Python selenium爬虫
1、下载selenium
采取python -m pip install selenium即可
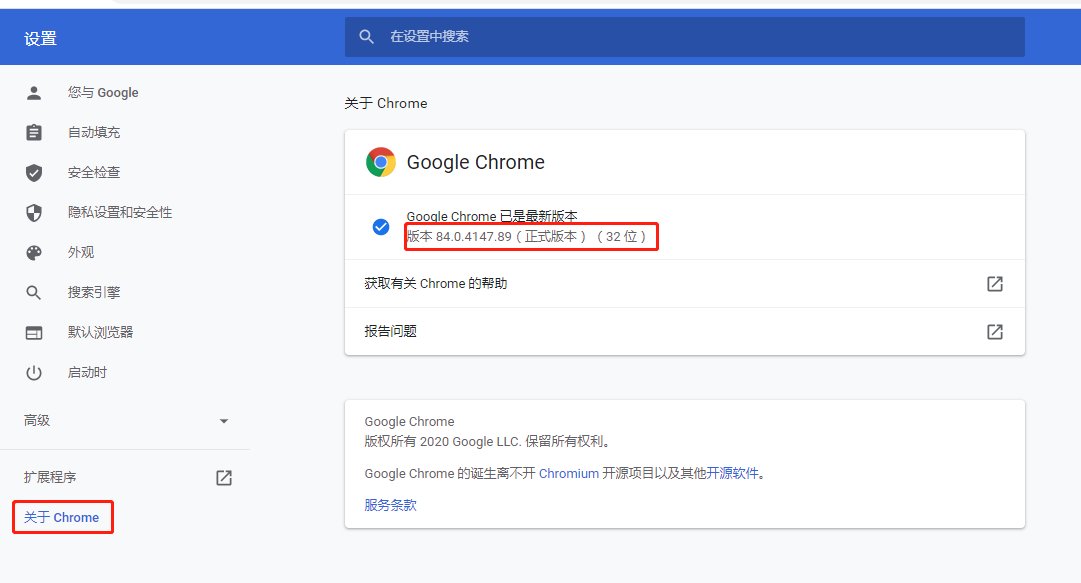
2、下载谷歌驱动
查看自己谷歌的版本,下载对应驱动即可
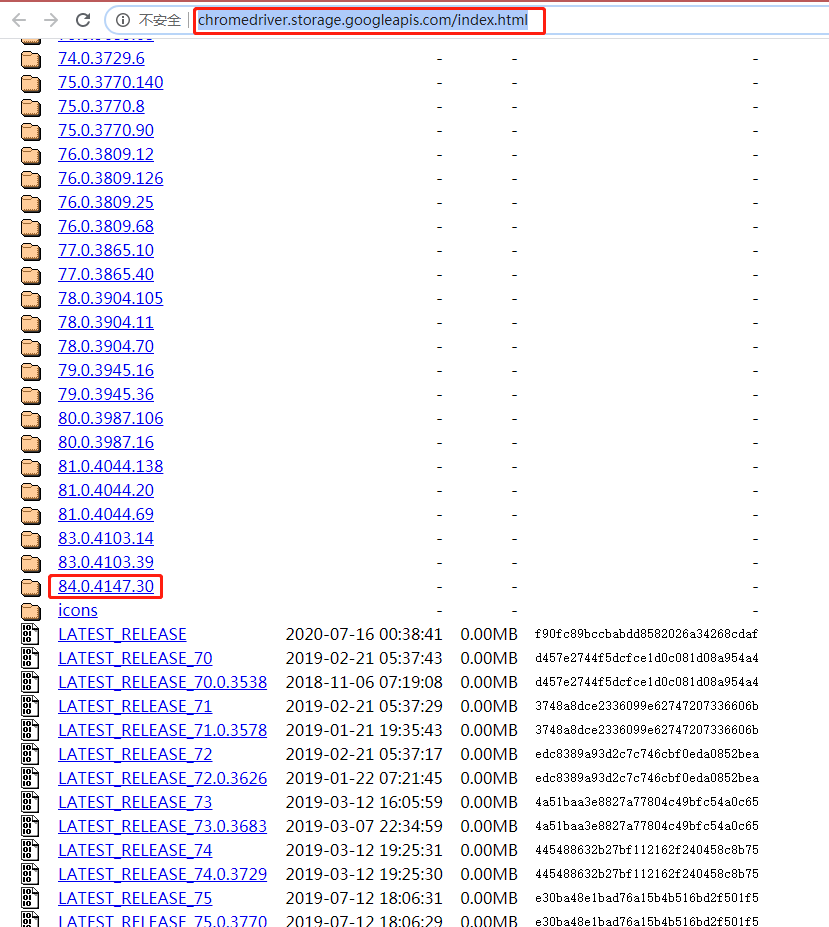
驱动网址:http://chromedriver.storage.googleapis.com/index.html
补充官网地址: https://getwebdriver.com/
下载后配置环境变量(文件名:chromedriver.exe)
3、webdriver.get()爬取网页
# -*- encoding=utf-8 -*- from selenium import webdriver if __name__ == '__main__': url = 'https://movie.douban.com/' web = webdriver.Chrome() web.get(url) print(web.page_source) web.quit()
此时会自动打开谷歌浏览器进行爬取。
PS:程序会一直等待整个页面加载完成,也就是那个小圈圈一直在转(网不好的情况),转到停的时候才会继续执行。
4、不显示浏览器进行爬取
# -*- encoding=utf-8 -*- from selenium import webdriver from selenium.webdriver.chrome.options import Options if __name__ == '__main__': url = 'https://movie.douban.com/' options = Options() options.add_argument('--headless') # 不显示浏览器 web = webdriver.Chrome(options=options) web.get(url) print(web.page_source) web.quit()
PS:此时有可能获取的html源码与不加'--headless'时获取的不相同,个人分析原因可能是由于不加'--headless'时,程序等待页面加载完成才继续执行,而加了以后没等待页面加载完成,也许只等待了一个默认时间就返回了。
5、隐形等待
获取元素时会出现没找到该元素,此时是因为该元素还没有加载出来,所以需要等待一会再查找元素。
# -*- encoding=utf-8 -*- from selenium import webdriver from selenium.webdriver.chrome.options import Options if __name__ == '__main__': url = 'https://movie.douban.com/' options = Options() options.add_argument('--headless') # 不显示浏览器 web = webdriver.Chrome(options=options) web.implicitly_wait(5) # 隐式等待5秒 web.get(url) all_elements = web.find_elements_by_xpath( '//*[@id="content"]/div/div[2]/div[3]/div[3]/div/div[1]/div/div[2]/a[1]/p') print(len(all_elements)) for element in all_elements: print(element.text) web.quit()
PS:转载来自https://huilansame.github.io/huilansame.github.io/archivers/sleep-implicitlywait-wait
隐形等待是设置了一个最长等待时间,如果在规定时间内网页加载完成,则执行下一步,否则一直等到时间截止,然后执行下一步。注意这里有一个弊端,那就是程序会一直等待整个页面加载完成,也就是一般情况下你看到浏览器标签栏那个小圈不再转,才会执行下一步,但有时候页面想要的元素早就在加载完成了,但是因为个别js之类的东西特别慢,我仍得等到页面全部完成才能执行下一步,我想等我要的元素出来之后就下一步怎么办?有办法,这就要看selenium提供的另一种等待方式——显性等待wait了。
