


SSD详解
基础模块
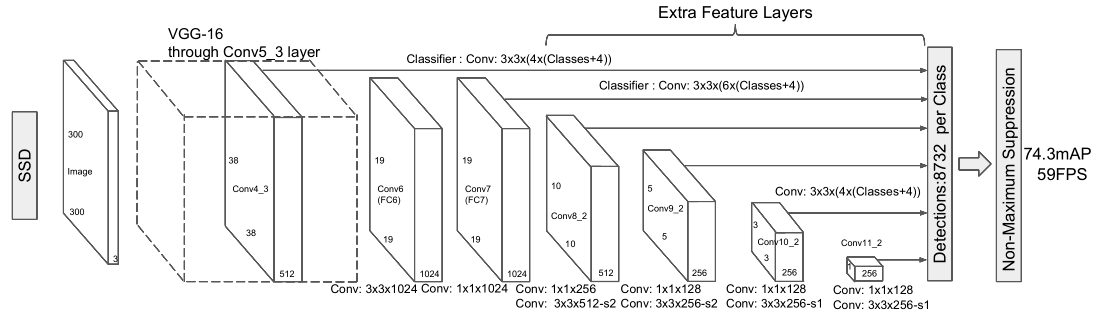
1.类别预测层

2.边界框预测层
和类别预测层类似,只不过每个锚框要预测4个偏移量,而不是个
3.连接多尺度的预测
每个输出的形状是(批量大小,通道数,高度,宽度)
由于不同层的特征图由于大小不一样,锚框数量不一样,因此不同层的预测输出形状可能会不同,通道数由每个特征图单元生成的锚框数量和预测类别决定,高度宽度由每一层特征图尺寸决定。
为了将这每个特征图预测输出链接起来,提高计算效率,我们将把这些输出预测张量转换为更一致的格式:(批量大小,高×宽×通道数)的格式,然后在纬度1上进行拼接。
4.高宽减半块
为了在多个尺度(多尺度指的是锚框有多个尺度,特征图的感受野是多尺度的,然后将这些尺度拼接起来)下检测目标,高宽减半模块将输入特征图的高度和宽度减半,每个高和宽减半块由两个填充为1的3×3的卷积层、以及步幅为2的2×2最大汇聚层组成。
5.基本网络块
用于从输入图像中提取特征,结合高宽减半块一起使用,可以自己构造比如将三个高宽减半快串联起来
6.损失函数和评价函数

6.1.交叉熵损失函数

cls_loss = nn.CrossEntropyLoss(reduction='none') bbox_loss = nn.L1Loss(reduction='none') def calc_loss(cls_preds, cls_labels, bbox_preds, bbox_labels, bbox_masks): batch_size, num_classes = cls_preds.shape[0], cls_preds.shape[2] cls = cls_loss(cls_preds.reshape(-1, num_classes), cls_labels.reshape(-1)).reshape(batch_size, -1).mean(dim=1) bbox = bbox_loss(bbox_preds * bbox_masks, bbox_labels * bbox_masks).mean(dim=1) return cls + bbox
6.2.评价损失函数
沿用准确率评价分类结果。 由于偏移量使用了L1范数损失,我们使用平均绝对误差来评价边界框的预测结果
注意cls_labels和bbox_labels是给每个锚框分配真实边界框,然后类别就是分配的真是边界框的标签,偏移量就是与真实边界框的相对偏移,bbox_masks也是这时候产生的
cls_preds和bbox_preds是我们前向传播时,根据网络模型当前的参数为每个锚框预测出来的
def cls_eval(cls_preds, cls_labels): # 由于类别预测结果放在最后一维,argmax需要指定最后一维。 return float((cls_preds.argmax(dim=-1).type( cls_labels.dtype) == cls_labels).sum()) def bbox_eval(bbox_preds, bbox_labels, bbox_masks): return float((torch.abs((bbox_labels - bbox_preds) * bbox_masks)).sum())
训练阶段
- 搭建模型,输入数据
- 每张图片生成多尺度锚框,模型利用当前参数预测每个锚框的类别和偏移量
- 为每个锚框分配真实边界框并标注类别和偏移量
- 利用交叉熵和L1范数计算类别和偏移量的损失
- 损失反向传播,随机梯度下降更新网络参数
- 开始新一轮的训练
num_epochs, timer = 20, d2l.Timer() animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs], legend=['class error', 'bbox mae']) net = net.to(device) for epoch in range(num_epochs): # 训练精确度的和,训练精确度的和中的示例数 # 绝对误差的和,绝对误差的和中的示例数 metric = d2l.Accumulator(4) net.train() for features, target in train_iter: timer.start() trainer.zero_grad() X, Y = features.to(device), target.to(device) # 生成多尺度的锚框,为每个锚框预测类别和偏移量 anchors, cls_preds, bbox_preds = net(X) # 为每个锚框标注类别和偏移量 bbox_labels, bbox_masks, cls_labels = d2l.multibox_target(anchors, Y) # 根据类别和偏移量的预测和标注值计算损失函数 l = calc_loss(cls_preds, cls_labels, bbox_preds, bbox_labels, bbox_masks) l.mean().backward() # 误差反向传播,计算梯度 trainer.step() # 更新参数 metric.add(cls_eval(cls_preds, cls_labels), cls_labels.numel(), bbox_eval(bbox_preds, bbox_labels, bbox_masks), bbox_labels.numel()) cls_err, bbox_mae = 1 - metric[0] / metric[1], metric[2] / metric[3] animator.add(epoch + 1, (cls_err, bbox_mae)) print(f'class err {cls_err:.2e}, bbox mae {bbox_mae:.2e}') print(f'{len(train_iter.dataset) / timer.stop():.1f} examples/sec on ' f'{str(device)}')
预测阶段
-
通过非极大值抑制来移除相似的预测边界框
-
最后,筛选所有置信度不低于0.9的边界框,做为最终输出


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!