国民经济行业分类与代码(GB/T 4754-2002、GB/T 4754-2011、GB/T 4754-2017)并存入MySQL数据库【可获取下载】
戳链接下载:https://download.csdn.net/download/weixin_45556024/34913490
或关注公众号【靠谱杨的秘密基地】回复【行业】获取。
整理不易,资源fu费,谢谢理解!
2002标准表格式示例

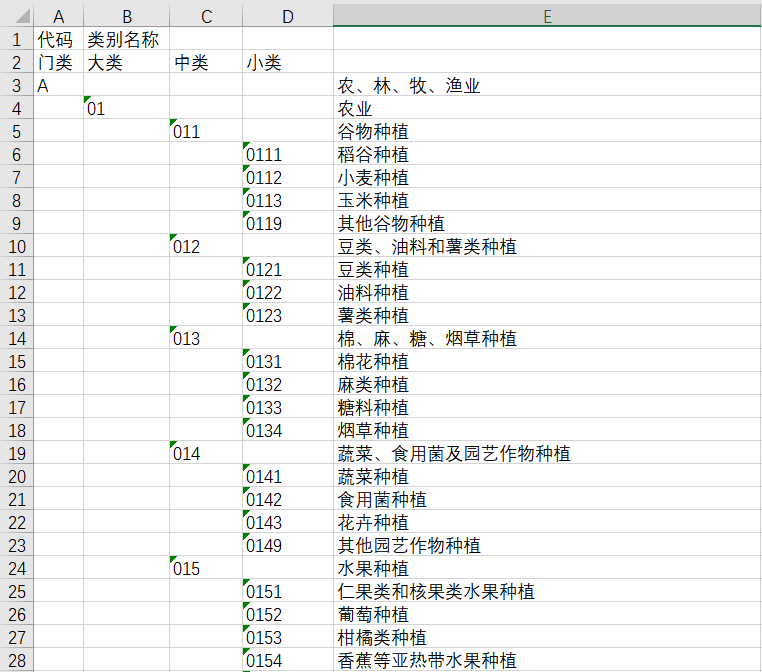
2002数据库
注意事项:字段的长度要保证足够长。
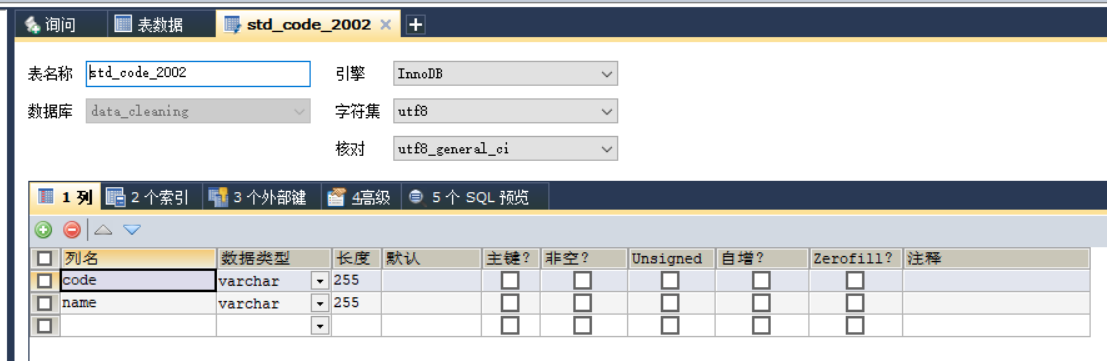
代码:

1 import pandas as pd 2 import pymysql 3 """ 4 ------------------------------------------------------------------------------------ 5 """ 6 def get_conn(): 7 """ 8 :return: 连接,游标 9 """ 10 # 创建连接 11 conn = pymysql.connect(host="127.0.0.1", 12 user="root", 13 password="000429", 14 db="data_cleaning", 15 charset="utf8") 16 # 创建游标 17 cursor = conn.cursor() # 执行完毕返回的结果集默认以元组显示 18 return conn, cursor 19 20 def close_conn(conn, cursor): 21 if cursor: 22 cursor.close() 23 if conn: 24 conn.close() 25 """ 26 ----------------------------------------------------------- 27 """ 28 """ 29 ------------------------------------------------------------------------------------ 30 """ 31 def query(sql,*args): 32 """ 33 通用封装查询 34 :param sql: 35 :param args: 36 :return:返回查询结果 ((),()) 37 """ 38 conn , cursor= get_conn() 39 print(sql) 40 cursor.execute(sql) 41 res = cursor.fetchall() 42 close_conn(conn , cursor) 43 return res 44 """ 45 ------------------------------------------------------------------------------------ 46 """ 47 count=0 #计算四位编码个数 48 def into_mysql(filename): 49 category_code = "" #门类编码 50 category_name = "" #门类名称 51 global count 52 conn,cursor=get_conn() #连接mysql 53 if(conn!=None): 54 print("数据库连接成功!") 55 tempres = [] #暂存列表 56 df=pd.read_excel(filename) #读取标准表 57 # print(len(df.index)) 58 for i in range(len(df.index.values)): #第一层遍历标准表 找到门类的编码和名称 找到小类的编码 59 # print(df.loc[i][1]) 60 code=str(df.loc[i][0]) #所有的编码 61 name=str(df.loc[i][1]) #所有的名称 62 if len(code)==1: 63 category_code=code #门类编码 64 category_name=name #门类名称 65 #分割编码 66 if len(code)==4: 67 count=count+1 68 small_class=name #小类名称 69 new_code_2=code[:2] #分割出两位编码 之后确定大类名称 70 new_code_3=code[:3] #分割出三位编码 之后确定中类名称 71 print(category_code) #最终的字符串需要门类的编码ABCD和门类的名称 72 print(new_code_2) 73 print(new_code_3) 74 for j in range(len(df.index.values)): #第二次遍历 寻找不同的位数的编码对应不同的名称 75 if new_code_2==df.loc[j][0]: 76 big_class=df.loc[j][1] #大类名称 77 if new_code_3==df.loc[j][0]: 78 mid_class=df.loc[j][1] #中类名称 79 tempres.append(category_code+code) #列表暂存A0511 编码 80 tempres.append(category_name+"·"+big_class+"·"+mid_class+"·"+small_class) #列表暂存完整的名称 81 print(tempres) 82 #==================================================================================== 83 SQL = "insert into std_code_2017 (code,name) values('"+tempres[0]+"','"+tempres[1]+"');" #sql插入语句 84 cursor.execute(SQL) #执行sql语句 85 conn.commit() #提交事务 86 print("--------------------------------------------------") 87 # ==================================================================================== 88 tempres=[] #清空列表 89 close_conn(conn,cursor) #关闭数据库连接 90 print("所有的四位编码数:\n",count) 91 return None 92 if __name__ == '__main__': 93 filename="GBT4754-2017.xlsx" 94 into_mysql(filename)
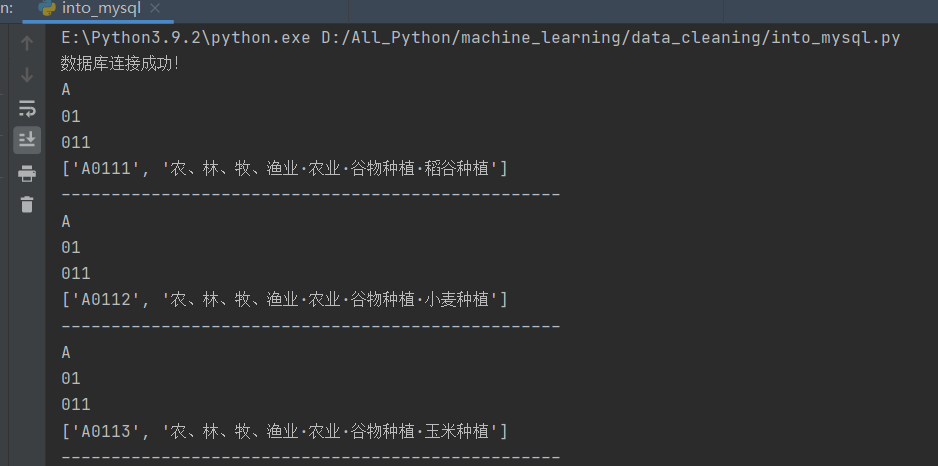
数据库表

好看请赞,养成习惯:) 本文来自博客园,作者:靠谱杨, 转载请注明原文链接:https://www.cnblogs.com/rainbow-1/p/15472774.html
欢迎来我的51CTO博客主页踩一踩 我的51CTO博客
文章中的公众号名称可能有误,请统一搜索:靠谱杨的秘密基地
分类:
干货







【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具
2020-10-27 【已解决】Java异常处理