科技报告数据语料处理(关键词、中图分类名称)
科技报告语料处理
接着上次爬取到的科技报告数据进行处理【参考 https://www.cnblogs.com/rainbow-1/p/16725576.html】
为了建立科技报告的分类模型,现将其关键字和中图分类名称进行汇总,作为原始语料库。
先前爬取的数据,存在数据格式不统一不规范的问题,比如分类名称为【数理科学与化学、数理科学和化学 分为了同一类】
经过简单处理后的完整数据(mysql和txt都有,包括本文中提到的原始语料资源)可以关注我的公众号【靠谱杨阅读人生】回复【科技报告】获取。
语料共计 359141 行。
1、标准表
分类字母序号+名称 tech_class.json
{
"R": "医药、卫生",
"TB": "一般工业技术",
"Q": "生物科学",
"O": "数理科学和化学",
"S": "农业科学",
"T": "工业技术",
"TP": "自动化技术、计算机技术",
"P": "天文学、地球科学",
"TN": "无线电电子学、电信技术",
"TG": "金属学与金属工艺",
"TH": "机械、仪表工业",
"TQ": "化学工业",
"C": "社会科学总论",
"X": "环境科学、安全科学",
"TU": "建筑科学",
"TS": "轻工业、手工业",
"TK": "能源与动力工程",
"TM": "电工技术",
"TD": "矿业工程",
"F": "经济",
"G": "文化、科学、教育、体育",
"TV": "水利工程",
"U": "交通运输",
"N": "自然科学总论",
"TE": "石油、天然气工业",
"TF": "冶金工业",
"TJ": "武器工业",
"V": "航空、航天",
"B": "哲学、宗教",
"TL": "原子能技术",
"K": "历史、地理",
"D": "政治、法律",
"J": "艺术",
"H": "语言、文字",
"E": "军事",
"Z": "综合性图书",
"I": "文学",
"A": "mks主义、ln主义、mzd思想、dxp理论"
}
仅分类名称 tech_name.txt
医药、卫生
一般工业技术
生物科学
数理科学和化学
农业科学
工业技术
自动化技术、计算机技术
天文学、地球科学
无线电电子学、电信技术
金属学与金属工艺
机械、仪表工业
化学工业
社会科学总论
环境科学、安全科学
建筑科学
轻工业、手工业
能源与动力工程
电工技术
矿业工程
经济
文化、科学、教育、体育
水利工程
交通运输
自然科学总论
石油、天然气工业
冶金工业
武器工业
航空、航天
哲学、宗教
原子能技术
历史、地理
政治、法律
艺术
语言、文字
军事
综合性图书
文学
mks主义、ln主义、mzd思想、dxp理论
分类名称+语料数字序号 tech_order_class.json
{
"医药、卫生": "0",
"一般工业技术": "1",
"生物科学": "2",
"数理科学和化学": "3",
"农业科学": "4",
"工业技术": "5",
"自动化技术、计算机技术": "6",
"天文学、地球科学": "7",
"无线电电子学、电信技术": "8",
"金属学与金属工艺": "9",
"机械、仪表工业": "10",
"化学工业": "11",
"社会科学总论": "12",
"环境科学、安全科学": "13",
"建筑科学": "14",
"轻工业、手工业": "15",
"能源与动力工程": "16",
"电工技术": "17",
"矿业工程": "18",
"经济": "19",
"文化、科学、教育、体育": "20",
"水利工程": "21",
"交通运输": "22",
"自然科学总论": "23",
"石油、天然气工业": "24",
"冶金工业": "25",
"武器工业": "26",
"航空、航天": "27",
"哲学、宗教": "28",
"原子能技术": "29",
"历史、地理": "30",
"政治、法律": "31",
"艺术": "32",
"语言、文字": "33",
"军事": "34",
"综合性图书": "35",
"文学": "36",
"mks主义、ln主义、mzd思想、dxp理论": "37"
}
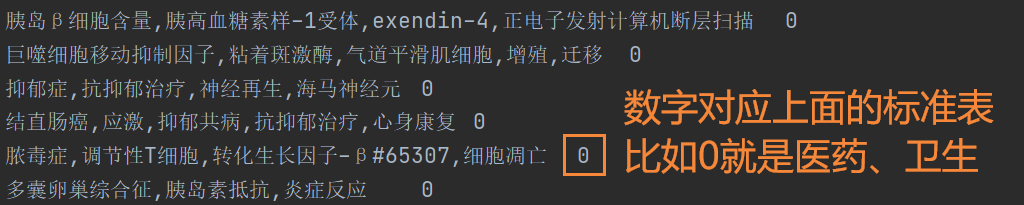
基本思路,提取各个分类报告中的【关键词和中图分类名称】。用 \t 分隔 关键词和名称,关键词中间用英文逗号分隔。
实现效果如图:【序号是从0开始的 0 ---> 医药、卫生】
2、代码
2.1、data_clean.py
提取关键词和名称,保存到tech_all.txt文件(数据库如文首所示方式关注公众号自行获取)
import json
from nlp_demo.tech_clean.utils_mysql import query
def get_class_json():
f_class = open ("../tech_data/tech_name.txt", "r", encoding='utf-8')
res_dict = {}
while True:
line = f_class.readline()
if line:
# print(line)
# 按\t分隔 分开名称和序号
temp_str_list = line.split("\t")
class_name = str(temp_str_list[0])
class_num = str(temp_str_list[1].replace("\n",""))
res_dict[class_name] = class_num
# print("-------------------------")
else:
break
print(json.dumps(res_dict,ensure_ascii=False))
class_json = json.dumps(res_dict,ensure_ascii=False)
