Redis 数据结构 - 字典 dict
字典
以下源码基于redis 3.0
参考资料主要为《Redis 设计与实现 - 黄建宏》
书号:ISBN 978-7-111-46474-7
字典,又称为符号表(symbol talbe)、关联数组(associative array)、映射(map),是一种用于保存键值对(key-value pair)的抽象数据结构。
在字典中,一个键(key)可以和一个值(value)进行关联,或者说将键映射为值,这些关联的键和值就成为键值对。
字典中的每个键都是独一无二的,程序可以在字典中根据键查找与之相关联的值,或者通过键来更新值,或者通过键来删除整个键值对。
在 reids 中,字典的应用是相当广泛的,比如 redis 的数据库就是使用字典来作为底层实现的,对数据库的增删改查操作都是建立在对字典的操作之上的。
字典还是 hash 的底层实现之一,当一个哈希包含的键值对比较多,又或者键值对中的元素都是比较长的字符串时,redis 就会使用字典作为 哈希 的底层实现。
以下为 dict 的结构图:
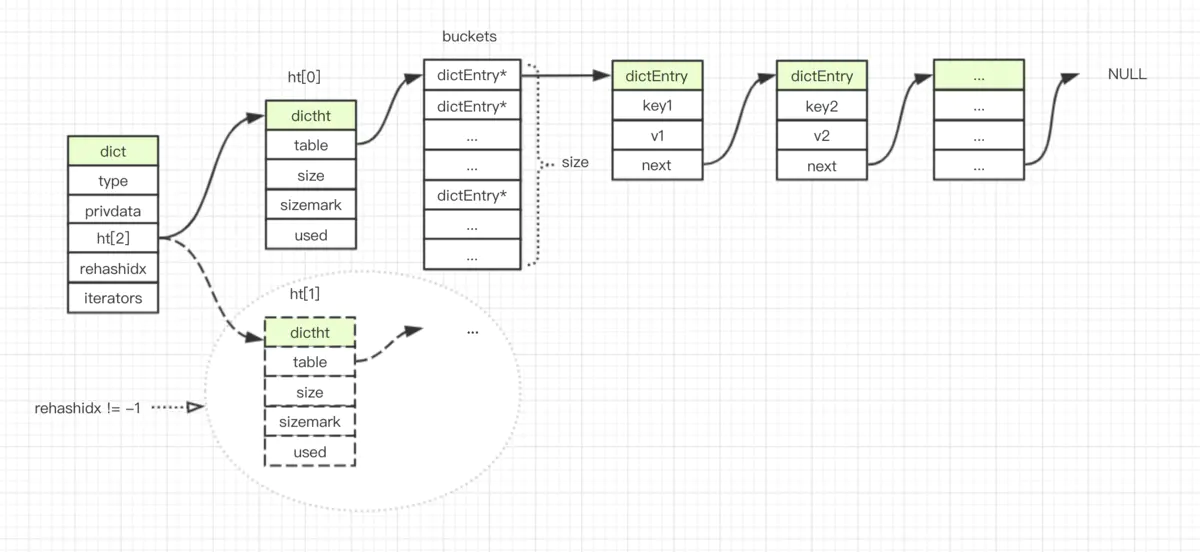
字典的实现
哈希表
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
/*
* 哈希表
*
* 每个字典都使用两个哈希表,从而实现渐进式 rehash 。
*/
typedef struct dictht {
// 哈希表数组
dictEntry **table;
// 哈希表大小
unsigned long size;
// 哈希表大小掩码,用于计算索引值,决定一个键应该被放到哪个索引上
// 总是等于 size - 1
unsigned long sizemask;
// 该哈希表已有节点的数量
unsigned long used;
} dictht;
Table 属性是一个数组,数组中的每个元素都指向一个dictEntry结构的指针,每个dictEntry结构保存着一个键值对。size 属性记录了哈希表的大小,也即是 table 数组的大小,而 used 属性则记录了哈希表目前已有节点(键值对)的数量。
哈希表的节点
/*
* 哈希表节点
*/
typedef struct dictEntry {
// 键
void *key;
// 值
union {
// 可以是一个指针,一个整数
void *val;
uint64_t u64;
int64_t s64;
} v;
// 指向下个哈希表节点,形成链表,以解决 hash 冲突
struct dictEntry *next;
} dictEntry;
出现 hash 冲突时的 hash 表:
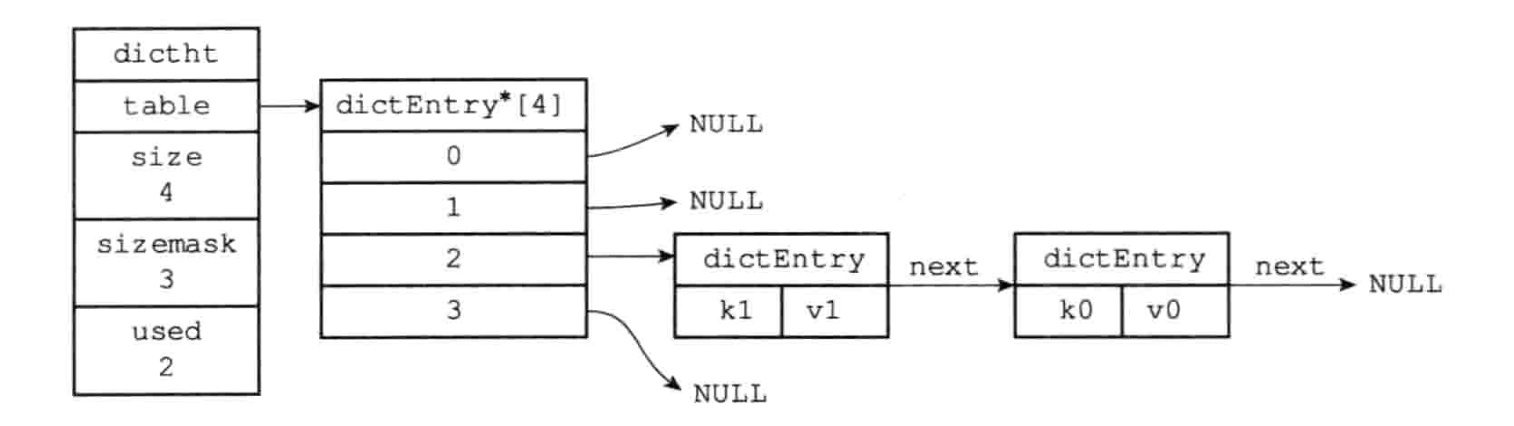
字典
/*
* 字典
*/
typedef struct dict {
// 类型特定函数
dictType *type;
// 私有数据
void *privdata;
// 哈希表,一个只包含两个项的数组,数组的每一项都是一个 hash 表,
// 一般情况下,字典只会使用 ht[0],ht[1] 哈希表只会在对 ht[0] 哈希表进行 rehash 时使用。
