
Request+Python微博爬虫实战
1 Request爬虫基础
Request爬虫基本步骤:1、构造URL;2、请求数据;3、解析数据;4、保存数据
例:爬取豆瓣某图片
import requests
# 第1步:构造URL
url = 'https://img3.doubanio.com/view/photo/s_ratio_poster/public/p2624516210.jpg'
# 第2步:请求数据
r = requests.get(url)
# 第3步:解析数据
print("根据数据类型解析数据,该请求的数据类型为【%s】" % r.headers['Content-Type'])
# 第4步:保存数据
with open("tmp/图片.jpg", "wb") as f:
f.write(r.content)
print('图片保存成果!')
Step 1 构造URL
从开发者工具里找到自己想爬取的数据的链接

Step 2 请求数据
get指令:request.get(url)
1.响应状态码
200: ('ok', 'okay', 'all_ok', 'all_okay', 'all_good', '\o/', '✓')
400: ('bad_request', 'bad')
401: ('unauthorized',)
403: ('forbidden',)
404: ('not_found', '-o-')
500: ('internal_server_error', 'server_error', '/o\', '✗')
2.中文数据乱码
r.encoding = r.apparent_encoding
3.解决无响应问题
r = requests.get("https://www.google.com", timeout=1)
4.复杂请求方法
# 方法一:采用构造参数请求访问
response = requests.get("https://baidu.com", params={'wd': 'python'})
# 方法二:采用构造URL方式访问
response = requests.get('http://baidu.com?wd=python')
# 方法三:构建 POST 作为表单数据传输给服务器
payload = {'key1': 'value1', 'key2': 'value2'}
r = requests.post("http://httpbin.org/post", data=payload)
# 方法四:构建 POST 作为 json 格式的字符串格式传输给服务器
import json
payload = {'key1': 'value1'}
r = requests.post('http://httpbin.org/post', json=payload)
Step 3 网页解析
bs4解析网页
from bs4 import BeautifulSoup
print(html)
soup = BeautifulSoup(html, "html.parser")
1. 格式化输出
soup.prettify()
2. 打印title标签
soup.title
3. 打印title标签的内容
soup.title.string
4. 逐层遍历
soup.body.main.a
5. 获取属性
soup.body.main.a.attrs['href']
6. 下行遍历
.contents 子节点的列表,将所有儿子节点存入列表
.children 子节点的迭代类型,与.contents类似,用于循环遍历儿子节点
.descendants 子孙节点的迭代类型,包含所有子孙节点,用于循环遍历
7. 上行遍历
.parent 节点的父亲标签
.parents 节点先辈标签的迭代类型,用于循环遍历先辈节点
8. 平行遍历
.next_sibling 返回按照HTML文本顺序的下一个平行节点标签
.previous_sibling 返回按照HTML文本顺序的上一个平行节点标签
.next_siblings 迭代类型,返回按照HTML文本顺序的后续所有平行节点标签
.previous_siblings 迭代类型,返回按照HTML文本顺序的前续所有平行节点标签
Step 4 保存数据
1.生成多列表,使用Dataframe整体输出
data = pd.DataFrame(data={"index": range(1, Num + 1),
"user_id": list_uid,
"name": list_name,
"time": list_time,
"content": list_content,
}).to_csv(csv_name, index=False)
2.writeline逐行输出
fp = open('csv_name','w',encoding='utf-8')
fp.writelines('index,user_id,name,time,content\n')
fp.writelines(f'{uid},{name},{time},{content}\n')
2 Request爬虫实战小技巧
(1)常用报头设置(设置请求主体User-Agent防止过快被封;设置用户Cookie模拟登录;设置Connection与网页保持连接)
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:88.0) Gecko/20100101 Firefox/88.0',
