
YOLOv5训练过程
YOLOv5训练过程
1. 数据格式转为YOLOv5需要的格式
YOLOv5需要图像标注的数据格式
大家都知道,用于训练的图片都是有对应的标注信息的,主要来标注图片中的待识别物体(用边界框和类别表示)
在yolov5中每一个图片对应的标注信息(边界框和类别)是存放在txt文件中的,内容如下所示:

每一行5个值,含义依次是类别,真实边界框中心点x坐标,y坐标,宽,高
如果你的数据没有对应的标注文件,那么可以用标注工具进行标注:(可以用labelme或者labelimg,或者yolov5提供的一个网址数据集制作)
如果你有标注文件,但是格式不对的画,比如你是json格式,就需要自己手动编写脚本去转换,或者去网上找别人写好的脚本
这里以一个我的json文件为例,如果有和这个json格式相同的,可能大多数都与这个不同,可以用下面代码进行转换:
{"info":
{"image_name": "5191_1642654681678.jpg"},
"annotations": [{"bbox": [99, 517, 8, 18], "color": "other"}, {"bbox": [113, 519, 9, 17], "color": "other"},
{"bbox": [223, 531, 9, 29], "color": "other"}, {"bbox": [237, 555, 7, 14], "color": "other"}, {"bbox": [382, 564, 6, 12],
"color": "red"}, {"bbox": [325, 484, 10, 28], "color": "other"}, {"bbox": [388, 480, 12, 22], "color": "other"},
{"bbox": [453, 481, 13, 29], "color": "other"}, {"bbox": [721, 555, 7, 17], "color": "other"}, {"bbox": [710, 555, 7, 15],
"color": "other"}, {"bbox": [944, 533, 7, 18], "color": "red"}, {"bbox": [992, 533, 6, 18], "color": "red"},
{"bbox": [1261, 566, 6, 15], "color": "red"}, {"bbox": [801, 565, 6, 15], "color": "other"}, {"bbox": [792, 565, 7, 15],
"color": "other"}, {"bbox": [772, 575, 8, 18], "color": "red"}, {"bbox": [389, 564, 6, 14], "color": "other"}]}
import os
from PIL import Image
import json
import numpy as np
import pandas as pd
# 读取原始的json数据
ant_root_dir = "./traffic_light_data/annotations" # 存放json文件的文件夹
img_root_dir = "./traffic_light_data/images" # 存放图像的文件夹
output_root = "./traffic_light_data/ant_txt" # 存放输出结果的文件夹
json_list = os.listdir(ant_root_dir)
json_dir_list = [os.path.join(ant_root_dir, json_dir) for json_dir in json_list]
def cls_merger_bbox(cls, bbox, size):
"""
这个函数需要你修改一下下面的类别映射,如果类别多的话,用下面的代码则很不好,可以自己改一下
"""
# 转换颜色字符串为类别数字
if cls == 'red':
cls = 0
elif cls == 'green':
cls = 1
elif cls == 'yellow':
cls = 2
else:
cls = 3
# 转换bbox到0-1之间(除以图像宽和高)
# 传入的bbox格式为(边界框中心x,中心y,宽,高)
bbox [0], bbox[2] = bbox[0] / size[0], bbox[2] / size[0]
