化阈值
static final int TREEIFY_THRESHOLD = 8;
/**
* The bin count threshold for untreeifying a (split) bin during a
* resize operation. Should be less than TREEIFY_THRESHOLD, and at
* most 6 to mesh with shrinkage detection under removal.
*/
// 取消树形化阈值
static final int UNTREEIFY_THRESHOLD = 6;
/**
* The smallest table capacity for which bins may be treeified.
* (Otherwise the table is resized if too many nodes in a bin.)
* Should be at least 4 * TREEIFY_THRESHOLD to avoid conflicts
* between resizing and treeification thresholds.
*/
// 树形化最小容量
static final int MIN_TREEIFY_CAPACITY = 64;
/**
* Basic hash bin node, used for most entries. (See below for
* TreeNode subclass, and in LinkedHashMap for its Entry subclass.)
*/
// HashMap 的最终实现
// 可见在1.8中,HashMap的存储元素对象是Node节点
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
/**
* Constructs an empty <tt>HashMap</tt> with the specified initial
* capacity and load factor.
*
* @param initialCapacity the initial capacity
* @param loadFactor the load factor
* @throws IllegalArgumentException if the initial capacity is negative
* or the load factor is nonpositive
*/
// 三个构造函数最后都是确定了一个loadFactor负载因子的大小
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
/**
* Constructs an empty <tt>HashMap</tt> with the specified initial
* capacity and the default load factor (0.75).
*
* @param initialCapacity the initial capacity.
* @throws IllegalArgumentException if the initial capacity is negative.
*/
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
/**
* Constructs an empty <tt>HashMap</tt> with the default initial capacity
* (16) and the default load factor (0.75).
*/
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
/**
* Associates the specified value with the specified key in this map.
* If the map previously contained a mapping for the key, the old
* value is replaced.
*
* @param key key with which the specified value is to be associated
* @param value value to be associated with the specified key
* @return the previous value associated with <tt>key</tt>, or
* <tt>null</tt> if there was no mapping for <tt>key</tt>.
* (A <tt>null</tt> return can also indicate that the map
* previously associated <tt>null</tt> with <tt>key</tt>.)
*/
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
/**
* Implements Map.put and related methods
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 如果table还未初始化,就进行初始化操作
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 如果传进来的节点在tab里面没有元素,那么就直接赋值
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
// e保存传进来的节点hash值相同的元素的数组中的链表(or 树)头节点
Node<K,V> e; K k;
// 如果传进来的p和现有元素的hash相等,那么判断key是否相同,或者p属于树节点,就进行红黑树的操作
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
// 如果key不相同,那么就对比每一个当前数组位置的所有节点的key,没有的话就在最后面添加元素,并判断节点高度是否满足树形化的要求,有的话就说明重复了并保存重复的节点
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
// 如果e不等于null,说明其实已经存在了相同元素
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
// 增加一次修改记录
++modCount;
// 如果大小超过了容量就扩容
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
/**
* Initializes or doubles table size. If null, allocates in
* accord with initial capacity target held in field threshold.
* Otherwise, because we are using power-of-two expansion, the
* elements from each bin must either stay at same index, or move
* with a power of two offset in the new table.
*
* @return the table
*/
// 扩容方法
final Node<K,V>[] resize() {
// odlTab保存旧表,oldCap保存旧长度,oldThr保存旧容量
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
// 如果旧长度已经大于了1<<30,那么新容量只能等于最大int 2^31 - 1
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 否则新容量等于旧容量 *2
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
// 运行到这一步说明是指定了初始化容量,那么新数组的阈值等于老数组的阈值
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
// 运行到这里说明是无参构造,并且第一次添加元素
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// 如果扩容阈值等于0
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr; // 设置map的扩容阈值为新的阈值
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
// 创建一个新数组
table = newTab;
// 将map的table属性指向到该新数组
if (oldTab != null) {
// 如果老数组不为空,那么就是扩容操作
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
// 遍历
if ((e = oldTab[j]) != null) {
// 如果老数组当前元素不为空,那么就取出来
oldTab[j] = null;
if (e.next == null)
// 如果该位置只有一个元素就直接拿过去
// 新位置需要用hash取模
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
// 如果该节点为树节点
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
// 遍历该位置上面的链表
// 针对取模大于老数组的长度和小于老数组的长度开两个链表
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
// 大于的放到 j+oldCap上
// 小于的放回原位置
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
2. HashMap的操作
- 查找元素
/**
* Returns the value to which the specified key is mapped,
* or {@code null} if this map contains no mapping for the key.
*
* <p>More formally, if this map contains a mapping from a key
* {@code k} to a value {@code v} such that {@code (key==null ? k==null :
* key.equals(k))}, then this method returns {@code v}; otherwise
* it returns {@code null}. (There can be at most one such mapping.)
*
* <p>A return value of {@code null} does not <i>necessarily</i>
* indicate that the map contains no mapping for the key; it's also
* possible that the map explicitly maps the key to {@code null}.
* The {@link #containsKey containsKey} operation may be used to
* distinguish these two cases.
*
* @see #put(Object, Object)
*/
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
/**
* Implements Map.get and related methods
*
* @param hash hash for key
* @param key the key
* @return the node, or null if none
*/
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
// 如果数组不为空,并且hash位有元素
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
// 如果第一个hash key都对,那么就返回第一个
if ((e = first.next) != null) {
if (first instanceof TreeNode)
// 树操作
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
// 循环查找直到链表尾部
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
- 删除元素
/**
* Removes the mapping for the specified key from this map if present.
*
* @param key key whose mapping is to be removed from the map
* @return the previous value associated with <tt>key</tt>, or
* <tt>null</tt> if there was no mapping for <tt>key</tt>.
* (A <tt>null</tt> return can also indicate that the map
* previously associated <tt>null</tt> with <tt>key</tt>.)
*/
public V remove(Object key) {
Node<K,V> e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}
/**
* Implements Map.remove and related methods
*
* @param hash hash for key
* @param key the key
* @param value the value to match if matchValue, else ignored
* @param matchValue if true only remove if value is equal
* @param movable if false do not move other nodes while removing
* @return the node, or null if none
*/
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null, e; K k; V v;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
else if ((e = p.next) != null) {
if (p instanceof TreeNode)
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
else {
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
// 到这都是getNode一样的
// 下面就是一个链表的删除
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
if (node instanceof TreeNode)
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
else if (node == p)
tab[index] = node.next;
else
p.next = node.next;
++modCount;
--size;
afterNodeRemoval(node);
return node;
}
}
return null;
}
TreeMap
红黑树的结构实现,是一个能比较大小的Map集合,可以按照自然排序,也可以自定义排序
// TODO 后续补充
HashTable
// TODO 后续补充

 浙公网安备 33010602011771号
浙公网安备 33010602011771号