dictht ht[2];
// rehash 索引
// 当 rehash 不在进行时,值为 -1
int rehashidx; /* rehashing not in progress if rehashidx == -1 */
// 目前正在运行的安全迭代器的数量
int iterators; /* number of iterators currently running */
} dict;
其中,type 和 privdata 属性是针对不同类型的键值对,为创建多态字典而设置的。
-
type 是一个指针,指向 dictType 结构,每个 dictType 结构保存了一簇用于操作特定类型键值对的函数,redis 会为不同用途的字典设置不同的类型特定函数。
/* * 字典类型特定函数 */ typedef struct dictType { // 计算哈希值的函数 unsigned int (*hashFunction)(const void *key); // 复制键的函数 void *(*keyDup)(void *privdata, const void *key); // 复制值的函数 void *(*valDup)(void *privdata, const void *obj); // 对比键的函数 int (*keyCompare)(void *privdata, const void *key1, const void *key2); // 销毁键的函数 void (*keyDestructor)(void *privdata, void *key); // 销毁值的函数 void (*valDestructor)(void *privdata, void *obj); } dictType; -
而 privdata 属性则保存了需要传给那些类型特定函数的可选参数
哈希算法
当要将一个新的键值添加到字典里面时,程序需要先根据键值对的键计算出哈希值和索引值,然后再根据索引值,将包含新键值对的哈希表节点放到哈希表数组的指定索引上面。
// 计算给定键的哈希值
#define dictHashKey(d, key) (d)->type->hashFunction(key)
// 计算索引值
/* Get the index in the new hash table */
// 计算新哈希表的哈希值,以及节点插入的索引位置
h = dictHashKey(d, de->key) & d->ht[1].sizemask;
目前 redis 使用的是 MurmurHash 算法,该算法最早是由 Austin Appleby 于 2008 年发明的。该算法的优点在于,即使输入的键是有规律的,算法仍然能给出一个很好的随机分布性,并且计算的速度也很快。
解决键冲突
当有两个或以上数量的键被分配到了哈希表数组的同一个索引上,我们称这些键发生了冲突(collision)。
Redis 使用的链地址法来解决键冲突,每个哈希表节点都有一个 next 指针,多个哈希表节点通过 next 指针,来构成一个单向的链表,这样就解决了键冲突问题。
