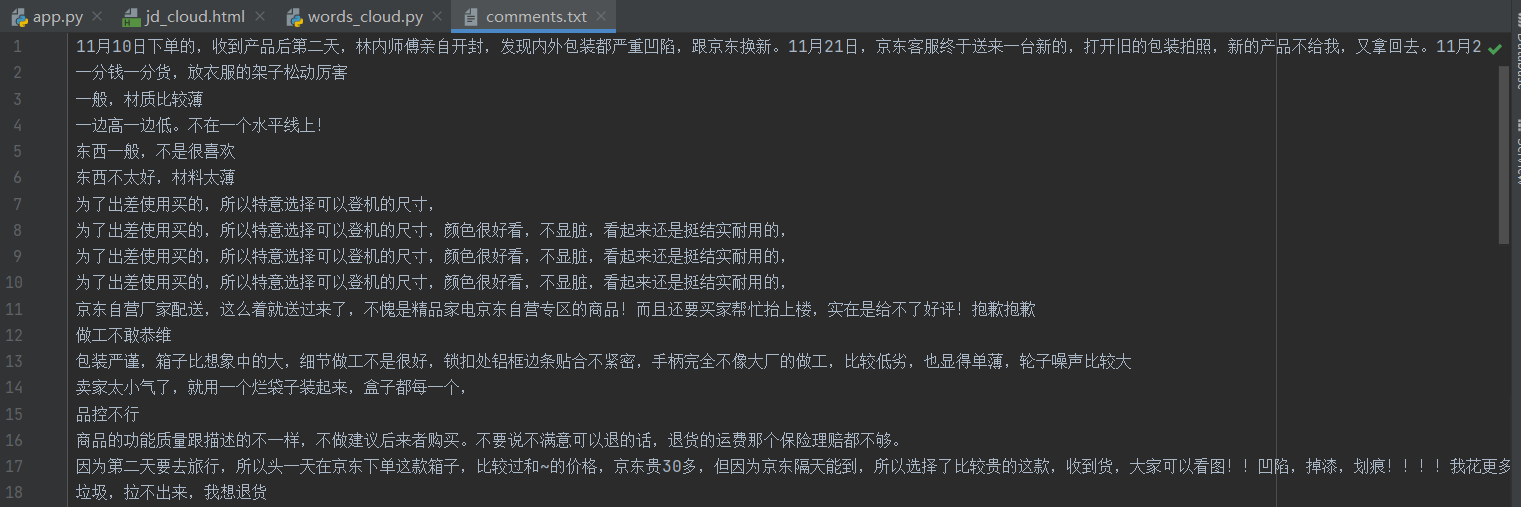
python结巴分词及词频统计
1 def get_words(txt):
2 seg_list = jieba.cut(txt)
3 c = Counter()
4 for x in seg_list:
5 if len(x) > 1 and x != '\r\n':
6 c[x] += 1
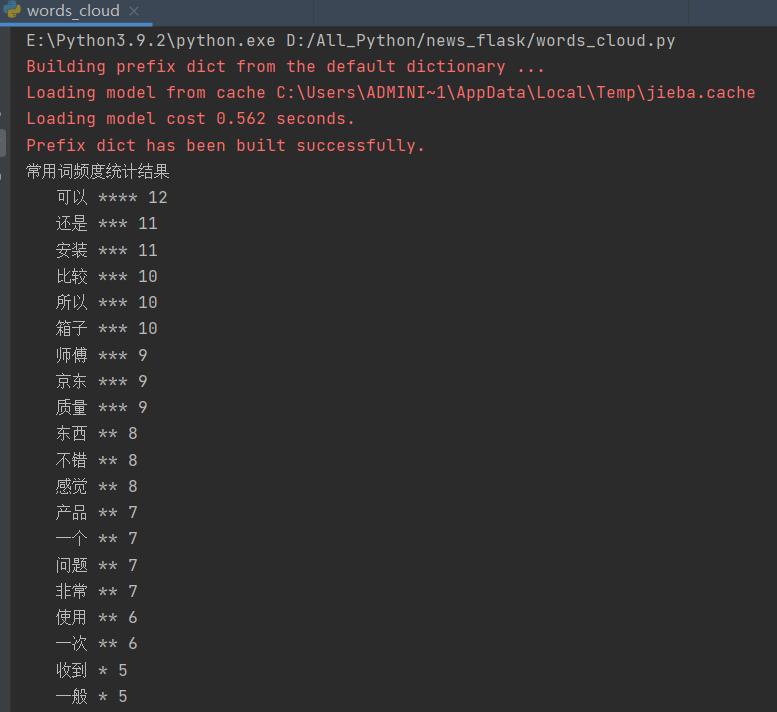
7 print('常用词频度统计结果')
8 for (k, v) in c.most_common(30):
9 print('%s%s %s %d' % (' ' * (5 - len(k)), k, '*' * int(v / 3), v))
10
11 if __name__ == '__main__':
12 with codecs.open('comments.txt', 'r', 'gbk') as f:
13 txt = f.read()
14 get_words(txt)
15 # get_text()
def get_words(txt):
seg_list = jieba.cut(txt)
c = Counter()
for x in seg_list:
if len(x) > 1 and x != '\r\n':
c[x] += 1
print('常用词频度统计结果')
for (k, v) in c.most_common(30):
print('%s%s %s %d' % (' ' * (5 - len(k)), k, '*' * int(v / 3), v))
if __name__ == '__main__':
with codecs.open('comments.txt', 'r', 'gbk') as f:
txt = f.read()
get_words(txt)
# get_text()
好看请赞,养成习惯:) 本文来自博客园,作者:靠谱杨, 转载请注明原文链接:https://www.cnblogs.com/rainbow-1/p/16010853.html
欢迎来我的51CTO博客主页踩一踩 我的51CTO博客
文章中的公众号名称可能有误,请统一搜索:靠谱杨的秘密基地

 浙公网安备 33010602011771号
浙公网安备 33010602011771号