第一次个人作业--词频统计总结
第一次个人作业--词频统计总结
作业要求:
1. 对源文件(*.txt,*.cpp,*.h,*.cs,*.html,*.js,*.java,*.py,*.php等,文件夹内的所有文件)统计字符数、单词数、行数、词频,统计结果以指定格式输出到默认文件中,以及其他扩展功能,并能够快速地处理多个文件。
2.使用性能测试工具进行分析,找到性能的瓶颈并改进
3.对代码进行质量分析,消除所有警告
4.设计10个测试样例用于测试,确保程序正常运行(例如:空文件,只包含一个词的文件,只有一行的文件,典型文件等等)
5.使用Github进行代码管理
6.撰写博客
功能要求:
1. 统计文件的字符数
2. 统计文件的单词总数
3. 统计文件的总行数
4. 统计文件中各单词的出现次数
5. 对给定文件夹及其递归子文件夹下的所有文件进行统计
6. 统计两个单词(词组)在一起的频率,输出频率最高的前10个
前期准备:
刚看到这个题目时,还是比较头疼的,这两年来我写的代码除了课上要求的,几乎就没有了,所以对这种多文件读取、大数据排序不是很熟悉。后来硬着头皮上了,才发现其实它的处理内容核心方面我还是比较了解的,就是对字符和字符串的处理,但是难点就在于:第一,要扫描的文件很多,处理数据很多,估计在数据类型设定方面要比较小心,而且还要考虑到分配的存储空间够不够用;第二,对于扫描目录文件的程序没有见过,后来我就在网上找了例程代码,但是把它弄懂并且融合进入自己的代码里还是花了一晚上的时间,而且它是一上来就拦路的老虎,我还给自我鼓励了一下才敢尝试;第三,要去装Linux系统,我最后还是没来得及装,要去提交代码,修改代码,刷新博客等等这些工作也是挺耗费时间的。
PSP表格:
|
Statu |
Stages |
预估耗时(min) |
实际耗时(min) |
|
Accept |
【计划】Planning |
60 |
60 |
|
Accept |
—— 估计时间 Estimate |
60 |
40 |
|
Accept |
【开发】Development |
600 |
800 |
|
Accept |
——[技术学习] 需求分析 Analysis |
60 |
100 |
|
Accept |
—— 设计文档 Design Spec |
60 |
60 |
|
Accept |
—— 设计复审 Design Review |
15 |
20 |
|
Accept |
—— 代码规范 Coding Standard |
20 |
25 |
|
Accept |
—— 具体设计 Design |
250 |
300 |
|
Accept |
—— 具体编码 Coding |
800 |
1000 |
|
Accept |
—— 代码复审 Code Review |
20 |
30 |
|
Accept |
—— 测试 Test |
60 |
30 |
|
Accept |
【记录用时】Record Time Spent |
10 |
10 |
|
Accept |
【测试报告】Test Report |
40 |
20 |
|
Accept |
【算工作量】 Size Measurement |
10 |
10 |
|
Accept |
【总结改进】 Postmortem |
60 |
45 |
|
Accept |
【合计】Summary |
2125 |
2550 |
设计思路:
由于我的编程基础不是很好,为了对软工作业有所准备,我在个人作业布置之前,浏览过一些互联网公司的招聘笔试的题目以及参考程序,我发现用的较多的C++语言,于是想着就学习一下C++,应用到软工作业上,可是看了一些资料,不是很明白,大部分就还是用了基本的C语言。但是我扩展学习了一下C语言的库函数,后期发挥了不小的作用。所以我的排序用的主要是库中的sort函数,找频率大的用的是遍历的思想,数据结构我还是用了传统的数组和结构体。读文件主要用了网上的一些例程代码,修改了一下。
设计实现:
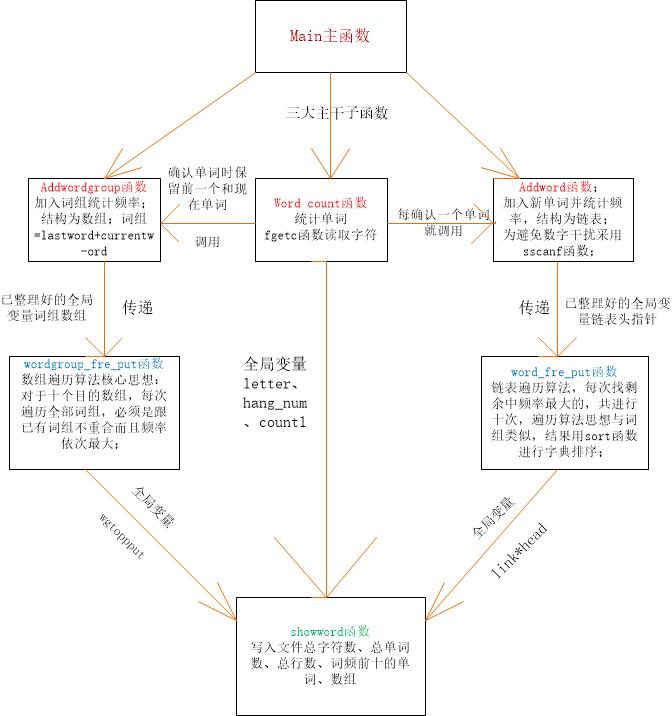
性能分析与优化:
占用资源:

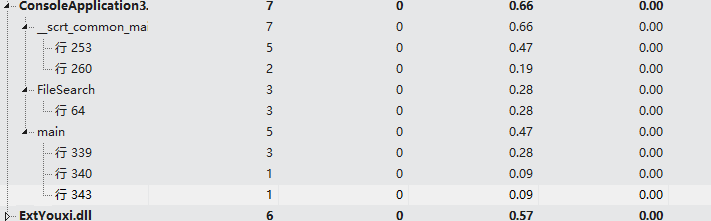
可以明显看到占用资源较多的是几个子函数,打开文件无法避免,子函数方面又以wordcount函数最热,我的优化办法就是删掉那个变换lastword与currentword的函数,直接在wordcount函数里变换,减少函数调用次数。另外在算法方面,我估计哈希算法会比较好,但是当时已经到ddl,我也没再改动。而对于词组的存储,如果像单词那样依然用指针,这样固然节省空间,但是时间复杂度增加,所以我采用了以空间换时间的办法,对于词组采用了数组形式。
