Python 正则表达式
1、从字符串起始位置匹配(一次)
re.match(pattern, string, flags=0)
匹配成功返回匹配对象,否则返回 None
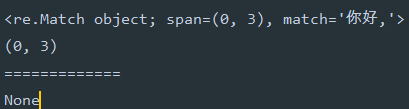
# -*- encoding=utf-8 -*- import re if __name__ == '__main__': pass string = '你好,世界' ret = re.match('你好,', string) print(ret) print(ret.span()) print('=============') ret = re.match('世界', string) print(ret)
运行
2.匹配整个字符串(一次)
re.search(pattern, string, flags=0)
匹配成功返回匹配对象,否则返回 None
# -*- encoding=utf-8 -*-
import re
if __name__ == '__main__':
pass
string = '你好,世界'
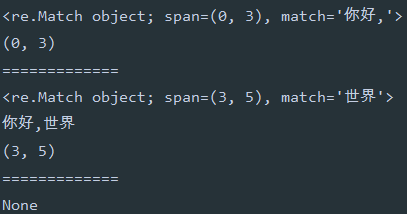
ret = re.search('你好,', string)
print(ret)
print(ret.span())
print('=============')
ret = re.search('世界', string)
print(ret)
print(ret.string)
print(ret.span())
print('=============')
ret = re.search('世界啊', string)
print(ret)
运行
3.替换(多次)
re.sub()
# -*- encoding=utf-8 -*- import re if __name__ == '__main__': pass string = '你好,世界' new = re.sub('你好,', '', string) print(new) new = re.sub(',', '', string) print(new)
运行

4.匹配所有符合条件的字符串(多次)
re.findall()
匹配到返回 list 匹配不到返回空的 list
re.match 和 re.search 是只匹配一次符合条件的,而 findall 匹配所有符合条件。
# -*- encoding=utf-8 -*- import re if __name__ == '__main__': pass string = '你好,世界,你好,世界' print(re.match('你好', string).span()) print(re.search('你好', string).span()) ret = re.findall('你好', string) print(ret)
运行

5.正则表达式对象
re.compile()
返回正则表达式对象
# -*- encoding=utf-8 -*- import re if __name__ == '__main__': pass string = 'AAAA123BBB456CCC789' p = re.compile(r'\d') # 匹配1个数字 ret = p.findall(string) print(ret) # ['1', '2', '3', '4', '5', '6', '7', '8', '9'] p = re.compile(r'\d+') # 匹配1个或多个数字 ret = p.findall(string) print(ret) # ['123', '456', '789'] p = re.compile(r'\w+') # 数字字母下划线 ret = p.findall('VVV111%%DDDD$$##^^45645AAA') print(ret) # ['VVV111', 'DDDD', '45645AAA']
正则表达式可参考 https://www.runoob.com/python3/python3-reg-expressions.html
https://docs.python.org/zh-cn/3/library/re.html
6.贪婪模式和非贪婪模式
(1)贪婪模式
正则表达式中 *表示匹配0个或多个 +表示匹配1个或多个 ?表示匹配0个或一个
他们都会尽最大能力去匹配,这就是贪婪模式
例如'<aaa111><bbb22222><3333dddd>'中找<打头>结尾的,贪婪模式匹配返回 ['<aaa111><bbb22222><3333dddd>']
# -*- encoding=utf-8 -*- import re if __name__ == '__main__': string = '<aaa111><bbb22222><3333dddd>' p = re.compile(r'<.*>') ret = p.findall(string) print(ret) # ['<aaa111><bbb22222><3333dddd>']
(2)非贪婪模式
我理解在 * 或 +后面加上?就是非贪婪模式
这样能尽最小能力去匹配
例如'<aaa111><bbb22222><3333dddd>'中找<打头>结尾的,非贪婪模式匹配返回 ['<aaa111>', '<bbb22222>', '<3333dddd>']
# -*- encoding=utf-8 -*- import re if __name__ == '__main__': string = '<aaa111><bbb22222><3333dddd>' p = re.compile(r'<.*?>') ret = p.findall(string) print(ret) # ['<aaa111>', '<bbb22222>', '<3333dddd>']
(3)再来个例子
{a,b} 表示匹配a个到b个
贪婪模式会匹配最大b个(大于a个小于b个则有几个匹配几个,小于a个则匹配失败,大于b个则匹配b个)
{a,b}?非贪婪模式匹配a个
# -*- encoding=utf-8 -*- import re if __name__ == '__main__': string = 'AAAAAAAAAABBBBAAAAAA' p = re.compile(r'A{3,5}') ret = p.findall(string) print(ret) # ['AAAAA', 'AAAAA', 'AAAAA'] p1 = re.compile(r'A{3,5}?') ret = p1.findall(string) print(ret)# ['AAA', 'AAA', 'AAA', 'AAA', 'AAA']
7.分组
group()
正则表达式中用括号就表示分组(),一个()一个分组,通过group(index)获取
# -*- encoding=utf-8 -*- import re if __name__ == '__main__': string = 'afafafABBB % DFF1234578' p = re.compile(r'AB+(.%S?)(.[A-Z]+)\d+') ret = p.search(string) print(ret) print(ret.group(0)) # 默认整个匹配值 print(ret.group(1)) # 第一个分组 print(ret.group(2)) # 第二个分组
运行
<re.Match object; span=(6, 23), match='ABBB % DFF1234578'> ABBB % DFF1234578 % DFF
如果下标过多,可以指定名字使用 (?P<name>) 来实现
# -*- encoding=utf-8 -*- import re if __name__ == '__main__': string = 'afafafABBB % DFF1234578' p = re.compile(r'AB+(?P<one>.%S?)(?P<two>.[A-Z]+)\d+') ret = p.search(string) print(ret) print(ret.group(0)) # 默认整个匹配值 print(ret.group(1)) # 第一个分组 print(ret.group(2)) # 第二个分组 print(ret.group('one')) # 第一个分组 print(ret.group('two')) # 第二个分组
运行
<re.Match object; span=(6, 23), match='ABBB % DFF1234578'> ABBB % DFF1234578 % DFF % DFF

 浙公网安备 33010602011771号
浙公网安备 33010602011771号