Python requests+BeautifulSoup爬虫(下载图片)
1、导入库
import requests from bs4 import BeautifulSoup
2、下载图片流程
【网址https://wall.alphacoders.com/】【若有侵权,请联系1150646501@qq.com,立马删除】
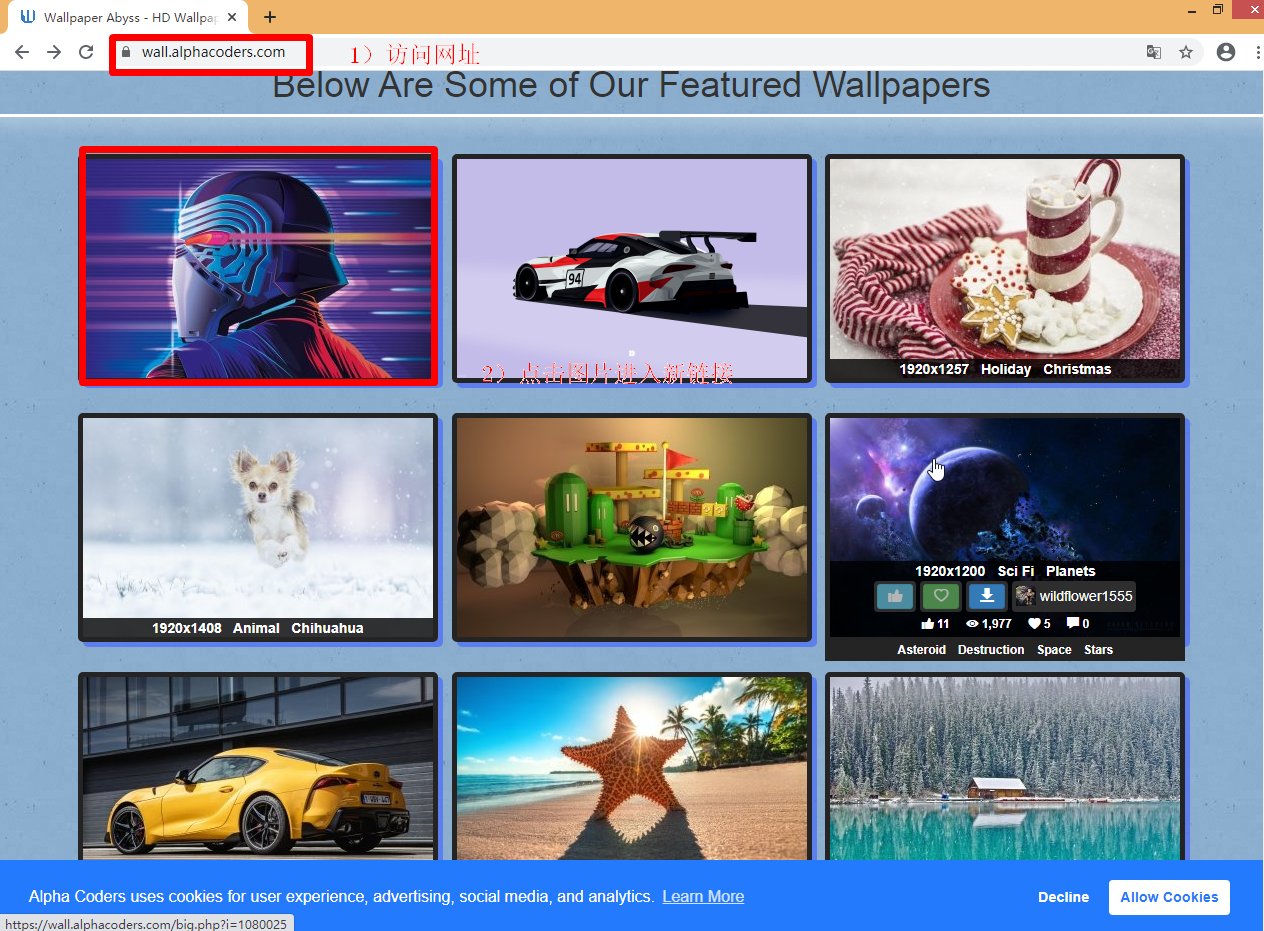
正常手动下载图片流程
1)访问https://wall.alphacoders.com/
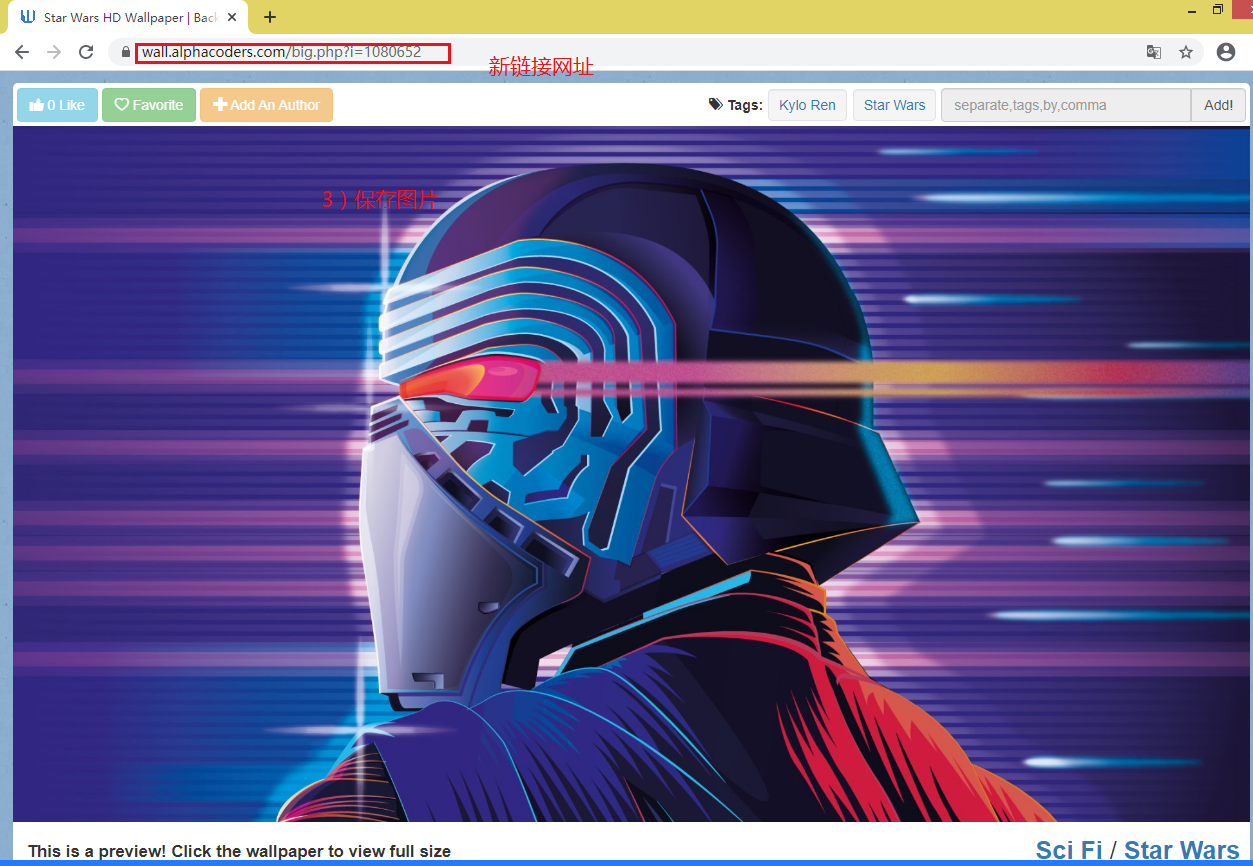
2)点击图片进入新的链接
3)保存图片
python代码下载流程
1)获取https://wall.alphacoders.com/网页源代码
2)找到图片点击后对应链接(假设为xxx)
3)获取xxx网页源代码(假设为yyy)
4)找到yyy中图片链接(假设为zzz.jpg)
5)下载图片
【代码如下】
1)获取https://wall.alphacoders.com/网页源代码
# -*- encoding=utf-8 -*-
import requests
from bs4 import BeautifulSoup
# 获取网页源代码
def get_html(url='https://wall.alphacoders.com/'):
ret = requests.get(url)
# 获取返回的状态 200表示请求成功
print ret.status_code
html = ret.text
# 网页源代码
# print html
return html
if __name__ == '__main__':
pass
2)找到图片点击后对应链接(假设为xxx)
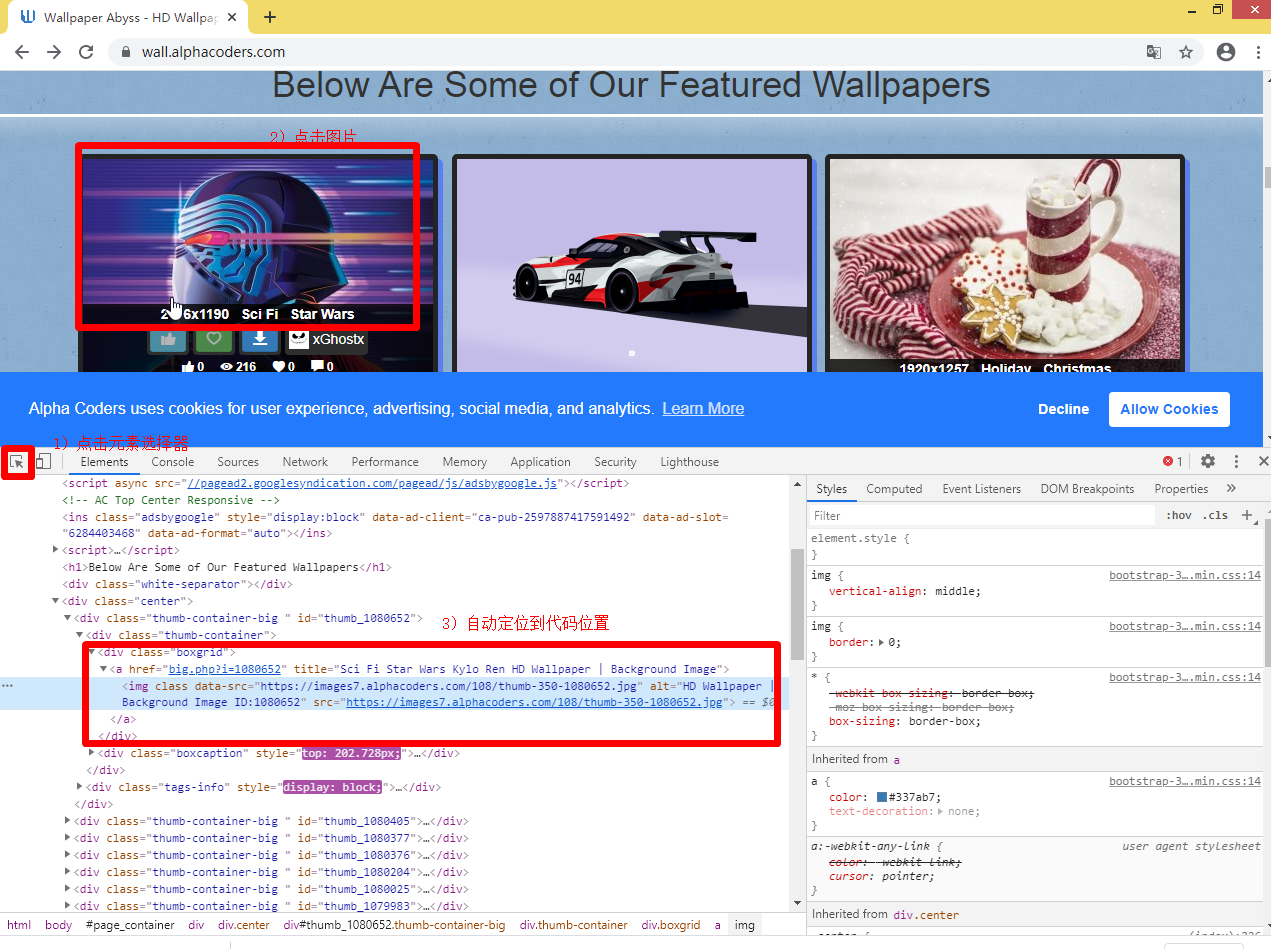
通过查看网页源代码可以发现,每组图片是这样子的
所以我们可以通过查找class="boxgrid"的所有div,然后取a中的href。
其中也有https://images7.alphacoders.com/108/thumb-350-1080652.jpg的网址,但是点进去看是小图片。我们需要下载大图片。
href还需要把基础地址加上才可以,把big.php?i=1080652变成https://wall.alphacoders.com/big.php?i=1080652
PS:可以使用F12,然后定位图片,然后选择图片找到对应的html代码就能找到规律
# -*- encoding=utf-8 -*-
import requests
from bs4 import BeautifulSoup
# 获取网页源代码
def get_html(url='https://wall.alphacoders.com/'):
ret = requests.get(url)
# 获取返回的状态 200表示请求成功
print ret.status_code
html = ret.text
# 网页源代码
# print html
return html
# 获取链接
def get_photo_link(html):