bbox[1], bbox[3] = bbox[1] / size[1], bbox[3] / size[1]
bbox.insert(0, cls)
bbox = np.around(bbox, decimals=4)
return bbox
for i, json_dir in enumerate(json_dir_list):
# 将json数据转为python字典格式,并读取标注信息
data = json.load(open(json_dir))
ant_list = data['annotations']
image_name = data['info']['image_name']
# 读取json文件对应的图像宽高
image_dir = os.path.join(img_root_dir, image_name)
img = Image.open(image_dir)
size = img.size
# 用数组存取我们的标注信息
ant_yolo_np = np.zeros((len(ant_list), 5))
for i, ant in enumerate(ant_list):
bbox = ant['bbox'] # list
cls = ant['color'] # str
# 将bbox缩放到0-1之间,并把cls转成对应的数字,将两者放在一个列表中
cls_bbox = cls_merger_bbox(cls, bbox, size)
# 放入数组中
ant_yolo_np[i, :] = cls_bbox
output = pd.DataFrame(ant_yolo_np)
output.iloc[:, 0] = output.iloc[:, 0].astype(int)
output_name = os.path.join(output_root, os.path.splitext(image_name)[0]+'.txt')
# np.savetxt(output_name, ant_yolo_np, delimiter=' ', fmt='%.04f')
output.to_csv(output_name, sep=' ', index=False, header=False)
print("转换完毕")
import random
import shutil
"""
下面代码用于划分训练集和验证集
"""
image_list = os.listdir(img_root_dir)
output_list = os.listdir(output_root)
index_list = random.sample(range(len(image_list)), 80)
for i in index_list:
image_name = os.path.join(img_root_dir, image_list[i])
txt_name = os.path.join(output_root, output_list[i])
shutil.move(image_name, './valid_image')
shutil.move(txt_name, './valid_txt')
yolov5需要的数据在文件夹中的位置
你的图像和标注数据应该按照下面的形式放在文件夹中:
datasets
- traffic_light
- images
- train 存放训练图像
- val 存放验证集图像
- labels
- train 存放训练图像对应的标注txt文件
- val 同上
- images
然后将datasets文件夹放到与你下载到的yolov5项目的同级目录下
2.训练时必须修改的文件
创建自己的.yaml文件,里面主要用来配置你的数据的信息,创建位置如下图所示:
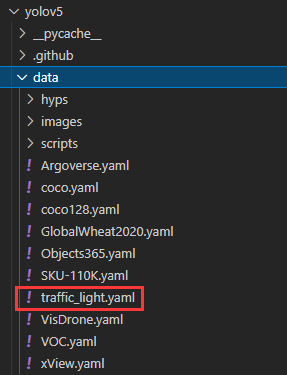
里面的内容如下所示:
主要是把我们刚才放到datasets下的数据集的路径还有训练集合验证集的路径填一下

修改models文件夹下的yolov5*.yaml文件,这个是你后面用于训练的模型配置文件(下图改的是yolov5x.yaml),修改一下类别就行,其他的有能力也可以改:
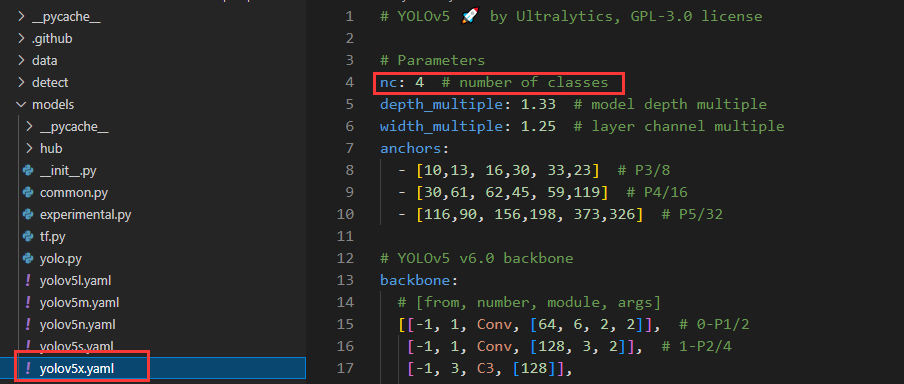
将数据集配置好,并修改以上两个文件后就可以训练啦!