输出Result(以Windows平台结果为例)
我的结果:
总的单词数:16768714 总共有2278340行 总共有173663456字符 前十词频单词 个数 THAT 259180 SAID 208885 CLASS 192004 HARRY 184742 WITH 158673 THIS 152414 THEY 145925 Span 116118 HAVE 108283 FROM 105394 前十词频词组 个数 Span CLASS 62851 THAT GOOD 61317 Span Span 41289 CLASS Reference 31269 Reference INTERNAL 26668 INTERNAL href 26667 SAID HARRY 24980 CLASS Span 23145 href LEAP 22568 SAID HERMIONE 19193 助教的结果: char_number :173654417 line_number :2278666 word_number :16629955 the top ten frequency of word : THAT 259186 SAID 208861 CLASS 192004 HARRY 184732 WITH 158745 THIS 152454 THEY 145945 Span 116118 HAVE 107383 FROM 105494 the top ten frequency of phrase : Span CLASS 62861 THAT GOOD 61427 Span Span 41286 CLASS Reference 31289 Reference INTERNAL 26668 INTERNAL href 26668 SAID HARRY 24981 CLASS Span 23146 href LEAP 22569
SAID HERMIONE 19193
可以看到TOP10单词与词组结果是完全一致的,但是各项统计数目还有点差别。这可能是由于算法有差异而导致的。
代码编写过程中的经验与收获
我在开始编的时候,是先按照单文件方式,想着等主要算法编好了,再遍历文件,其中的核心算法应该类似的,照着这个思路,我就出发了。
1.全局变量
考虑到本程序存储的东西比较多而且参数传递比较频繁,一开始就采用了设定全局变量的方式。
typedef struct word //连表 单词结构 { char w[Word_Max]; //单词 int count; //个数 struct word *next; }link; struct top { char w[Word_Max]; int fre; }topfre[10]; struct wordgroup { char lastword[100]; char currentword[100]; int count; char group[200]; }wgtop[2000000],wgtopput[10]; typedef struct Data { unsigned long size; char dir[500]; }Data; Data data[10000]; char currentword[100]; char lastword[100]; int FileSearch(char dir[]); int filenumber = -1; int count1=0; int flag=1; link *head=NULL; //单词连表头 FILE *fp=NULL; //文件指针 FILE *FP=NULL; int hang_num=0,letter=0;
可以看到设置的全局变量还是比较多的,一些重要结论数据都放在里面了,这样的好处就是函数比较好写,只需考虑函数的实现功能。
2.利用各种库函数
在这次作业前由于受到了网上一些代码的启发,觉得自己以前了解的库函数实在太少了,而使用这些功能强大、算法高效的库函数可以带来不少便捷。在这次作业里,我事先就翻看了C语言库函数大全,发现了一些比较有用的函数。
sort函数:
sort函数包含在头文件为#include<algorithm>的c++标准库中,有三个参数:
(1)第一个是要排序的数组的起始地址。
(2)第二个是结束的地址(最后一位要排序的地址)
(3)第三个参数是排序的方法,需要和bool类型的函数一起,可以是从大到小也可是从小到大,还可以不写第三个参数,此时默认的排序方法是从小到大排序。
Sort函数使用模板:
Sort(start,end,,排序方法)
代码表示:
sort(topfre,topfre+10,com); bool com(top a,top b) { if (strcmp(a.w,b.w)<0) return true; else return false; }