值得一提的是,java 在 hash 表中关于 hash 冲突的解决方法也是使用的 链地址法。
这里额外扩展下 hash 冲突的常用解决方法:
- 开放地址法
- 使用某种探测算法,在散列表中寻找下一个空的散列地址,只要散列表足够大,总能找到空的散列地址。
- 实现方式有
- 线性探查:发生 hash 冲突时,顺序查找下一个位置,直到找到一个空位置(固定探测步长 1 的探测)
- 二次探查:在发生 hash 冲突时,在表的左右位置进行按一定步长跳跃式探测(固定探测步长 n 的探测)
- 伪随机探查:在发生 hash 冲突时,根据公式生成一个随机数,作为此次探测空位置的步长(随机步长 n 的探测)
- 再 hash 法
- 这种方式会一次生成多个 hash 值,当第一个冲突了,就顺序取下一个,这种方式产生的不容易聚集,但是增加了计算时间。
- 链地址法(拉链法)
- 目前 java 中的 HashMap、ConcurrentHashMap 采用的解决 hash 冲突的办法,通过将冲突的键值保存一个额外的 next 指针,形成一个单项链表。为保证查询效率,在链表长度到达一定限制时,会重构为一颗红黑树。
- 这种方式,最差的结果就是所有的 hash 全部映射到一个槽上,这样 hash 就会退化成一个链表。
- 建立公共的溢出区域
- 将 hash 表分为基础表和溢出表两部分,为所有的发生了 hash 冲突的关键字,记录一个公共的溢出区域来存放。在查找的时候,先与哈希表的相应位置比较,如果查找成功,则返回。否则去公共区域按顺序查找。
- 在冲突较少时性能较好,冲突数据多时耗时。
在 redis 的字典中,当发生了 hash 冲突后,由于 dictEntry 节点上组成的链表没有链表表尾的指针,所以为了速度考虑,当发生 hash 冲突后,总是会把新节点添加到链表的表头位置,时间复杂度为 O(1),排在其他的节点之前。
插入算法:
/* Low level add. This function adds the entry but instead of setting
* a value returns the dictEntry structure to the user, that will make
* sure to fill the value field as he wishes.
*
* This function is also directly exposed to user API to be called
* mainly in order to store non-pointers inside the hash value, example:
*
* entry = dictAddRaw(dict,mykey);
* if (entry != NULL) dictSetSignedIntegerVal(entry,1000);
*
* Return values:
*
* If key already exists NULL is returned.
* If key was added, the hash entry is returned to be manipulated by the caller.