需要特别说明的是:隐性等待对整个driver的周期都起作用,所以只要设置一次即可
运行结果
灰猎犬号 8.3
6、显示等待
# -*- encoding=utf-8 -*- from selenium import webdriver from selenium.webdriver.chrome.options import Options from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC if __name__ == '__main__': url = 'https://movie.douban.com/' options = Options() options.add_argument('--headless') # 不显示浏览器 web = webdriver.Chrome(options=options) web.get(url) try: element = WebDriverWait(web, 5).until( EC.presence_of_element_located((By.XPATH, '//*[@id="content"]/div/div[2]/div[3]/div[3]/div/div[1]/div/div[2]/a[1]/p'))) print(element.text) except Exception as e: print('异常:{}'.format(e)) web.quit()
运行结果
灰猎犬号 8.3
7、获取标题
# -*- encoding=utf-8 -*- from selenium import webdriver from selenium.webdriver.chrome.options import Options if __name__ == '__main__': url = 'https://movie.douban.com/' options = Options() options.add_argument('--headless') # 不显示浏览器 web = webdriver.Chrome(options=options) web.implicitly_wait(5) # 隐式等待5秒 web.get(url) all_elements = web.find_elements_by_xpath( '//*[@id="content"]/div/div[2]/div[3]/div[3]/div/div[1]/div/div[2]') for element in all_elements: for i in element.find_elements_by_tag_name('a'): for j in i.find_elements_by_tag_name('p'): print(j.text) web.quit()
运行结果
灰猎犬号 8.3 永生守卫 6.3 不可抗拒 7.3 清白 6.8 霍家拳之铁臂娇娃 6.0 性之剧毒 5.9 前哨 7.0 猎谎者 6.8 翻译疑云 7.3 侵入者 6.5
8、模拟切换Frame和输入以及点击
# -*- encoding=utf-8 -*- from selenium import webdriver if __name__ == '__main__': web = webdriver.Chrome() web.get('https://qzone.qq.com/') web.switch_to.frame('login_frame') web.find_element_by_id('switcher_plogin').click() web.find_element_by_id('u').send_keys('1150646501') web.find_element_by_id('p').send_keys('txh0916@TXH') web.find_element_by_id('login_button').click() pass web.quit()#关闭所有页面和驱动
#web.close()关闭当前页面

 浙公网安备 33010602011771号
浙公网安备 33010602011771号