# 用来存放链接
links = []
soup = BeautifulSoup(html, features='lxml')
# 找到所有class_='boxgrid'的div
all_div = soup.find_all('div', class_='boxgrid')
for div in all_div:
# 取到href的值
href = div.a.attrs['href']
# 添加原地址组成真正url
links.append('https://wall.alphacoders.com/' + href)
return links
if __name__ == '__main__':
html = get_html()
links = get_photo_link(html)
for link in links:
print link
PS:BeautifulSoup使用可以参考https://cuiqingcai.com/1319.html
运行
https://wall.alphacoders.com/big.php?i=1080652
https://wall.alphacoders.com/big.php?i=1080635
https://wall.alphacoders.com/big.php?i=1080566
https://wall.alphacoders.com/big.php?i=1080405
https://wall.alphacoders.com/big.php?i=1080377
https://wall.alphacoders.com/big.php?i=1080376
https://wall.alphacoders.com/big.php?i=1080204
https://wall.alphacoders.com/big.php?i=1080025
https://wall.alphacoders.com/big.php?i=1079983
https://wall.alphacoders.com/big.php?i=1079969
https://wall.alphacoders.com/big.php?i=1079911
https://wall.alphacoders.com/big.php?i=1079838
https://wall.alphacoders.com/big.php?i=1079806
https://wall.alphacoders.com/big.php?i=1079738
https://wall.alphacoders.com/big.php?i=1079732
https://wall.alphacoders.com/big.php?i=1079731
https://wall.alphacoders.com/big.php?i=1079579
https://wall.alphacoders.com/big.php?i=1079360
https://wall.alphacoders.com/big.php?i=1079302
https://wall.alphacoders.com/big.php?i=1079174