*/
/*
* 尝试将键插入到字典中
*
* 如果键已经在字典存在,那么返回 NULL
*
* 如果键不存在,那么程序创建新的哈希节点,
* 将节点和键关联,并插入到字典,然后返回节点本身。
*
* T = O(N)
*/
dictEntry *dictAddRaw(dict *d, void *key)
{
int index;
dictEntry *entry;
dictht *ht;
// 如果条件允许的话,进行单步 rehash
// T = O(1)
if (dictIsRehashing(d)) _dictRehashStep(d);
/* Get the index of the new element, or -1 if
* the element already exists. */
// 计算键在哈希表中的索引值
// 如果值为 -1 ,那么表示键已经存在
// T = O(N)
if ((index = _dictKeyIndex(d, key)) == -1)
return NULL;
// T = O(1)
/* Allocate the memory and store the new entry */
// 如果字典正在 rehash ,那么将新键添加到 1 号哈希表
// 否则,将新键添加到 0 号哈希表
ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0];
// 为新节点分配空间
entry = zmalloc(sizeof(*entry));
// 将新节点插入到链表表头
entry->next = ht->table[index];
ht->table[index] = entry;
// 更新哈希表已使用节点数量
ht->used++;
/* Set the hash entry fields. */
// 设置新节点的键
// T = O(1)
dictSetKey(d, entry, key);
return entry;
}
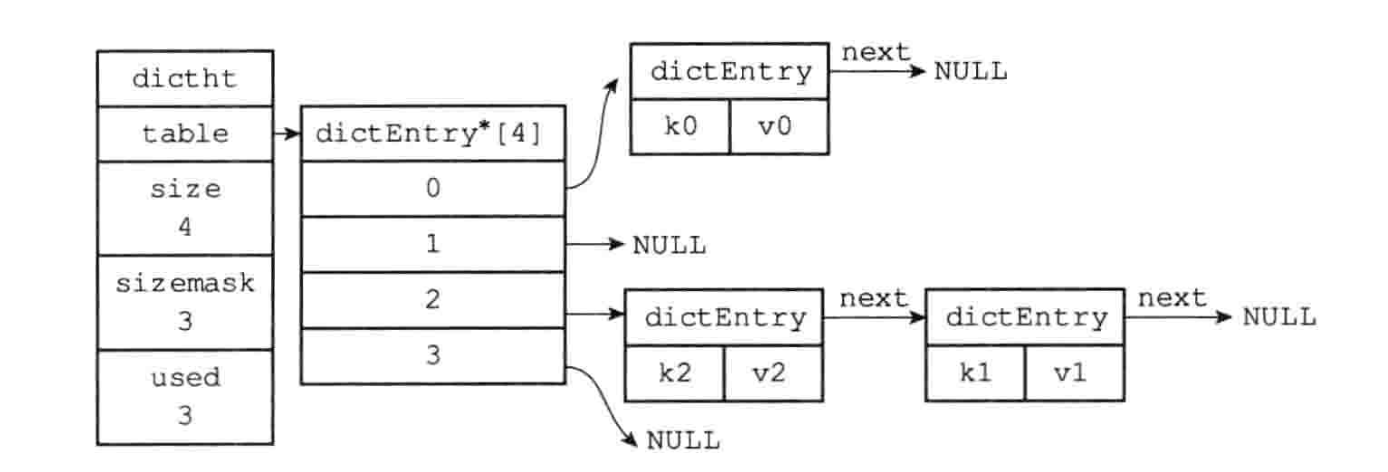
rehash
随着操作的不断进行,哈希表里的键值对会逐渐增多或者减少,为了让哈希表的负载因子(load factor)维持在一个合理的范围内,当哈希表保存的键值对数量太多或者太少时,程序会对哈希表的大小进行响应的扩展或者收缩。这个操作就是通过执行rehash(重新散列)来完成的。
rehash 的步骤如下:
-
为字典 ht[1] 哈希表分配空间,分配的大小取决于进行的操作,以及当前 ht[0] 当前包含的键值对数量,即 ht[0].userd 属性的值,具体操作大小为:
-
扩展操作
按当前使用的节点数量,扩大为第一个大于等于 ht[0].used 的 2 的 n 次方。
/* Expand the hash table if needed */ /* * 根据需要,初始化字典(的哈希表),或者对字典(的现有哈希表)进行扩展 * * T = O(N) */ static int _dictExpandIfNeeded(dict *d) { /* Incremental rehashing already in progress. Return. */ // 渐进式 rehash 已经在进行了,直接返回 if (dictIsRehashing(d)) return DICT_OK; /* If the hash table is empty expand it to the initial size. */ // 如果字典(的 0 号哈希表)为空,那么创建并返回初始化大小的 0 号哈希表 // T = O(1) if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE); /* If we reached the 1:1 ratio, and we are allowed to resize the hash * table (global setting) or we should avoid it but the ratio between * elements/buckets is over the "safe" threshold, we resize doubling * the number of buckets. */ // 一下两个条件之一为真时,对字典进行扩展 // 1)字典已使用节点数和字典大小之间的比率接近 1:1 // 并且 dict_can_resize 为真 // 2)已使用节点数和字典大小之间的比率超过 dict_force_resize_ratio if (d->ht[0].used >= d->ht[0].size && (dict_can_resize || d->ht[0].used/d->ht[0].size > dict_force_resize_ratio)) { // 新哈希表的大小至少是目前已使用节点数的两倍 // T = O(N) return dictExpand(d, d->ht[0].used*2); } return DICT_OK; } -