with open("../tech_data/tech_order_class.json", "w", encoding='utf-8') as f:
f.write(class_json) # 自带文件关闭功能,不需要再写f.close()
f_class.close()
return
# 处理语料
"""
处理训练集数据格式【tech_train.txt】
关键词(使用英文逗号分隔) \t 分类号(从0开始)
-----
分类名称表【tech_name.txt】
分类名称 \t 分类号(从0开始)
"""
def get_tech_data():
with open("../tech_data/tech_class.json", "r", encoding='utf-8') as fo:
# print(fo.read())
table_name = json.loads(fo.read()) # json 转 字典
with open("../tech_data/tech_order_class.json", "r", encoding='utf-8') as fo_1:
# print(fo.read())
tech_class = json.loads(fo_1.read()) # json 转 字典
# print(table_name)
# 使用上面的数据 拼接字符串 拼接表名 k 是字母号 v 是名称
for k,v in table_name.items():
order_num = None # 根据名称找到对应的数字序号
if(k == None or v == None):
continue
for k1, v1 in tech_class.items():
# k1 是名称 v1 是数字序号
if(v == k1):
order_num = v1 # 给序号赋值
print("正在处理的类别: " + k , v)
k = str(k)
v = str(v)
sql = "select * from tech_"+ k
# print("这是sql语句: " + sql)
# 第7个位置是 中文关键词 第16个位置是中图分类名称
res_one_class = query(sql)
for res_one_class_item in res_one_class:
keywordsCn = str(res_one_class_item[7])
classification = str(order_num)
with open("../tech_res_data/tech_all" + ".txt","a+",encoding='utf-8') as fw:
keywordsCn = keywordsCn.replace(";",",")
keywordsCn = keywordsCn.replace(";",",")
keywordsCn = keywordsCn.replace(",,","")
keywordsCn = keywordsCn.replace(",",",")
print(keywordsCn + " --------> " + classification)
fw.write( keywordsCn + "\t" + classification + "\n")
print("============= 这是分隔符 =============")
return 0
if __name__ == '__main__':
# get_class_json() # 生成json格式的分类名称文件
get_tech_data()
2.2、utils_mysql.py
import pymysql
"""
------------------------------------------------------------------------------------
"""
def get_conn():
"""
:return: 连接,游标
"""
# 创建连接
conn = pymysql.connect(host="127.0.0.1",
user="root",
password="reliable",
db="tech",
charset="utf8")
# 创建游标
cursor = conn.cursor() # 执行完毕返回的结果集默认以元组显示
return conn, cursor
def close_conn(conn, cursor):
if cursor:
cursor.close()
if conn:
conn.close()
"""
-----------------------------------------------------------
"""
"""
------------------------------------------------------------------------------------
"""
def query(sql,*args):
"""
通用封装查询
:param sql:
:param args:
:return:返回查询结果 ((),())
"""
conn , cursor= get_conn()
print(sql)
cursor.execute(sql)
res = cursor.fetchall()
close_conn(conn , cursor)
return res
好看请赞,养成习惯:) 本文来自博客园,作者:靠谱杨, 转载请注明原文链接:https://www.cnblogs.com/rainbow-1/p/16801120.html
欢迎来我的51CTO博客主页踩一踩 我的51CTO博客
文章中的公众号名称可能有误,请统一搜索:靠谱杨的秘密基地

 浙公网安备 33010602011771号
浙公网安备 33010602011771号