https://wall.alphacoders.com/big.php?i=1079169
https://wall.alphacoders.com/big.php?i=1078982
https://wall.alphacoders.com/big.php?i=1078682
https://wall.alphacoders.com/big.php?i=1078534
https://wall.alphacoders.com/big.php?i=1078068
https://wall.alphacoders.com/big.php?i=1078043
https://wall.alphacoders.com/big.php?i=1077847
https://wall.alphacoders.com/big.php?i=1077792
https://wall.alphacoders.com/big.php?i=1077568
https://wall.alphacoders.com/big.php?i=1077530
3)4)获取xxx网页源代码(假设为yyy)以及找到yyy中图片链接(假设为zzz.jpg)
# -*- encoding=utf-8 -*- import requests from bs4 import BeautifulSoup # 获取网页源代码 def get_html(url='https://wall.alphacoders.com/'): ret = requests.get(url) # 获取返回的状态 200表示请求成功 print ret.status_code html = ret.text # 网页源代码 # print html return html # 获取链接 def get_photo_link(html): # 用来存放链接 links = [] soup = BeautifulSoup(html, features='lxml') # 找到所有class_='boxgrid'的div all_div = soup.find_all('div', class_='boxgrid') for div in all_div: # 取到href的值 href = div.a.attrs['href'] # 添加原地址组成真正url links.append('https://wall.alphacoders.com/' + href) return links # 获取每一个链接的html以及找到对应图片的链接 def get_img_url(links): img_urls = [] for link in links: html = get_html(link) img_soup = BeautifulSoup(html, features='lxml') all_img = img_soup.find_all('img', class_='main-content') for img in all_img: img_url = img.attrs['src'] img_urls.append(img_url) return img_urls if __name__ == '__main__': html = get_html() links = get_photo_link(html) img_urls = get_img_url(links) for img_url in img_urls: print img_url
运行