收缩操作
按当前使用的节点数量,缩小为第一个大于等于 ht[0].used 的 2 的 n 次方。
/* Resize the table to the minimal size that contains all the elements, * but with the invariant of a USED/BUCKETS ratio near to <= 1 */ /* * 缩小给定字典 * 让它的已用节点数和字典大小之间的比率接近 1:1 * * 返回 DICT_ERR 表示字典已经在 rehash ,或者 dict_can_resize 为假。 * * 成功创建体积更小的 ht[1] ,可以开始 resize 时,返回 DICT_OK。 * * T = O(N) */ int dictResize(dict *d) { int minimal; // 不能在关闭 rehash 或者正在 rehash 的时候调用 if (!dict_can_resize || dictIsRehashing(d)) return DICT_ERR; // 计算让比率接近 1:1 所需要的最少节点数量 minimal = d->ht[0].used; if (minimal < DICT_HT_INITIAL_SIZE) minimal = DICT_HT_INITIAL_SIZE; // 调整字典的大小 // T = O(N) return dictExpand(d, minimal); }
注:公共方法源码
/* Expand or create the hash table */ /* * 创建一个新的哈希表,并根据字典的情况,选择以下其中一个动作来进行: * * 1) 如果字典的 0 号哈希表为空,那么将新哈希表设置为 0 号哈希表 * 2) 如果字典的 0 号哈希表非空,那么将新哈希表设置为 1 号哈希表, * 并打开字典的 rehash 标识,使得程序可以开始对字典进行 rehash * * size 参数不够大,或者 rehash 已经在进行时,返回 DICT_ERR 。 * * 成功创建 0 号哈希表,或者 1 号哈希表时,返回 DICT_OK 。 * * T = O(N) */ int dictExpand(dict *d, unsigned long size) { // 新哈希表 dictht n; /* the new hash table */ // 根据 size 参数,计算哈希表的大小 // T = O(1) unsigned long realsize = _dictNextPower(size); /* the size is invalid if it is smaller than the number of * elements already inside the hash table */ // 不能在字典正在 rehash 时进行 // size 的值也不能小于 0 号哈希表的当前已使用节点 if (dictIsRehashing(d) || d->ht[0].used > size) return DICT_ERR; /* Allocate the new hash table and initialize all pointers to NULL */ // 为哈希表分配空间,并将所有指针指向 NULL n.size = realsize; n.sizemask = realsize-1; // T = O(N) n.table = zcalloc(realsize*sizeof(dictEntry*)); n.used = 0; /* Is this the first initialization? If so it's not really a rehashing * we just set the first hash table so that it can accept keys. */ // 如果 0 号哈希表为空,那么这是一次初始化: // 程序将新哈希表赋给 0 号哈希表的指针,然后字典就可以开始处理键值对了。 