【House Prices】基本思路
猜想之前
在考虑使用什么模型之前,我们先看评分标准和数据特点
Kaggle给的评测标准是用"均方根误差",可以联想到,可能是一个线性回归问题。
看一下数据情况
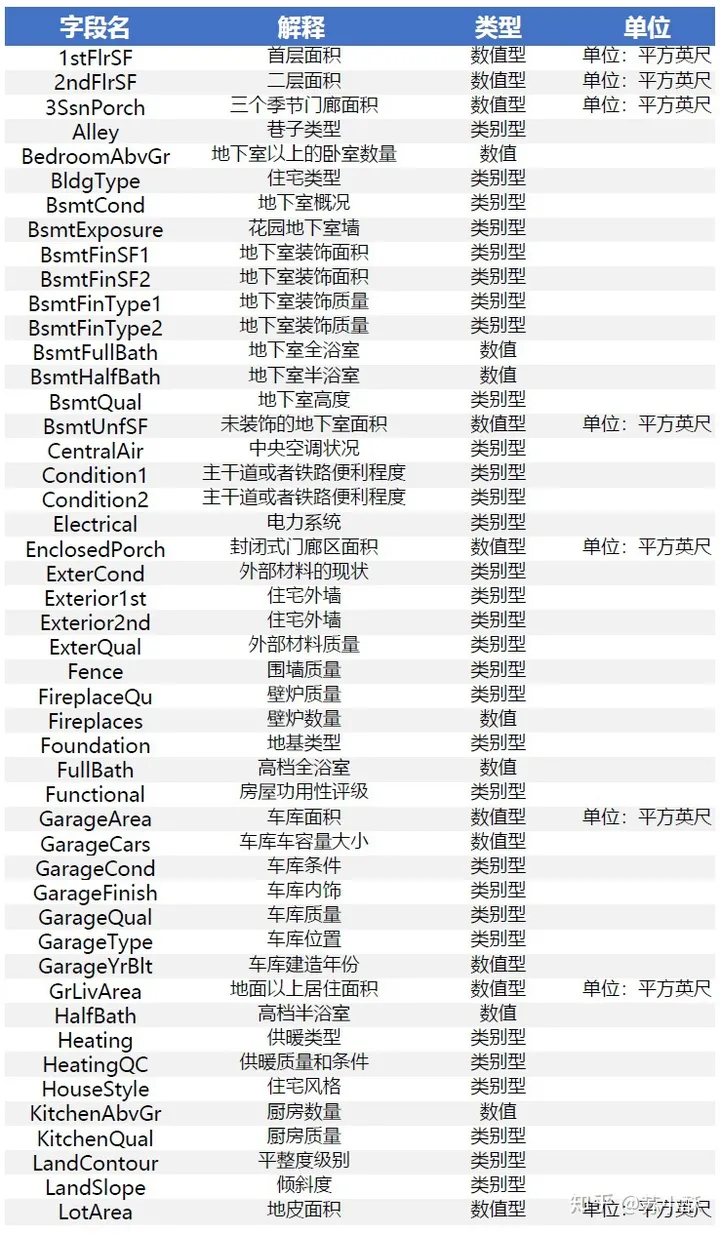
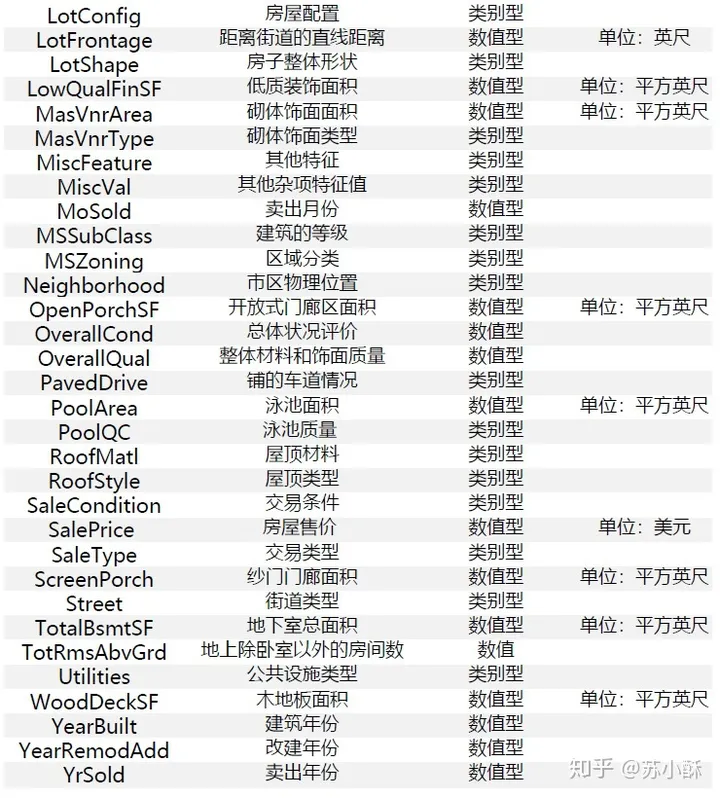
从常识上考虑,这些数据基本都是跟房屋价格线性相关的,其中决定性的可能是房屋面积和装修好坏
猜想
我觉得地皮面积可能跟房价有关系
为了显示地皮面积和房价之间的关系,首先查看一下房价的整体特征
train_df['SalePrice'].describe()

可以看出,所有房子价格都在80w以下
var = 'LotArea' #concat函数:将数据集中的某两列复制出来,并且进行连接 data = pd.concat([train_df['SalePrice'],train_df[var]], axis=1) #scatter函数:画一个二维图 data.plot.scatter(x=var, y='SalePrice', ylim=(0, 800000))