https://images7.alphacoders.com/108/thumb-1920-1080652.jpg https://images7.alphacoders.com/108/thumb-1920-1080635.jpg https://images8.alphacoders.com/108/thumb-1920-1080566.jpg https://images6.alphacoders.com/108/thumb-1920-1080507.jpg https://images.alphacoders.com/108/thumb-1920-1080405.png https://images8.alphacoders.com/108/thumb-1920-1080377.jpg https://images4.alphacoders.com/108/thumb-1920-1080376.jpg https://images.alphacoders.com/108/thumb-1920-1080204.jpg https://images4.alphacoders.com/108/thumb-1920-1080025.jpg https://images8.alphacoders.com/107/thumb-1920-1079983.jpg https://images6.alphacoders.com/107/thumb-1920-1079969.jpg https://images4.alphacoders.com/107/thumb-1920-1079911.jpg https://images6.alphacoders.com/107/thumb-1920-1079838.jpg https://images6.alphacoders.com/107/thumb-1920-1079806.jpg https://images8.alphacoders.com/107/thumb-1920-1079738.jpg https://images.alphacoders.com/107/thumb-1920-1079732.jpg https://images2.alphacoders.com/107/thumb-1920-1079731.jpg https://images6.alphacoders.com/107/thumb-1920-1079579.jpg https://images7.alphacoders.com/107/thumb-1920-1079360.jpg https://images6.alphacoders.com/107/thumb-1920-1079302.jpg https://images6.alphacoders.com/107/thumb-1920-1079174.jpg https://images3.alphacoders.com/107/thumb-1920-1079169.jpg