if (d->ht[0].table == NULL) { d->ht[0] = n; return DICT_OK; } /* Prepare a second hash table for incremental rehashing */ // 如果 0 号哈希表非空,那么这是一次 rehash : // 程序将新哈希表设置为 1 号哈希表, // 并将字典的 rehash 标识打开,让程序可以开始对字典进行 rehash d->ht[1] = n; d->rehashidx = 0; return DICT_OK; /* 顺带一提,上面的代码可以重构成以下形式: if (d->ht[0].table == NULL) { // 初始化 d->ht[0] = n; } else { // rehash d->ht[1] = n; d->rehashidx = 0; } return DICT_OK; */ } /* Our hash table capability is a power of two */ /* * 计算第一个大于等于 size 的 2 的 N 次方,用作哈希表的值 * * T = O(1) */ static unsigned long _dictNextPower(unsigned long size) { unsigned long i = DICT_HT_INITIAL_SIZE; if (size >= LONG_MAX) return LONG_MAX; while(1) { if (i >= size) return i; i *= 2; } } -
-
将保存在 ht[0] 中的所有的键值对 rehash 到 ht[1] 上面,重新计算键的哈希值和索引值。
-
当 ht[0] 包含的所有键值对都迁移到了 ht[1] 之后,ht[0] 变成空表,释放 ht[0],将 ht[1] 设置为 ht[0],并在 ht[1] 新创建一个空白哈希表,为下一次 rehash 做准备。
哈希表的扩展与收缩
当满足以下任意一个条件时,程序会自动开始对哈希表执行扩展操作:
- 服务器目前没有在执行
BGSAVE [SCHEDULE]命令或者BGREWRITEAOF命令,并且哈希表的负载因子大于等于1 - 服务器目前正在执行
BGSAVE [SCHEDULE]命令或者BGREWRITEAOF命令,并且哈希表的负载因子大于等于5
哈希表的负载因子计算公式:
// 负载因子 = 哈希表已保存节点数量 / 哈希表大小
load_factor = ht[0].used / ht[0].size
例如:
- 对于一个大小为 4,包含 4 个键值对的哈希表来说,负载因子为:
load_factor = 4 / 4 = 1 - 对于一个大小为 512,包含 256 个键值对的哈希表来说,负载因子为:
load_factor = 256 / 512 = 0.5
由于在执行BGSAVE [SCHEDULE]命令或者BGREWRITEAOF命令的过程中,redis 需要创建当前服务器的子进程,而大多数操作系统都会采用写时复制(copy on write)技术来优化子进程使用效率,所以在子进程存在期间,服务器会通过提高 扩展操作所需要的 load_factor,从而尽可能的避免在子进程存在期间对哈希表进行扩展操作,这可以避免不必要的内存写入操作,最大限度的节约内存。
关于收缩方面,当哈希表的负载因子小于0.1时,会自动开始对哈希表进行收缩操作。
渐进式 rehash
前面提到了 rehash 的相关操作:通过将 ht[0] 的所有键值对 rehash 到 ht[1] 里面,来完成哈希表的扩展或收缩。
但是这个过程很明显不是一次性、集中式的完成的,而是一个分多次、渐进式的过程。
试想如果需要对一个拥有庞大数量键值对的哈希表进行 rehash 操作,而这个过程是一次性完成的,庞大的计算量将会引起服务器在一段时间内停止服务。因此,为了避免这样的操作对服务器的性能影响,rehash 是一个渐进的、分多次的过程。
详细步骤:
- 为 ht[1] 分配空间,让字典同时持有 ht[0] 和 ht[1] 两个哈希表
- 在字典中维持了一个索引计数器:变量 rehashidx,并将它的值设置为 0,代表 rehash 正式开始
