MySQL索引Innodb存储引擎
MySQL索引优化
一、基础理解
MySQL语句的查询效率主要和索引树的高度有关,想要降低查询的次数提高查询的速度,减少直接对磁盘的I/O流的次数,就要让索引树的高度越低越好。
索引的定义:索引是帮助MySQL高效获取数据的排好序的数据结构。
1、innodb存储引擎
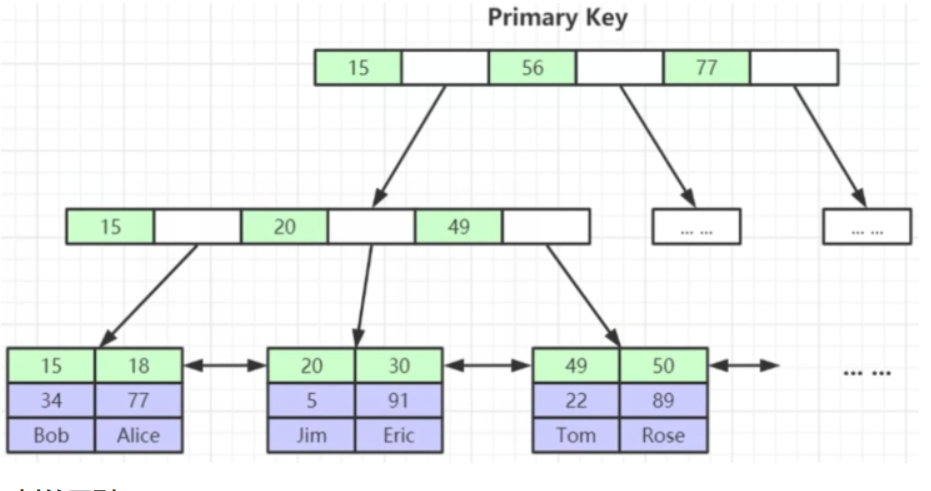
- 使用B+树,表数据文件本身就是按B+Tree组织的一个索引结构文件。
- 聚集索引---叶子节点包含了完整的数据记录。
1.1、B+树和B树的区别
- 非叶子节点不存储data,只存储冗余索引,可以放更多的索引
- 叶子节点包含所有的索引字段。
- 叶子节点用双向指针连接,提高区间访问性能。
2、思考问题
2.1、为什么建议Innodb表必须建主键,并且推荐使用整型的自增主键?
- 聚集索引、聚簇索引:索引文件和数据文件是聚集在一起的,(非聚集索引的数据文件和索引文件是分离的)。
- 主键索引:主键索引下存储的是所有数据值。
- 非主键索引:非主键索引下存储的是主键值。
- 建主键的原因:Innodb的设计初衷就是根据主键来建立索引来整理和组织整个数据表。
- 如果用户创建了一个没有主键的表,那么数据库会自动搜寻所有列的数据,去帮助你找到一列没有重复值,适合作为整张表的主键的数据列来根据这一列数据组织整张表的数据。
- 如果找不到一列适合做主键的数据列,那么mysql会自动在后台维护一个主键列,这个主键列就是一个整型的自增的变量。
- 使用整型自增主键的好处:查询遍历效率高,使用整型去比较大小要快。
- 自增的原因:因为B+树的构建过程是要保证数据有序,从大到小,所以最好使用从小到大的有序数据。
2.2、为什么非主键索引结构叶子节点存储的是主键值?
- 保证一致性,节省存储空间
二、hash索引原理
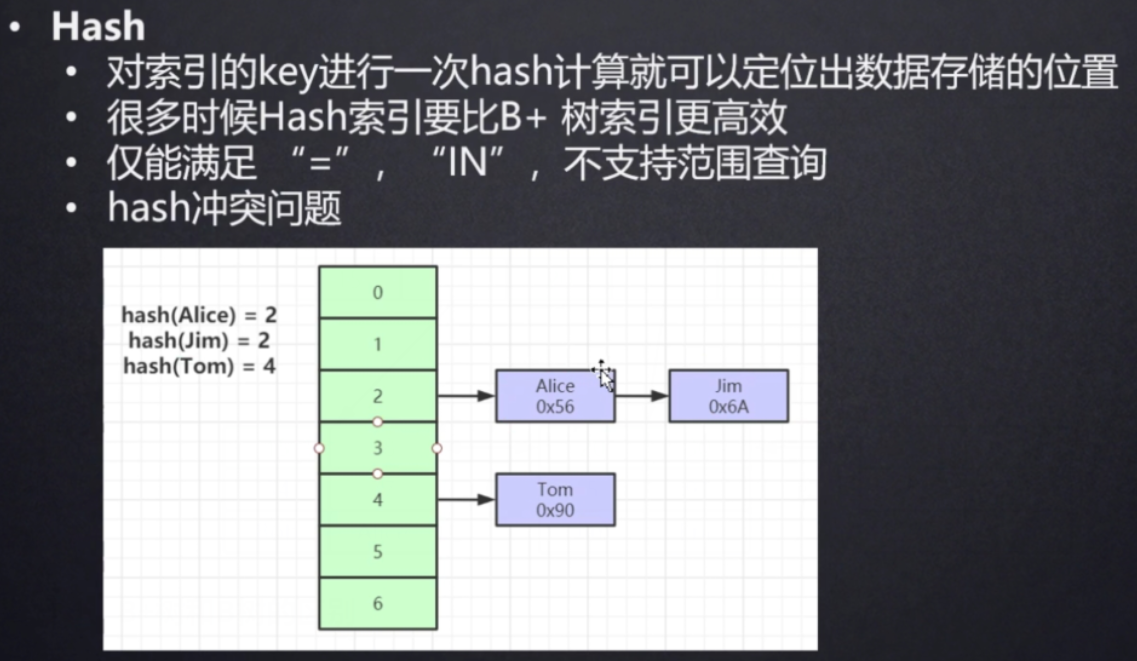
- 对索引的key进行一次hash计算就可以定位出数据存储的位置。
- 很多时候hash索引比B+树索引更加高效。
- 仅仅满足“=”、”IN“,不支持范围查询。
- 存在hash冲突(两个数据计算得出的hash值相同)问题。
三、B树和B+树
1、概念
首先,B树不要和二叉树混淆,在计算机科学中,B树是一种自平衡树数据结构,它维护有序数据并允许以对数时间进行搜索,顺序访问,插入和删除。B树是二叉搜索树的一般化,因为节点可以有两个以上的子节点。与其他自平衡二进制搜索树不同,B树非常适合读取和写入相对较大的数据块(如光盘)的存储系统。它通常用于数据库和文件系统。
2、B树定义
B树是一种平衡的多分树,通常我们说m阶的B树,它必须满足如下条件:
- 每个节点最多只有m个子节点。
- 每个非叶子节点(除了根)具有至少⌈ m/2⌉子节点。
- 如果根不是叶节点,则根至少有两个子节点。
- 具有k个子节点的非叶节点包含k -1个键。
- 所有叶子都出现在同一水平,没有任何信息(高度一致)。