https://images7.alphacoders.com/107/thumb-1920-1078982.png https://images4.alphacoders.com/107/thumb-1920-1078682.jpg https://images.alphacoders.com/107/thumb-1920-1078534.jpg https://images4.alphacoders.com/107/thumb-1920-1078068.jpg https://images5.alphacoders.com/107/thumb-1920-1078043.jpg https://images3.alphacoders.com/107/thumb-1920-1077847.png https://images2.alphacoders.com/107/thumb-1920-1077792.jpg https://images4.alphacoders.com/107/thumb-1920-1077568.jpg
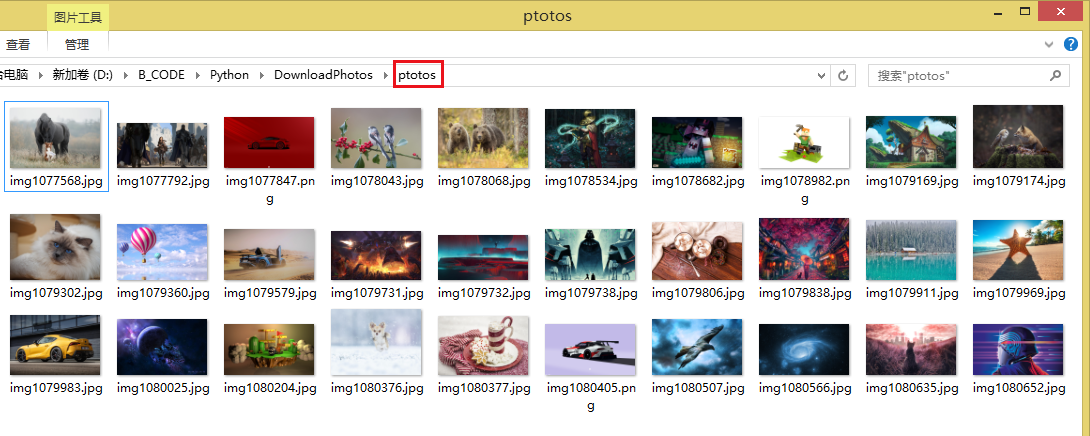
5)下载图片
# -*- encoding=utf-8 -*- import os import requests from bs4 import BeautifulSoup # 获取网页源代码 def get_html(url='https://wall.alphacoders.com/'): ret = requests.get(url) # 获取返回的状态 200表示请求成功 print ret.status_code html = ret.text # 网页源代码 # print html return html # 获取链接 def get_photo_link(html): # 用来存放链接 links = [] soup = BeautifulSoup(html, features='lxml') # 找到所有class_='boxgrid'的div all_div = soup.find_all('div', class_='boxgrid') for div in all_div: # 取到href的值 href = div.a.attrs['href'] # 添加原地址组成真正url links.append('https://wall.alphacoders.com/' + href) return links # 获取每一个链接的html以及找到对应图片的链接 def get_img_url(links): img_urls = [] for link in links: html = get_html(link) img_soup = BeautifulSoup(html, features='lxml') all_img = img_soup.find_all('img', class_='main-content') for img in all_img: img_url = img.attrs['src'] img_urls.append(img_url) return img_urls # 