sscanf函数:
函数定义 int sscanf (const char *str,const char * format,........);
sscanf()会将参数str的字符串根据参数format字符串来转换并格式化数据。格式转换形式与scanf()相同。转换后的结果存于对应的参数内。
返回值:成功则返回参数数目,失败则返回-1,错误原因存于error中。 返回0表示失败 ,否则,表示正确格式化数据的个数。
例如:sscanf(str,"%d%d%s", &i,&i2, &s); 如果三个变成都读入成功会返回3。
文中的程序使用:
sscanf(lastword,"%[^0-9]",a);// 取到指定字符集为止的字符串 sscanf(currentword,"%[^0-9]",b);
字符串处理函数:
因为本次作业涉及的主要是对字符和字符串的处理,所以这方面用的比较多,不过大都是些常见的 ,像strcat、strlwr函数。
3.遍历读文件
主要使用了_findfirst函数、_findnext函数、_findclose函数
long _findfirst( char *filespec, struct _finddata_t *fileinfo );
返回值:如果查找成功的话,将返回一个long型的唯一的查找用的句柄(就是一个唯一编号)。这个句柄将在_findnext函数中被使用。若失败,则返回-1。
参数:filespec:标明文件的字符串,可支持通配符。比如:*.c,则表示当前文件夹下的所有后缀为C的文件。fileinfo :这里就是用来存放文件信息的结构体的指针。这个结构体必须在调用此函数前声明,不过不用初始化,只要分配了内存空间就可以了。函数成功后,函数会把找到的文件的信息放入这个结构体中。
int _findnext( long handle, struct _finddata_t *fileinfo );
返回值:若成功返回0,否则返回-1。
参数:handle:即由_findfirst函数返回回来的句柄。fileinfo:文件信息结构体的指针。找到文件后,函数将该文件信息放入此结构体中。
int _findclose( long handle );
返回值:成功返回0,失败返回-1。参数: handle :_findfirst函数返回回来的句柄。
代码中的函数:
int FileSearch(char dir[])//递归遍历当前目录下的所有文件 最后文件名信息存入data[Max]里
{
long handle;
_finddata_t findData;
char dirNew[300];
strcpy(dirNew, dir);
// strcat(dirNew, "\\*.*"); //如果是仅有一个文件,没有子目录,就需要把这句删去,在命令行写入完整路径即可。
if ((handle = _findfirst(dirNew, &findData)) == -1L)
{
printf("Failed to findfirst file");
return -1;
}
if(_findnext(handle, &findData) == 0)
{while (_findnext(handle, &findData) == 0)
{
if (findData.attrib & _A_SUBDIR)
{
if (strcmp(findData.name, ".") == 0 || strcmp(findData.name, "..") == 0)
continue;
strcpy(dirNew, dir);
strcat(dirNew, "\\");
strcat(dirNew, findData.name);
FileSearch(dirNew);
}
else
{
if (++filenumber <10000)//将路径入栈
{
strcpy(data[filenumber].dir, dir);
strcat(data[filenumber].dir, "\\");
strcat(data[filenumber].dir, findData.name);
data[filenumber].size = findData.size;
printf("%s\n",data[filenumber].dir) ;
}
}
}}
else{ if (++filenumber <10000)//将路径入栈
{
strcpy(data[filenumber].dir, dir);
data[filenumber].size = findData.size;
printf("%s\n",data[filenumber].dir) ;