进入yolov5项目文件夹,打开终端,输入下面命令:
python train.py --img 640 --batch 4 --epochs 30 --data ./data/traffic_light.yaml --weights ./weights/yolov5x.pt --cfg ./models/yolov5x.yaml
--img:指的是输入网络的图像尺寸,有两个选择,640和1280--batch:是1个epoch内,一次性喂入网络的数据中包含的图像个数,也就是卷积网络输入数据的第一个纬度(比如[4,3, 640,640]);可以根据你的显存大小进行调整,显存越大可以设置更大,我的就6G,且网络模型很大,所以就设置小一些,不然会报显存不足或者其他错误--epochs:训练网络的次数,一个epoch有图像总数/batch次更新模型的机会,一个epoch进行完之后,说明你的训练数据集已将全部被网路训练一遍了,接下来网络会在验证集上验证目前的网络参数效果如何--data:你的数据集对应的.yaml文件--weights:官方提供的预训练权重,weights文件夹是我自己建的;下载地址:权重下载,进去之后找到Assets字样,如果你的网络比较卡,可以在百度网盘中下载:链接:https://pan.baidu.com/s/1CCmJmx4wCIJcmDahIye2Hw ,权重后面的6表示的是输入图像尺寸为1280分辨率的图像,--cfg也要改成相应的带6的
提取码:iltr--cfg:网络模型对应的文件
正常来说就可以训练了,如果有什么问题可以留言,看到了会回复
训练好之后,会提示你本次训练结果存放在run/train/exp*文件夹下,在该文件夹下的weights文件夹中可以看到本次训练的最好参数和最后一个epoch训练完之后的权重
用你训练好的权重进行测试
执行下面代码:
python detect.py --weights ./runs/train/exp6/weights/best.pt --source ./test.jpg
执行完之后会提示你结果保存在***中
- 下面是
--source参数的值
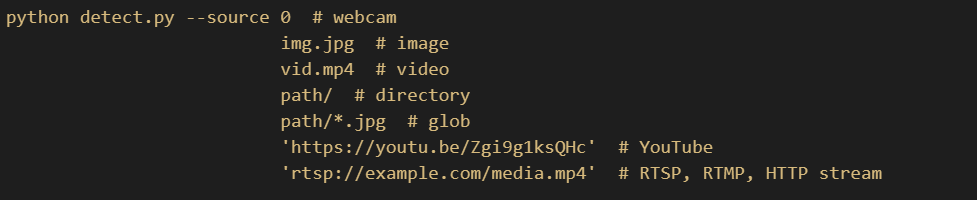
--weights:是你训练好的权重
3.其他
可视化时,更改边界框的粗细
修改学习率等超参数
data文件夹下的hyps文件夹中可以修改各种超参数,-low好像是图像尺寸为640时生效

4.训练结果记录
第一次: 本次用的图像尺寸是640,也就是说会把你输入的图像,进行缩放与随机裁剪等变化,最终用于训练的大小是640;直接用的最大的模型yolov5x,批次刚开始小一些30个,发现mAP一直在上升,因此可以加大批次数,增大一些学习率python train.py --img 640 --batch 4 --epochs 30 --data ./data/traffic_light.yaml --weights ./weights/yolov5x.pt --cfg ./models/yolov5x.yaml |
|---|
 |
测试结果:python detect.py --weights ./runs/train/exp6/weights/best.pt --source ./test.jpg |
第二次: 与第一次相比,只是把初始学习率改为了0.03,然后训练次数增大到100;感觉mAP还有上升空间,下面继续增加训练次数和学习率python train.py --img 640 --batch 4 --epochs 100 --data ./data/traffic_light.yaml --weights ./weights/yolov5x.pt --cfg ./models/yolov5x.yaml |
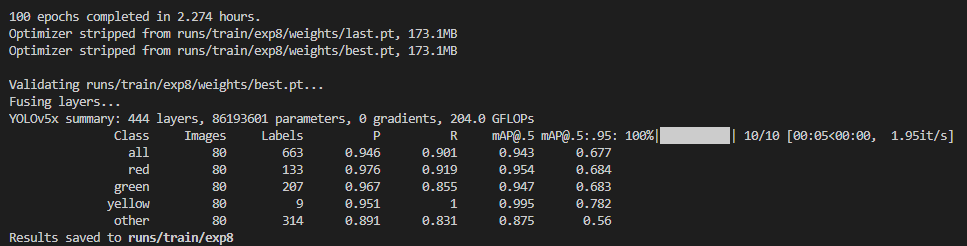 |
python detect.py --weights ./runs/train/exp6/weights/best.pt --source ./detect # 将detect文件夹下的图片都进行测试 |
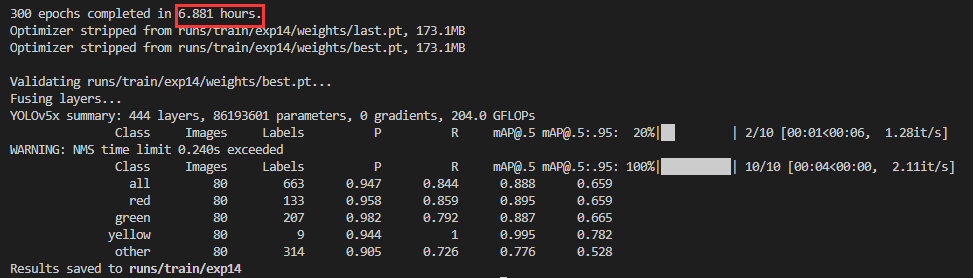
下面是跑了300个epochs的情况,感觉两次结果很接近 |
 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号