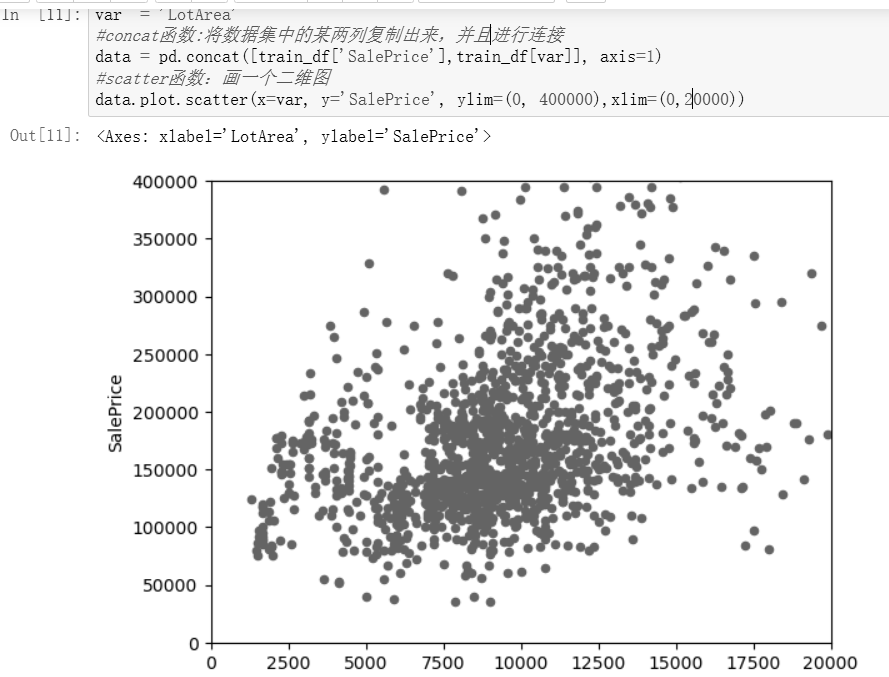
线性关系有点模糊,看不太出来,再看看有没有更好的参数
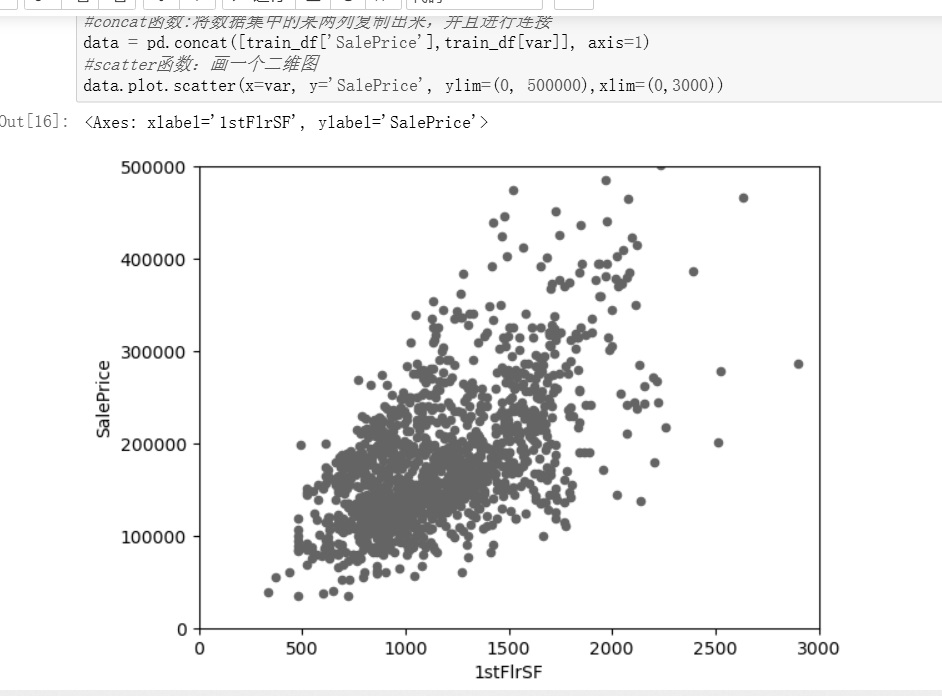
调查分析
这种方法过于麻烦,要都是这么做的话太浪费时间了
这段代码可以直接看出来不同变量之间的相关性,就用不着我们自己去观察了
corrmat = train_df.corr() f, ax = plt.subplots(figsize=(20, 9)) sns.heatmap(corrmat, vmax=0.8, square=True)
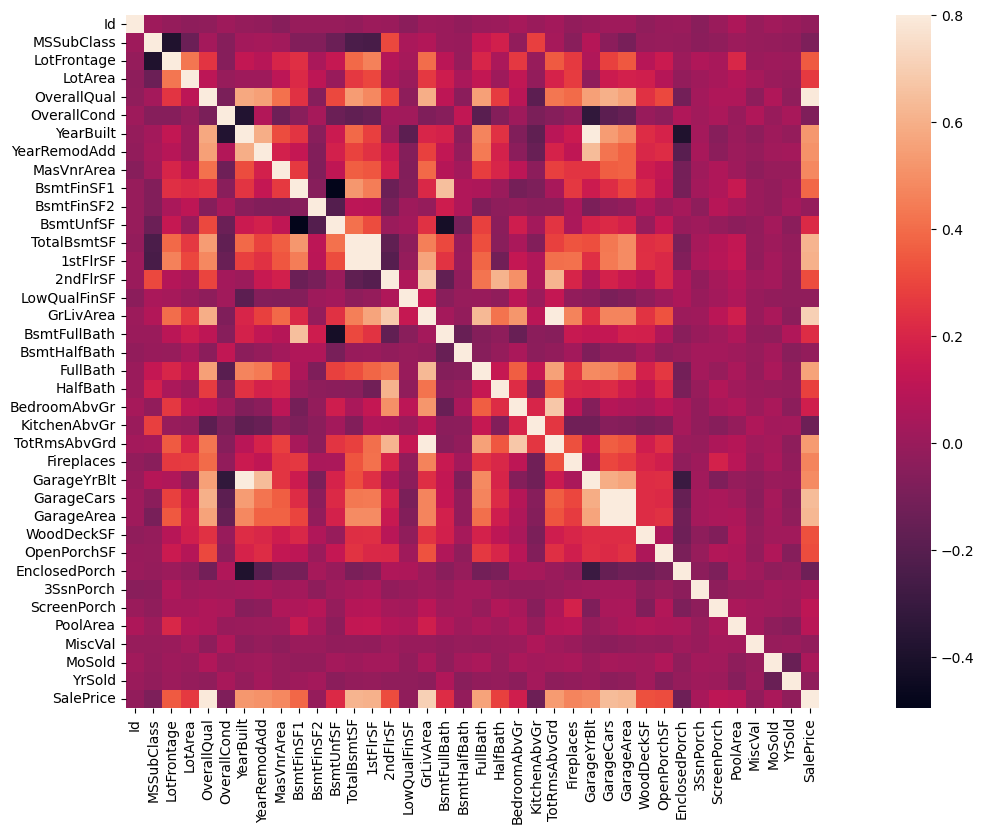
上面的图太大了,还是需要自己筛选,有点麻烦。因此,可以用下面的代码直接筛选出10个跟SalePrice关系最高的项,并绘制相关系数图
k = 10 # 关系矩阵中将显示10个特征 cols = corrmat.nlargest(k, 'SalePrice')['SalePrice'].index cm = np.corrcoef(train_df[cols].values.T) sns.set(font_scale=1.25) hm = sns.heatmap(cm, cbar=True, annot=True, \ square=True, fmt='.2f', annot_kws={'size': 10}, yticklabels=cols.values, xticklabels=cols.values) plt.show()

这里面,GarageArea和GarageCars是重复的变量,保留GarageCars我觉得就行。
到目前为止,基本思路是保留这十个相关性较高的变量,然后对这些变量相关的数据进行空值填充和重复变量删除,然后将拥有这些变量的数据集放入线性回归模型,进行训练

 浙公网安备 33010602011771号
浙公网安备 33010602011771号