- 在 rehash 期间,每次对字典的添加、删除、查找或者更新操作时,程序除了执行指定的操作外,还会顺带将 ht[0] 哈希表在 rehashidx 索引上的所有键值对 rehash 到 ht[1],当 rehash 工作完成后,程序会将 rehashidx 属性的值增加一
- 随着字典操作的不断进行,最终在一个时间点上,ht[0] 的所有键值对都会被 rehash 到 ht[1],这时程序将 rehashidx 属性的值设为 -1,表示 rehash 完成。
这样将 rehash 的所有需要计算工作,均摊到对字典的每个添加删除和查找更新操作上。
在渐进式 rehash 执行过程中,字典会同时使用 ht[0] 和 ht[1] 两个哈希表,所以在渐进式 rehash 进行期间,字典的删除(delete)、查找(find)、更新(update)等操作会同时在两个哈希表上进行。
例如:要查找一个键的话,程序会先在 ht[0] 里面进行查找,如果没找到的话,就会继续到 ht[1] 里面进行查找。
但是,在渐进式 rehash 进行过程中,新添加的字典的键值会一律保存到 ht[1] 里面,而 ht[0] 则不再进行任何添加操作,这个措施保证了 ht[0] 包含的键值对数量只会减不会增,并且随着 rehash 进行,最终变成空表。
字典的 API
字典的大部分操作都是 O(1) 的时间复杂度。在此给出查询源码:
查询指定 key 值
/*
* 返回字典中包含键 key 的节点
*
* 找到返回节点,找不到返回 NULL
*
* T = O(1)
*/
dictEntry *dictFind(dict *d, const void *key)
{
dictEntry *he;
unsigned int h, idx, table;
// 字典(的哈希表)为空
if (d->ht[0].size == 0) return NULL; /* We don't have a table at all */
// 如果条件允许的话,进行单步 rehash
if (dictIsRehashing(d)) _dictRehashStep(d);
// 计算键的哈希值
h = dictHashKey(d, key);
// 在字典的哈希表中查找这个键
// T = O(1)
for (table = 0; table <= 1; table++) {
// 计算索引值
idx = h & d->ht[table].sizemask;
// 遍历给定索引上的链表的所有节点,查找 key
he = d->ht[table].table[idx];
// T = O(1)
while(he) {
if (dictCompareKeys(d, key, he->key))
return he;
he = he->next;
}
// 如果程序遍历完 0 号哈希表,仍然没找到指定的键的节点
// 那么程序会检查字典是否在进行 rehash ,
// 然后才决定是直接返回 NULL ,还是继续查找 1 号哈希表
if (!dictIsRehashing(d)) return NULL;
}
// 进行到这里时,说明两个哈希表都没找到
return NULL;
}
// 比对两个键
#define dictCompareKeys(d, key1, key2) \
(((d)->type->keyCompare) ? \
(d)->type->keyCompare((d)->privdata, key1, key2) : \
(key1) == (key2))
// 查看字典是否正在 rehash
#define dictIsRehashing(ht) ((ht)->rehashidx != -1)
总结
- 字典被广泛应用于实现 Redis 的各种功能,其中包括数据库和哈希键。
- Redis 中的字典使用哈希表作为底层实现,每个字典都带有两个哈希表,一个平时使用,一个在 rehash 中使用。
- 字典被作为数据库的底层实现,或者哈希键的底层实现时,Redis 使用** MurmurHash2 算法来计算键的哈希值**。
- 哈希表使用链地址法来解决键冲突,被分配到同一个索引上的多个键值对会连接成一个单向的链表。
- 在对哈希表进行扩展或者收缩操作时,程序需要将现有的哈希表包括的所有键值对 rehash 到新哈希表里面,并且这个 rehash 过程并不是一次性完成的,而是渐进式完成的。
最后,再看一眼 dict 的结构图:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号