}};
_findclose(handle);
}
这个函数开始时只能在多文件情况下运行,单文件就不行了,原因是单文件情况下原来的函数没做处理,因此我增加了一个单文件的情况下的处理步骤,但是单文件时,又不需要strcat(dirNew, "\\*.*");这一句,所以需要人工改动一下。
4.debug总结
在debug的时候,关于词组我改了一个下午,词组需要对上一个单词存储,进行lastword与currentword的转换,加入词组和计数倒也写得正确,但是在输出前十高频的词组时出了问题,遍历算法与排除算法(扫描到的词组不能跟已计入的词组相同)相结合,里面有不少牵涉到数组具体存储情况的问题,最后我分析了运行时的具体情况,才把错误排查出来。
还有一个就是fprintf函数,这个函数只有在用了fclose函数后,才能把缓冲区的数据写进文件里,本来没遇见过这种情况,不过在这个函数里,fprintf原来是在不同子函数下运行的,所以没用fclose,后来把那些fprintf函数写到了一个函数里,都用了统一的fclose,解决了这个问题。
具体函数:
main函数
int main() { char dir[100]="f1.txt"; FileSearch(dir); //printf("%d",filenumber); FP=fopen("result.txt","w+"); for(int i=0;i<=filenumber;i++) { if((fp=fopen(data[i].dir,"r+"))==NULL){ printf("Open the file failure...\n"); exit(0);} wordCount();} word_fre_put(); wordgroup_fre_put(); showWord(); fclose(fp); }
isnotWord函数
int isnotWord(char a) //判断是否为字母 { if(a>=' '&&a<='~') { letter++; } if(a <= 'z' && a >= 'a'||a <= 'Z' && a >= 'A'||a>='1'&&a<='9') { return 0; } else if(a=='\n') { hang_num++; return 1; } else { return 1; } }
wordCount函数
void wordCount() //统计单词 { int i=0,j=0; char word[Word_Max],wordad[Word_Max],c; while(!feof(fp)) { c = fgetc(fp); // printf("%c %d\n",c,j); if(isnotWord(c)) { word[j]='\0'; if(j>3) { addWord(word); if(flag==1) {strcpy(lastword,word); flag=0;goto d1;} if(flag==0) {strcpy(currentword,word);/*printf("%s\n",currentword);*/} addwordgroup(lastword,currentword); strcpy(lastword,currentword);//printf("%s\n",lastword); } d1: j=0; } else { word[j]=c; j++; if(j>=Word_Max) j=0; } //count9(word); i++; } }
addWord函数
void addWord(char *w1) //添加单词 { link *p1,*p2; char str[Word_Max],str1[Word_Max]; sscanf(w1,"%[^0-9]",str1); for(p1=head;p1!=NULL;p1=p1->next) //判断单词在连表中是否存在 { sscanf(p1->w,"%[^0-9]",str); if(!strcmp( strlwr(str1), strlwr(str))) { p1->count++; //存在就个数加1 count1++; if(strcmp(w1,p1->w)<0) strcpy(p1->w,w1); return; } } p1=(struct word *)malloc(sizeof(word));//若不存在,则添加新单词 strcpy(p1->w,w1); p1->count=1; p1->next=NULL; count1++; //总的单词数加加 if(head==NULL) { head=p1;//printf("%s\n",p1->w); } else { for(p2=head;p2->next!=NULL;p2=p2->next); p2->next=p1; } }
