

Java Trie实现高效正向最大化中文分词
在中文分词中,如何高效地对一段中文文本进行切分是一个非常关键的问题。传统的中文分词方法大多是基于词典的正向最大匹配(Maximal Forward Matching, MFM)和反向最大匹配(Maximum Backward Matching, MBM)。在这篇博客中,我们将重点介绍如何通过Java中的Trie(字典树)来实现高效的正向最大化中文分词,并与传统的正向最大匹配方法进行对比。
1. 什么是正向最大化中文分词?
中文分词是将一段没有空格的连续中文字符序列切分成词汇的过程。正向最大化分词方法是通过从文本的开头开始,尽量选择词典中最长的匹配词语进行分割,直到文本的末尾。
例如,给定文本“我爱北京天安门”,假设我们的词典包含“我”,“爱”,“北京”,“天安门”等词,那么正向最大化分词的过程会是:
输入: 我爱北京天安门
输出: 我 / 爱 / 北京 / 天安门
2. 传统的正向最大匹配方法(MM)
传统的正向最大匹配方法是通过遍历文本中的每个字符,然后从当前位置开始,尽量匹配长的词条,直到匹配失败。假设有一个词典如下:
我
爱
北京
天安门
过程:
- 从文本的第一个字符“我”开始,匹配“我”。
- 接下来是“爱”,匹配“爱”。
- 然后是“北京”,匹配“北京”。
- 最后是“天安门”,匹配“天安门”。
这种方法的缺点在于:
- 如果词典非常大,匹配效率较低。
- 如果存在歧义词,正向匹配也可能无法找到最合适的分词方案。
3. 如何利用Trie优化正向最大匹配分词?
Trie(字典树)是一种基于树形结构的数据结构,适合高效地处理前缀查询。通过Trie,我们可以高效地查询词典中是否存在某个词,并且能够快速找到最长匹配词。具体来说,使用Trie实现正向最大化分词的步骤如下:
- 构建Trie树:将所有的词条从词典中插入到Trie树中。
- 分词过程:从输入文本的第一个字符开始,尽量选择Trie树中最长的匹配词进行切分。
优势:
- 构建Trie树的时间复杂度为O(N),其中N是词典中所有词的总字符数。
- 查询匹配的时间复杂度为O(M),其中M是待分词文本的长度。
相比传统的逐个匹配的方法,Trie树能够减少重复计算和不必要的查询,大大提高效率。
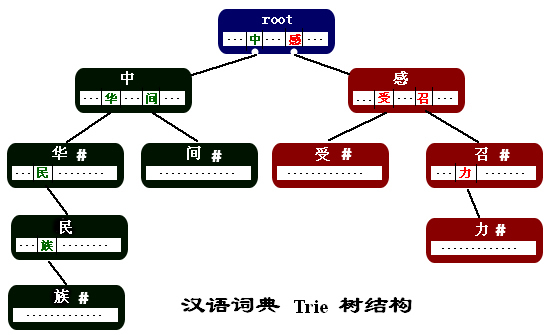
(来源于https://blog.csdn.net/wzb56_earl/article/details/7902669)
4. Java实现Trie树
下面是一个简单的Java实现示例,展示了如何用Trie树来进行正向最大化中文分词。
4.1 Trie树的实现
import java.util.*;
class TrieNode {
Map<Character, TrieNode> children;
boolean isEndOfWord;
public TrieNode() {
children = new HashMap<>();
isEndOfWord = false;
}
}
class Trie {
private TrieNode root;
public Trie() {
root = new TrieNode();
}
// 插入一个词
public void insert(String word) {
TrieNode node = root;
for (char c : word.toCharArray()) {
node.children.putIfAbsent(c, new TrieNode());
node = node.children.get(c);
}
node.isEndOfWord = true;
}
// 查找最长匹配的词
public String findLongestPrefix(String text) {
TrieNode node = root;
StringBuilder sb = new StringBuilder();
for (char c : text.toCharArray()) {
if (!node.children.containsKey(c)) {
break;
}
sb.append(c);
node = node.children.get(c);
if (node.isEndOfWord) {
// 如果是一个完整的词,继续
}
}
return sb.toString();
}
}
4.2 使用Trie树进行中文分词
import java.util.*;
public class TrieSegmenter {
private Trie trie;
public TrieSegmenter(List<String> dictionary) {
trie = new Trie();
for (String word : dictionary) {
trie.insert(word);
}
}
public List<String> segment(String text) {
List<String> result = new ArrayList<>();
int start = 0;
while (start < text.length()) {
String longestPrefix = trie.findLongestPrefix(text.substring(start));
if (longestPrefix.isEmpty()) {
// 如果没有匹配的词,可以选择跳过一个字符(错误处理)
start++;
} else {
result.add(longestPrefix);
start += longestPrefix.length();
}
}
return result;
}
public static void main(String[] args) {
List<String> dictionary = Arrays.asList("我", "爱", "北京", "天安门");
TrieSegmenter segmenter = new TrieSegmenter(dictionary);
String text = "我爱北京天安门";
List<String> words = segmenter.segment(text);
System.out.println(words); // 输出:[我, 爱, 北京, 天安门]
}
}
5. 与传统方法的对比
| 特性 | 传统正向最大匹配(MM) | Trie优化正向最大匹配 |
|---|---|---|
| 时间复杂度 | O(M * N)(每个字符都可能需要多次查询) | O(M)(通过Trie树高效查找匹配词) |
| 空间复杂度 | O(N)(词典的存储) | O(N)(Trie树的存储,通常更高效) |
| 匹配速度 | 较慢,尤其词典较大时 | 更快,能够通过树形结构减少查询时间 |
| 歧义处理 | 无法解决歧义问题 | 依赖Trie树的最长匹配,能有效减少歧义 |
分类:
python / algorithm
, java


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 上周热点回顾(3.3-3.9)