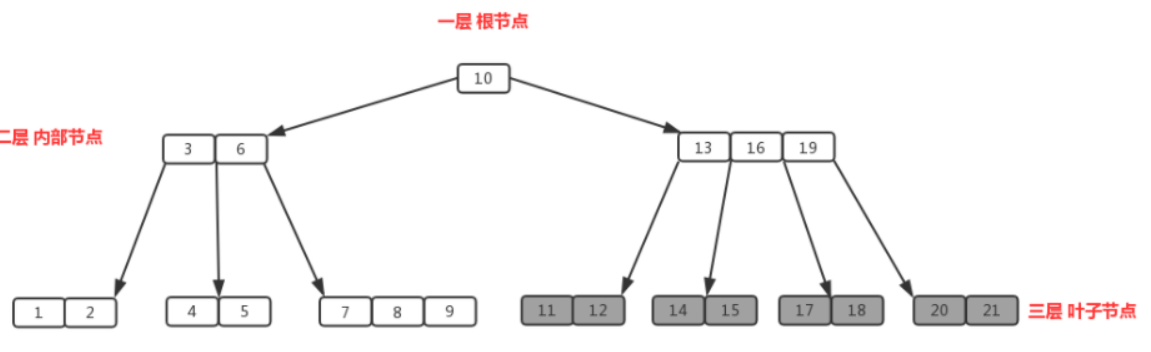
所有节点中,节点【13,16,19】拥有的子节点数目最多,四个子节点(灰色节点),所以可以定义上面的图片为4阶B树,现在懂什么是阶了吧
什么是根节点 ?
节点【10】即为根节点,特征:根节点拥有的子节点数量的上限和内部节点相同,如果根节点不是树中唯一节点的话,至少有两个个子节点(不然就变成单支了)。在m阶B树中(根节点非树中唯一节点),那么有关系式2<= M <=m,M为子节点数量;包含的元素数量 1<= K <=m-1,K为元素数量。
什么是内部节点 ?
节点【13,16,19】、节点【3,6】都为内部节点,特征:内部节点是除叶子节点和根节点之外的所有节点,拥有父节点和子节点。假定m阶B树的内部节点的子节点数量为M,则一定要符合(m/2)<= M <=m关系式,包含元素数量M-1;包含的元素数量 (m/2)-1<= K <=m-1,K为元素数量。m/2向上取整。
什么是叶子节点?
节点【1,2】、节点【11,12】等最后一层都为叶子节点,叶子节点对元素的数量有相同的限制,但是没有子节点,也没有指向子节点的指针。特征:在m阶B树中叶子节点的元素符合(m/2)-1<= K <=m-1。
插入
针对m阶高度h的B树,插入一个元素时,首先在B树中是否存在,如果不存在,即在叶子结点处结束,然后在叶子结点中插入该新的元素。
- 若该节点元素个数小于m-1,直接插入;
- 若该节点元素个数等于m-1,引起节点分裂;以该节点中间元素为分界,取中间元素(偶数个数,中间两个随机选取)插入到父节点中;
- 重复上面动作,直到所有节点符合B树的规则;最坏的情况一直分裂到根节点,生成新的根节点,高度增加1;
上面三段话为插入动作的核心,接下来以5阶B树为例,详细讲解插入的动作;
5阶B树关键点:
- 2<=根节点子节点个数<=5
- 3<=内节点子节点个数<=5
- 1<=根节点元素个数<=4
- 2<=非根节点元素个数<=4
 插入8
插入8 
图(1)插入元素【8】后变为图(2),此时根节点元素个数为5,不符合 1<=根节点元素个数<=4,进行分裂(真实情况是先分裂,然后插入元素,这里是为了直观而先插入元素,下面的操作都一样,不再赘述),取节点中间元素【7】,加入到父节点,左右分裂为2个节点,如图(3)