文件夹不存在就创建 def create_folder(file_name): path = os.path.split(file_name)[0] if path != '' and not os.path.exists(path): os.makedirs(path) # 下载图片 def download_img(img_urls): for img_url in img_urls: # 后缀名 save_name_suffix = img_url[-3:] # 保存的名字 save_name = 'ptotos/img.{}'.format(save_name_suffix) ret = requests.get(img_url) # 图片信息 info = ret.content # 不存在文件就创建 create_folder(save_name) # 二进制方式写入 with open(save_name, 'wb') as f: f.write(info) if __name__ == '__main__': html = get_html() links = get_photo_link(html) img_urls = get_img_url(links) download_img(img_urls) print 'End'
运行后
6、遇到乱码处理以及添加请求头
# -*- coding: utf-8 -*- import requests headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:57.0) Gecko/20100101 Firefox/57.0'} url = 'http://sports.sina.com.cn/g/premierleague/index.shtml' ret = requests.get(url, headers=headers) print(ret.status_code) ret.encoding = 'utf-8' print(ret.text)
7、需要json数据时
# -*- coding: utf-8 -*- import json import requests headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:57.0) Gecko/20100101 Firefox/57.0'} data = {'key1': 'value1', 'key2': 'value2'} url = 'http://sports.sina.com.cn/g/premierleague/index.shtml' ret = requests.get(url, headers=headers, data=json.dumps(data)) # ret = requests.post(url, json=data) # 使用post需要json参数时 print(ret.status_code) ret.encoding = 'utf-8' print(ret.text)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号