'Cookie': 'Your_cookie',
'Connection': 'keep-alive0'}
res = requests.get(url = url,headers = headers)
(2)设置Session
request的生命周期是request请求域,一个请求结束,则request结束。session的生命周期是session会话域,在整个会话期间都有效。设置Session对象保持程序与服务器的连接,避免每次请求重新连接导致效率低下。
session = requests.Session()
res = session.get(url = url, headers = headers)
(3)找到自己的cookie
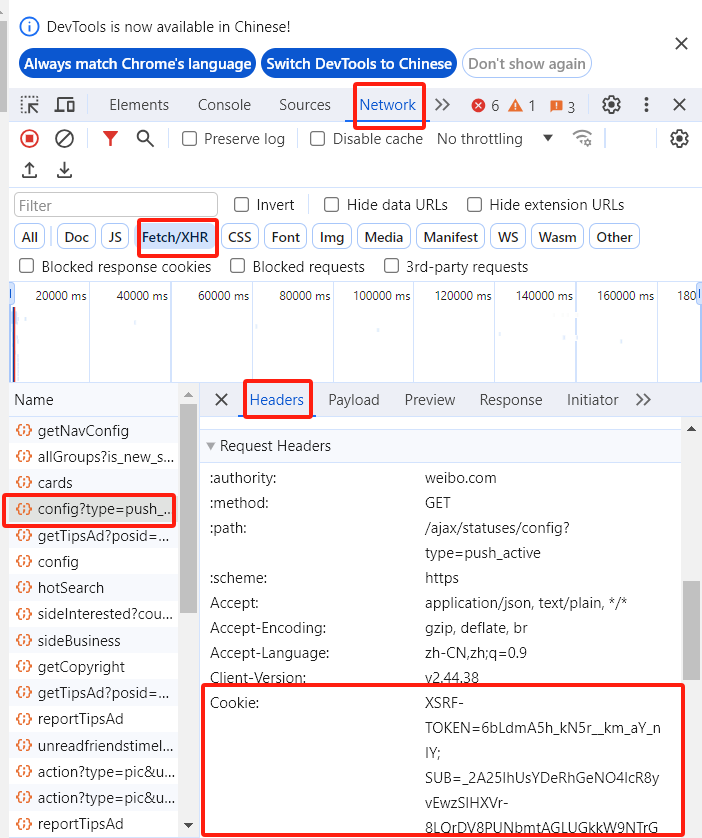
3 基于Request的微博用户博文爬虫
用户博文的域名包括用户UID,页码,since_id三部分。其中每一页的since_id参数为上一页的起始id,保存在上一页中。(第一页没有since_id参数)
import pandas as pd
import requests
import json
# 设置基础参数
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:88.0) Gecko/20100101 Firefox/88.0',
'Cookie': 'your_cookie',
'Connection': 'keep-alive0'}
session = requests.Session()
# 爬取推文
def get_weibo(uid,id):
page = 1
# 进入博文界面
weibo_url = "https://weibo.com/ajax/statuses/mymblog?uid="+str(uid)+"&page="+str(page)+"&feature=0"
time.sleep(random.randint(1,4))
while 1:
try:
resp = session.get(weibo_url, headers=headers).content
resp = json.loads(resp)
since_id = resp["data"]["since_id"] # 记录since_id
weibo_list = resp["data"]["list"]
for weibo in weibo_list:
_time = time_change(weibo["created_at"]) # 记录时间
text = weibo["text_raw"].replace(',',',').replace('\n','') # 记录文本
tid = weibo["mblogid"] # 记录文本编号
like = weibo["attitudes_count"] # 记录点赞数
fp.writeline("{uid},{id},{text},{_time},{tid},{like}\n")
if (page>=199): # 爬到200页自动推出
return
page += 1
time.sleep(random.randint(1,2)/2)
weibo_url = "https://weibo.com/ajax/statuses/mymblog?uid="+str(uid)+"&page="+str(page)+"&since_id="+since_id
except:
time.sleep(random.randint(10, 15))
return
if __name__ =="__main__":
csv_name = "保存路径"
fp = open('csv_name','w',encoding='utf-8')
fp.writelines('user_id,id,text,_time,tid,like\n')
uid = "XXX"
id = "XXX" #输入用户的uid和id
get_weibo(uid, id)
4 Selenium与Request的优劣比较
| Request | Selenium | |
|---|---|---|
| 找网页 | 需要抓包,溯源与编程难度略大 | 模拟浏览器操纵,编程难度小 |
| 找链接 | 需要下载json进行解析 | 可以基于路径提取元素 |
| 模拟登录 | cookie登录 | 可扫码可cookie |
| 速度 | 相对快 | 相对慢 |
| 特殊形式 | 特殊形式的数据调取更方便(K线图) | 特殊形式的数据无法获取 |
| 多媒体 | 可直接下载图片 | 只能获取链接 |
| 使用人群 | 适合提高 | 适合入门 |
| 适用范围 | (1)大量微博与评论获取(速度快) (2)K线图等需要调取后台数据的爬虫 (3)下载图片、视频 |
(1)可见即可爬,适合无脑操作 (2)支持JS渲染网页读取 |
总而言之,request与selenium各有利弊,两者都有学习掌握的必要。selenium相对简单,界面友好编程方便,适合新手入门,request更适用于第二阶段的提高。
本文作者:奇思妙想张霁羊
本文链接:https://www.cnblogs.com/rachel0701/p/17913737.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步