addwordgroup函数
void addwordgroup(char lastword[100],char currentword[100]) //边判断边加入 { int i; char a[100],b[100],a1[100],b1[100]; if(!wgtop[0].count) {strcpy(wgtop[0].lastword,lastword); strcpy(wgtop[0].currentword,currentword); strcpy(wgtop[0].group,lastword); strcat(wgtop[0].group," "); strcat(wgtop[0].group,currentword); wgtop[0].count++; } else { sscanf(lastword,"%[^0-9]",a); sscanf(currentword,"%[^0-9]",b); for( i=0;wgtop[i].count;i++) { sscanf(wgtop[i].lastword,"%[^0-9]",a1); sscanf(wgtop[i].currentword,"%[^0-9]",b1); if(!strcmp(a,a1)&&!strcmp(b,b1)) { wgtop[i].count++;return; } } for( i=0;wgtop[i].count&&i<2000000;i++); strcpy(wgtop[i].lastword,lastword); strcpy(wgtop[i].currentword,currentword); strcpy(wgtop[i].group,lastword); strcat(wgtop[i].group," "); strcat(wgtop[i].group,currentword);//printf("%s",wgtop[i].group); wgtop[i].count++; } }
word_fre_put函数
void word_fre_put() { link*p; int i,j; for(i=0;i<10;i++) { for(p=head;p!=NULL;p=p->next) { for(j=0;j<i;j++) if(strcmp(p->w,topfre[j].w)==0) {p=p->next;if(p==NULL) goto a1;j=-1;} //printf("%d",p->count); if(p->count>topfre[i].fre) {topfre[i].fre=p->count;/*printf("%d",topfre.fre[i]);*/strcpy(topfre[i].w,p->w);/*printf("%s",topfre.w[i]);*/} } } a1: sort(topfre,topfre+10,com); }
wordgroup_fre_put函数
void wordgroup_fre_put() { int i,j,m,max[10]={0},a[10]={0}; for(j=0;j<10;j++) { for(i=0;wgtop[i].count;i++) { for(m=0;m<j;m++) { if(!strcmp(wgtop[i].group,wgtopput[m].group)) {i++;m=-1;if(!wgtop[i].count) goto e1;} } if(wgtop[i].count>wgtopput[j].count) {wgtopput[j]=wgtop[i];} } e1: ; } c1: sort(wgtopput,wgtopput+10,com2); }
个人感想:
这是我软工课的第一次作业,我的编程实力不强,所以整个代码并没有用多新奇的数据结构,基本上用的是很常见的数组和链表,C++也只是临时抱佛脚学了点皮毛,花了不少时间才完成,也曾经放弃午睡,头晕得厉害时还跑到管科楼准备通宵,最后知道要在Linux运行,却因没时间再装,无奈上交代码,内心有一丝兴奋,几缕哀伤。但我还是感受到了软工这门课带给我的冲激,如果说学校的其他课程是以培养的方式进行,我觉得软工更适合用“锻炼”去形容,它带给了我一种别样的体会,很难说这两种方式哪个能给学生带来更大益处,抑或并存是更好的方式,但我还是觉得这门课有它自己的意义,虽然只是短短一周的时间,我却觉得自己的经历丰富了很多,个中滋味,唯有自己能够体会。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号