接着插入元素【5】,【11】,【17】时,不需要任何分裂操作,如图(4)

插入元素【13】

节点元素超出最大数量,进行分裂,提取中间元素【13】,插入到父节点当中,如图(6)

接着插入元素【6】,【12】,【20】,【23】时,不需要任何分裂操作,如图(7)

插入【26】时,最右的叶子结点空间满了,需要进行分裂操作,中间元素【20】上移到父节点中,注意通过上移中间元素,树最终还是保持平衡,分裂结果的结点存在2个关键字元素。

插入【4】时,导致最左边的叶子结点被分裂,【4】恰好也是中间元素,上移到父节点中,然后元素【16】,【18】,【24】,【25】陆续插入不需要任何分裂操作

最后,当插入【19】时,含有【14】,【16】,【17】,【18】的结点需要分裂,把中间元素【17】上移到父节点中,但是情况来了,父节点中空间已经满了,所以也要进行分裂,将父节点中的中间元素【13】上移到新形成的根结点中,这样具体插入操作的完成。

3、B+树定义
B+树的特征:
- 有m个子树的中间节点包含有m个元素(B树中是k-1个元素),每个元素不保存数据,只用来索引;
- 所有的叶子结点中包含了全部关键字的信息,及指向含有这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大的顺序链接。 (而B 树的叶子节点并没有包括全部需要查找的信息);
- 所有的非终端结点可以看成是索引部分,结点中仅含有其子树根结点中最大(或最小)关键字。 (而B 树的非终节点也包含需要查找的有效信息);


参考:https://blog.csdn.net/qq_35349114/article/details/96157931
好看请赞,养成习惯:) 本文来自博客园,作者:靠谱杨, 转载请注明原文链接:https://www.cnblogs.com/rainbow-1/p/15652392.html
欢迎来我的51CTO博客主页踩一踩 我的51CTO博客
文章中的公众号名称可能有误,请统一搜索:靠谱杨的秘密基地

 浙公网安备 33010602011771号
浙公网安备 33010602011771号